爬取动漫美女,手把手教你用Python网络爬虫获取动漫图片
2021-03-15 01:28
标签:建立 交流群 错误 lang html term csdn http view
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于腾讯云 作者:砸漏 ( 想要学习Python?Python学习交流群:1039649593,满足你的需求,资料都已经上传群文件流,可以自行下载!还有海量最新2020python学习资料。 ) 之前有些无聊(呆在家里实在玩的腻了),然后就去B站看了一些python爬虫视频,没有进行基础的理论学习,也就是直接开始实战,感觉跟背公式一样的进行爬虫,也算行吧,至少还能爬一些东西,hhh。我今天来分享一个我的爬虫代码。 话不多说,直接上完整代码 ps:这个代码有些问题 每次我爬到fate的图片它就给我报错,我只好用个try来跳过了,如果有哪位大佬能帮我找出错误并给与纠正,我将不胜感激 先导入要使用的库 然后去分析要去爬的网址: https://www.acgimage.com/shot/recommend 下图是网址的内容: 下面去寻找headers 第一步就完成了 下面是代码展示 然后检索要爬的图片内容 然后用正则表达式re来检索就行了 最后将其保存就好了 还有就是一些细节了 比如换页 第一页网址: https://www.acgimage.com/shot/recommend 第二页网址:https://www.acgimage.com/shot/recommend?page=2 然后将page后面的数字改动就可以跳到相应的页面 换页的问题也就解决了 以及将爬到的图片放到自己建立的文件zh 使用了os库 以及为了不影响爬取的网站 使用了sleep函数 虽然爬取的速度慢了一些 但是这是应遵守的道德 以上 这就是我的爬虫过程 还是希望大佬能解决我的错误之处 万分感谢 爬取动漫美女,手把手教你用Python网络爬虫获取动漫图片 标签:建立 交流群 错误 lang html term csdn http view 原文地址:https://www.cnblogs.com/aa1273935919/p/14015453.html
引言
正文
import requests as r
import re
import os
import time
file_name = "动漫截图"
if not os.path.exists(file_name):
os.mkdir(file_name)
for p in range(1,34):
print("--------------------正在爬取第{}页内容------------------".format(p))
url = ‘https://www.acgimage.com/shot/recommend?page={}‘.format(p)
headers = {"user-agent"
: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
resp = r.get(url, headers=headers)
html = resp.text
images = re.findall(‘data-original="(.*?)" ‘, html)
names =re.findall(‘title="(.*?)"‘, html)
#print(images)
#print(names)
dic = dict(zip(images, names))
for image in images:
time.sleep(1)
print(image, dic[image])
name = dic[image]
#name = image.split(‘/‘)[-1]
i = r.get(image, headers=headers).content
try:
with open(file_name + ‘/‘ + name + ‘.jpg‘ , ‘wb‘) as f:
f.write(i)
except FileNotFoundError:
continue
import requests as r
import re
import os
import time
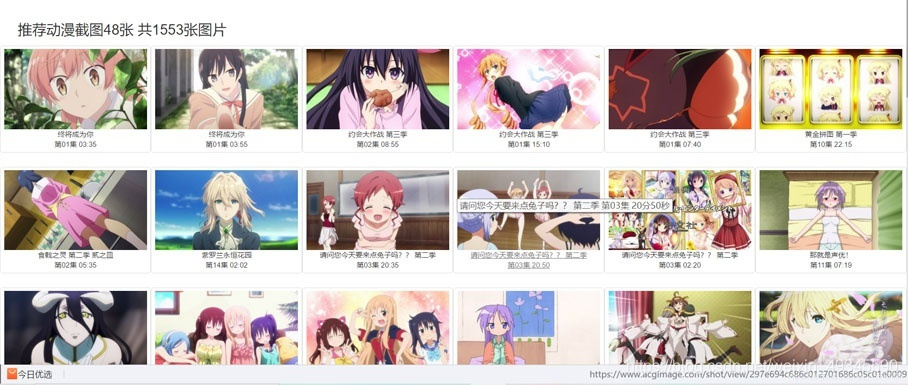
好了 url已经确定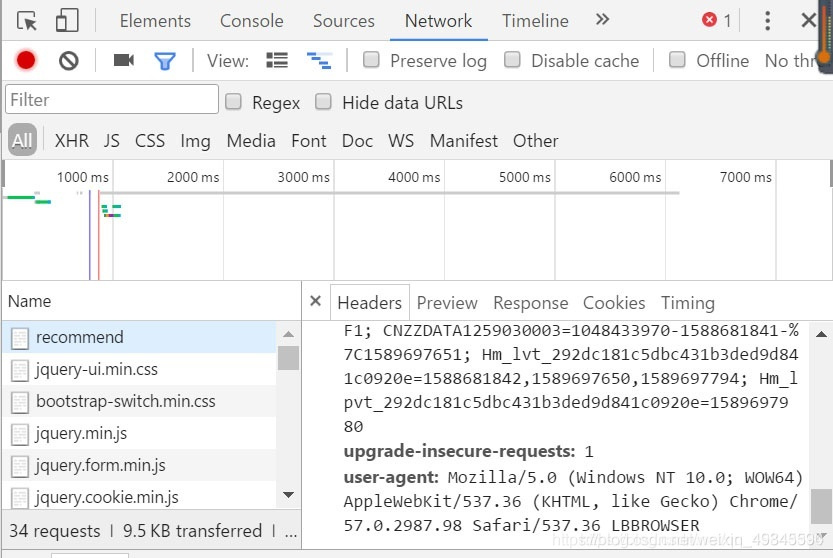
找到user-agent 将其内容复制到headers中url = ‘https://www.acgimage.com/shot/recommend?page={}‘.format(p)
headers = {"user-agent"
: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"
}

从上图就可以找到图片的位置:data-origina=后面的内容
以及图片的名字:title=后面的内容images = re.findall(‘data-original="(.*?)" ‘, html)
names =re.findall(‘title="(.*?)"‘, html)
i = r.get(image, headers=headers).content
with open(file_name + ‘/‘ + name + ‘.jpg‘ , ‘wb‘) as f:
f.write(i)
or p in range(1,34):
url = ‘https://www.acgimage.com/shot/recommend?page={}‘.format(p)
file_name = "动漫截图"
if not os.path.exists(file_name):
os.mkdir(file_name)
time.sleep(1)
文章标题:爬取动漫美女,手把手教你用Python网络爬虫获取动漫图片
文章链接:http://soscw.com/index.php/essay/64746.html