TENER: Adapting Transformer Encoder for Named Entity Recognition
2021-03-17 04:25
标签:transform 序列 product position src 基础 处理 作用 algo 论文地址:https://arxiv.org/abs/1911.04474 BiLSTMs结构在NLP的任务中广泛应用,最近,全连接模型Transformer大火,它的 self-attention 机制和强大的并行计算能力使其在众多模型中脱颖而出,但是,原始版本的 Transformer 在命名体识别(NER)中表现却不像在其他领域中那么好,本文将介绍一种叫 TENER 的模型,是在 Transformer 的基础上为 NER 任务改进的,既可以应用在 word-level,也可以应用在 character-level。通过使用位置感知的编码方式和被削减的attention,我们让 Transformer 在 NER 中达到了在其他任务中那样好的效果。 命名体识别是指,在一个句子中找到一个命名体的开始与结束位置,并且标注其特性,比如人名、地名、机构名等。NER 在问答、关系抽取和共指消解(coreference resolution)中都发挥了重要的作用。 NER 通常被视为序列标注任务,其网络结构一般包含三层:word-embedding层、编码层和解码层。NER 各种模型的不同之处主要在这些网络层中。 循环神经网络(RNNs)高度契合语言特性,所以在NLP的任务中使用广泛,其中,BiLSTM因为其对上下文的强大观察能力在NER中广泛使用。 最近,Transformer 模型也在NLP 任务中大放异彩,机器翻译、预训练模型中都可以看到它。Transformer 的编码器实现了一个大范围基于自注意力机制的全连接神经网络,这恰好是RNNs的局限,并且在并行计算上也远超过RNNs。然而,在NER任务中,Transformer 的表现并不好,本文将会探讨为什么有这样的结果,并提出一种改进方法。 总的来说,为了提高 Transformer 在NER 中的表现,我们使用了相对位置的位置编码,减少了注意力参数,将其变得相对稀疏。经过这些处理之后,模型表现甚至好过基于 BiLSTM 的模型,在六个NER数据集中,改模型在不考虑预训练的模型中达到了前所未有的效果。 BiLSTM-CRF常用在序列标注问题中,尽管其取得了巨大成功,每个单词还是要按顺序算,为了利用上 GPU 并行计算的能力,CNN也常常使用,为了解决CNN感知范围不足的问题,该领域使用了ID-CNN。BiLSTM和CNN都广泛应用在字符编码中。 NER中大部分也使用了与训练的word-embedding,使用ELMO等 contextual word embedding 后,模型有了更大程度的提高。 Transformer 是基于self-attention的sequence模型,由若干个编码器和解码器组成,每个编码器为全连接的self-attention 层接 Add & Layer Normalization,解码器与编码器基本相同,前面还有一个对已经得到的输出序列作 masked attention。相关内容可以看我在这里写的笔记。 本文中,我们使用Transformer的编码器来应对复杂的NER任务,其结构如下图所示。 为了解决数据稀疏和OOV,我们需要一个 character encoder,以前常用的是CNN和BiLSTM,现在我们选择使用Transformer的encoder结构来代替,这样既可以有效利用GPU,又能考虑上下文,甚至非连续的字符。 最终的word embedding 是将字符编码和预训练的词嵌入拼接在一起的。 下面提出对编码层做修改。 相比于Transformer,BiLSTM可以轻松知道两个词的左右顺序关系,但是Transformer 却不容易判断。下面我们证明 sinusoidal position embedding 的两条性质,从而说明这种编码方式缺乏对方向的认识。 对于偏置\(k\)和位置\(t\),\(PE_{t+k}^TPE_t\)只取决于\(k\),这说明两个位置向量的点积可以反映单词间距离。 证明: 其中\(d\)是位置编码的维度,\(c_i = \frac{1}{1000^{\frac{2i}{d}}}\)。因此 对于偏置\(k\)和位置\(t\),\(PE_t^T PE_{t-k}=PE_t^T PE_{t+k}\),这说明原本的位置编码是不能分别方向的。 证明: 令\(j=t-k\),由性质1,我们有 然而,当引入\(Q,K\)矩阵之后原本的距离感知也被削弱了,因为这时位置编码变成了\(PE_t^T W_q^TW_kPE_{t+k}=PE_t^T W PE_{t+k}\),这使得他们的距离不像原来那么明确。 因此,为了提高对距离和方向的认知能力,我们用下面的公式给注意力打分。 式中\(u,v\)为可学习的参数。通过计算我们有 通过观察可以看出,\(R_t\)与\(R_{-t}\)是不一样的。这样我们就能够表现距离和相对位置关系了。 在原始的模型中,\(K\)和\(Q\)的点积有一个\(\sqrt{d_k}\)作为分母,在NER任务中我们发现没有这个系数效果会更好。猜测原因是不加这部分会让注意力矩阵更加锐化,对于NER来说减小了噪声干扰,提高了准确率。 为了充分利用不同 tag 间的依赖关系,我们的模型中使用了条件随机场(CRF)。给定一个序列\(S=[s_1,s_2,\cdots s_T]\),对应的标签序列是\(y=[y_1,y_2,\cdots,y_T]\),\(Y(s)\)表示所有合法的标签序列。则序列为\(y\)的概率可以这样计算 其中\(f(y_{t-1}, y_t,s)\)计算转移概率。目标是最大化\(P(y|s)\),解码时可以使用 Viterbi Algorithm。 TENER: Adapting Transformer Encoder for Named Entity Recognition 标签:transform 序列 product position src 基础 处理 作用 algo 原文地址:https://www.cnblogs.com/TABball/p/12790362.htmlAbstract
Introduction
Related Work
Neural Architecture for NER
Transformer
Proposed Model
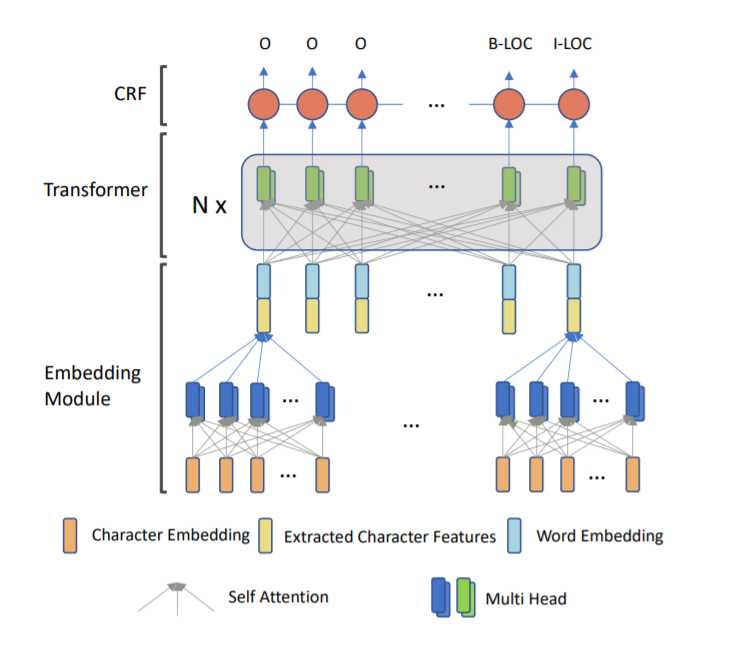
Embedding Layer
Encoding Layer with Adapted Transformer
Directional-and Distance-Aware Attention
Un-scaled Dot-Product Attention
CRF Layer
上一篇:在线Web漏扫测试环境
文章标题:TENER: Adapting Transformer Encoder for Named Entity Recognition
文章链接:http://soscw.com/index.php/essay/65149.html