java 实现跳表(skiplist)及论文解读
2021-03-18 09:26
标签:list 排序 nil rri 最快 upd 不能 href 慢慢 跳表由William Pugh发明。 他在论文 《Skip lists: a probabilistic alternative to balanced trees》中详细介绍了跳表的数据结构和插入删除等操作。 性能比较好。 实现相对于红黑树比较简单。 占用更少的内存。 为了学习第一手的资料,我们先学习一下论文,然后再结合网上的文章,实现一个 java 版本的 skip-list。 二叉树可用于表示抽象数据类型,例如字典和有序列表。 当元素以随机顺序插入时,它们可以很好地工作。某些操作序列(例如按顺序插入元素)产生了生成的数据结构,这些数据结构的性能非常差。 如果可以随机排列要插入的项目列表,则对于任何输入序列,树都将很好地工作。在大多数情况下,必须在线回答查询,因此随机排列输入是不切实际的。 平衡树算法会在执行操作时重新排列树,以保持一定的平衡条件并确保良好的性能。 skiplist是平衡树的一种概率替代方案。 通过咨询随机数生成器来平衡skiplist。尽管skiplist在最坏情况下的性能很差,但是没有任何输入序列会始终产生最坏情况的性能(就像枢轴元素随机选择时的快速排序一样)。 skiplist数据结构不太可能会严重失衡(例如,对于超过250个元素的字典,搜索所花费的时间超过预期时间的3倍的机会少于百万分之一)。类似于通过随机插入构建的搜索树,但不需要插入即可是随机的。 概率性地平衡数据结构比显式地保持平衡容易。 ps: 大部分程序员可以手写 skip-list,但是手写一个红黑树就要复杂的多。 对于许多应用程序,skiplist比树更自然地表示,这也导致算法更简单。 skiplist算法的简单性使其更易于实现,并且在平衡树和自调整树算法上提供了显着的恒定因子速度改进。 skiplist也非常节省空间。它们可以轻松配置为每个元素平均需要 4/3 个指针(甚至更少),并且不需要将平衡或优先级信息与每个节点一起存储。 对于一个linked list来说,如果要查找某个元素,我们可能需要遍历整个链表。 如果list是有序的,并且每两个结点都有一个指针指向它之后两位的结点(Figure 1b),那么我们可以通过查找不超过 如果每四个结点都有一个指针指向其之后四位的结点,那么只需要检查最多 如果所有的第(2^i)个结点都有一个指针指向其2^i之后的结点(Figure 1d),那么最大需要被检查的结点个数为 这种数据结构的查询效率很高,但是对它的插入和删除几乎是不可实现的(impractical)。 接下来看下论文中的一张图: 因为这样的数据结构是基于链表的,并且额外的指针会跳过中间结点,所以作者称之为跳表(Skip Lists)。 从图中可以看到, 跳跃表主要由以下部分构成: 表头(head):负责维护跳跃表的节点指针。 跳跃表节点:保存着元素值,以及多个层。 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。 表尾:全部由 NULL 组成,表示跳跃表的末尾。 本节提供了在字典或符号表中搜索,插入和删除元素的算法。 搜索操作将返回与所需的键或失败的键关联的值的内容(如果键不存在)。 插入操作将指定的键与新值相关联(如果尚未存在,则插入该键)。 Delete操作删除指定的密钥。 易于支持其他操作,例如“查找最小键”或“查找下一个键”。每个元素由一个节点表示,插入节点时,其级别是随机选择的,而不考虑元素的数量在数据结构中。 级别i节点具有i个前向指针,索引从1到i。 我们不需要在节点中存储节点的级别。级别以某个适当的常量MaxLevel进行上限。 list 的级别是列表中当前的最大级别(如果列表为空,则为1)。 列表的标题具有从一级到MaxLevel的前向指针。 标头的前向指针在高于列表的当前最大级别的级别上指向NIL 分配元素NIL并为其提供比任何合法密钥更大的密钥。 所有skiplist的所有级别均以NIL终止。 初始化一个新列表,以使列表的级别等于1,并且列表标题的所有前向指针都指向NIL 我们通过遍历不超过包含要搜索元素的节点的前向指针来搜索元素(图2)。 如果在当前的前向指针级别上无法再取得任何进展,则搜索将向下移动到下一个级别。 当我们无法在1级进行更多处理时,我们必须紧靠在包含所需元素的节点之前(如果它在列表中) 要插入或删除节点,我们只需进行搜索和拼接,如图3所示。 图4给出了插入和删除的算法。 保持向量更新,以便在搜索完成时(并且我们准备执行拼接),update [i]包含一个指向级别i或更高级别的最右边节点的指针,该指针位于插图位置的左侧 /删除。 如果插入生成的节点的级别大于列表的先前最大级别,则我们将更新列表的最大级别,并初始化更新向量的适当部分。 每次删除后,我们检查是否删除了列表的最大元素,如果删除了,请减小列表的最大级别。 最初,我们讨论了概率分布,其中一半的具有i指针的节点也具有i + 1指针。 为了摆脱魔术常数,我们说具有i指针的节点的一小部分也具有i + 1指针。 (对于我们最初的讨论,p = 1/2)。 通过与图5中等效的算法随机生成级别。 生成级别时不参考列表中元素的数量。 在用p = 1/2生成的16个元素的skiplist中,我们可能会遇到9个1级元素,3个2级元素,3个3级元素和1个14级元素(这是不太可能的,但是可以发生)。 我们应该如何处理呢? 如果我们使用标准算法并从14级开始搜索,我们将做很多无用的工作。 我们应该从哪里开始搜索? 我们的分析表明,理想情况下,我们将在期望 1/p 个节点的级别L处开始搜索。 当 L = log_(1/p)n 时,会发生这种情况。 由于我们将经常引用此公式,因此我们将使用 L(n) 表示 log_(1/p)n。 对于决定如何处理列表中异常大的元素的情况,有许多解决方案。 只需从列表中存在的最高级别开始搜索即可。 正如我们将在分析中看到的那样,n个元素列表中的最大级别明显大于 L(n) 的概率非常小。 从列表中的最高级别开始搜索不会给预期搜索时间增加一个很小的常数。 这是本文描述的算法中使用的方法 尽管一个元素可能包含14个指针的空间,但我们不需要全部使用14个指针。 我们可以选择仅使用 L(n) 级。 有很多方法可以实现此目的,但是它们都使算法复杂化并且不能显着提高性能,因此不建议使用此方法。 如果我们生成的随机级别比列表中的当前最大级别大一倍以上,则只需将列表中当前的最大级别再加上一个作为新节点的级别即可。 在实践中,从直观上看,此更改似乎效果很好。 但是,由于节点的级别不再是完全随机的,这完全破坏了我们分析结果算法的能力。 程序员可能应该随意实现它,而纯粹主义者则应避免这样做。 由于我们可以安全地将级别限制为 L(n),因此我们应该选择 MaxLevel = L(n)(其中N是skiplist中元素数量的上限)。 如果 p = 1/2,则使用 MaxLevel = 16适用于最多包含216个元素的数据结构。 ps: maxLevel 可以通过元素个数+P的值推导出来。 针对 P,作者的建议使用 p = 1/4。后面的算法分析部分有详细介绍,篇幅较长,感兴趣的同学可以在 java 实现之后阅读到。 我们无论看理论觉得自己会了,然而常常是眼高手低。 最好的方式就是自己写一遍,这样印象才能深刻。 我们可以认为跳表就是一个加强版本的链表。 所有的链表都需要一个节点 Node,我们来定义一下:
* 这个是什么?index 吗?
*
* @since 0.0.4
*/
int key;
/**
* 存放的元素
*/
E value;
/**
* 向前的指针
*
* 跳表是多层的,这个向前的指针,最多和层数一样。
*
* @since 0.0.4
*/
SkipListNode 事实证明,链表中使用 array 比使用 List 可以让代码变得简洁一些。 至少在阅读起来更加直,第一遍就是用 list 实现的,后来不全部重写了。 对比如下: 查询的思想很简单:我们从最高层开始从左向右找(最上面一层可以最快定位到我们想找的元素大概位置),如果 next 元素大于指定的元素,就往下一层开始找。 任何一层,找到就直接返回对应的值。 找到最下面一层,还没有值,则说明元素不存在。 ps: 网上的很多实现都是错误的。大部分都没有理解到 skiplist 查询的精髓。 若key不存在,则插入该key与对应的value;若key存在,则更新value。 如果待插入的结点的层数高于跳表的当前层数currentLevel,则更新currentLevel。 选择待插入结点的层数randomLevel: randomLevel只依赖于跳表的最高层数和概率值p。 算法在后面的代码中。 另一种实现方法为,如果生成的randomLevel大于当前跳表的层数currentLevel,那么将randomLevel设置为currentLevel+1,这样方便以后的查找,在工程上是可以接受的,但同时也破坏了算法的随机性。 其中 getRandomLevel 是一个随机生成 level 的方法。 个人感觉 skiplist 非常巧妙的一点就是利用随机达到了和平衡树类似的平衡效果。 不过也正因为随机,每次的链表生成的都不同。 删除特定的key与对应的value。 如果待删除的结点为跳表中层数最高的结点,那么删除之后,要更新currentLevel。 为了便于测试,我们实现一个输出跳表的方法。 日志如下: SkipList 是非常巧妙的一个数据结构,到目前为止,我还是不能手写红黑树,不过写跳表相对会轻松很多。给论文作者点赞! 下一节让我们一起 jdk 中的 ConcurrentSkipListSet 数据结构,感受下 java 官方实现的魅力。 希望本文对你有帮助,如果有其他想法的话,也可以评论区和大家分享哦。 各位极客的点赞收藏转发,是老马持续写作的最大动力! java 实现跳表(skiplist)及论文解读 标签:list 排序 nil rri 最快 upd 不能 href 慢慢 原文地址:https://blog.51cto.com/9250070/2546328
什么是跳跃表
跳表是一种可以用来代替平衡树的数据结构,跳表使用概率平衡而不是严格执行的平衡,因此,与等效树的等效算法相比,跳表中插入和删除的算法要简单得多,并且速度要快得多。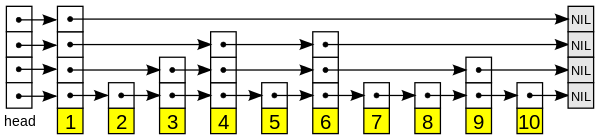
为什么需要?
论文解读
William Pugh
算法核心思想
?n/2?+1 个结点来完成查找。?n/4?+2 个结点(Figure 1c)。?log_n2?,代价仅仅是将需要的指针数量加倍。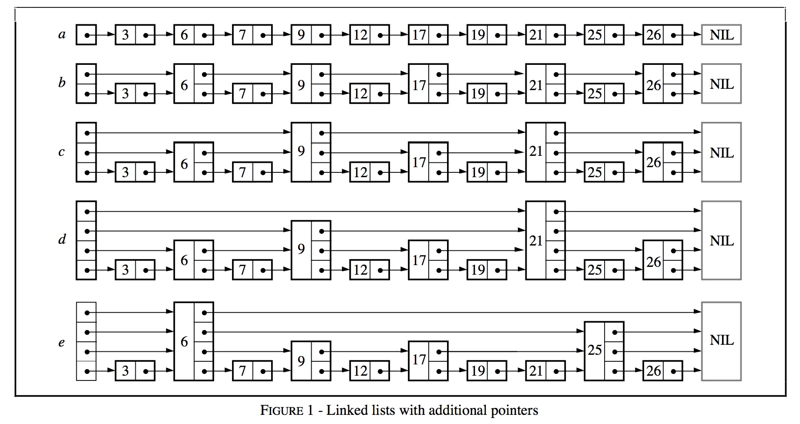
结构
skip-list 算法过程
初始化
搜索算法

插入和删除算法
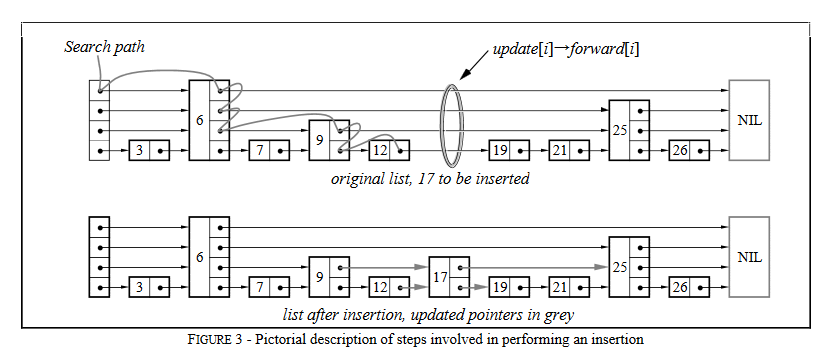

选择一个随机级别

我们从什么级别开始搜索?定义L(n)
别担心,要乐观些。
使用少于给定的数量。
修复随机性(dice)
确定MaxLevel
Java 实现版本
加深印象
节点定义
/**
* 元素节点
* @param newNode.forwards[i] = updates[i].forwards[i]; //数组
newNode.getForwards().get(i).set(i, updates.get(i).getForwards(i)); //列表查询实现
/**
* 执行查询
* @param searchKey 查找的 key
* @return 结果
* @since 0.0.4
* @author 老马啸西风
*/
public E search(final int searchKey) {
// 从左边最上层开始向右
SkipListNode插入
/**
* 插入元素
*
*
* @param searchKey 查询的 key
* @param newValue 元素
* @since 0.0.4
* @author 老马啸西风
*/
@SuppressWarnings("all")
public void insert(int searchKey, E newValue) {
SkipListNode/**
* 获取随机的级别
* @return 级别
* @since 0.0.4
*/
private int getRandomLevel() {
int lvl = 1;
//Math.random() 返回一个介于 [0,1) 之间的数字
while (lvl 删除
/**
* 删除一个元素
* @param searchKey 查询的 key
* @since 0.0.4
* @author 老马啸西风
*/
@SuppressWarnings("all")
public void delete(int searchKey) {
SkipListNode输出跳表
/**
* 打印 list
* @since 0.0.4
*/
public void printList() {
for (int i = currentLevel - 1; i >= 0; i--) {
SkipListNode测试
public static void main(String[] args) {
SkipListHEAD->(5,秤钩来买菜)->(6,口哨嘟嘟响)->NIL
HEAD->(1,铅笔细又长)->(2,小鸭水上漂)->(3,耳朵听声音)->(4,红旗迎风飘)->(5,秤钩来买菜)->(6,口哨嘟嘟响)->(7,镰刀来割草)->(8,麻花扭一扭)->(9,勺子能吃饭)->NIL
---------------
HEAD->(5,秤钩来买菜)->(6,口哨嘟嘟响)->NIL
HEAD->(1,铅笔细又长)->(2,小鸭水上漂)->(5,秤钩来买菜)->(6,口哨嘟嘟响)->(7,镰刀来割草)->(8,麻花扭一扭)->(9,勺子能吃饭)->NIL
麻花扭一扭小结

文章标题:java 实现跳表(skiplist)及论文解读
文章链接:http://soscw.com/index.php/essay/65718.html