TensorFlow基于Lenet模型手写数字识别
2021-03-18 10:24
标签:batch 迭代 默认 ted png nod 返回 oss add 手写识别较为简单的版本应该是只用FC,这样参考这篇博客. 本文卷积模型: 结果展示: TensorFlow基于Lenet模型手写数字识别 标签:batch 迭代 默认 ted png nod 返回 oss add 原文地址:https://www.cnblogs.com/gzr2018/p/12773464.html
Lenet-5模型: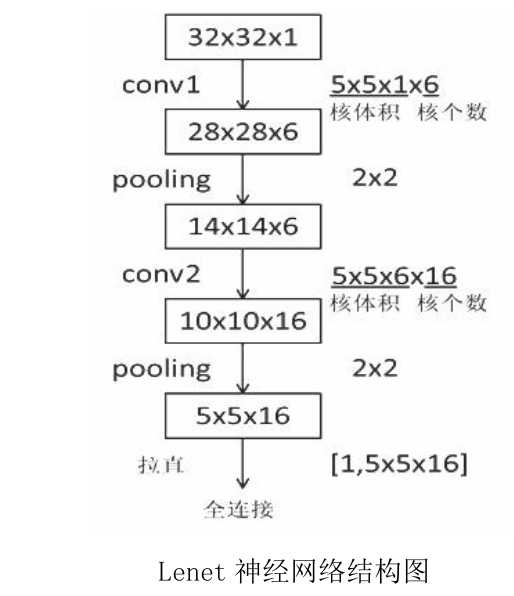
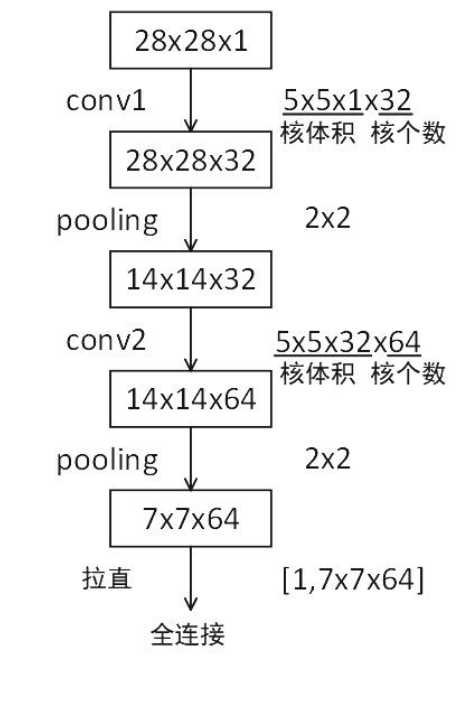
forward:
#coding:utf-8
import tensorflow as tf
import numpy as np
IMAGE_SIZE = 28
NUM_CHANNELS = 1
CONV1_SIZE = 5
CONV1_KERNEL_NUM = 32
CONV2_SIZE = 5
CONV2_KERNEL_NUM =64
FC_SIZE = 512
OUTPUT_NODE = 10
def get_weight(shape,regularizer):
#产生截断正态分布随机数,取值范围为 [ mean - 2 * stddev, mean + 2 * stddev ]
# (mean=0 stddev=1)。
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
#tf.add_to_collection(‘list_name’, element):
#将元素element添加到列表list_name中
#regularizer 是L2正则化乘上的系数,加入到losses列表中
if regularizer != None:tf.add_to_collection(‘losses‘,tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b = tf.Variable(tf.zeros(shape))
return b
#x输入描述,[batch,行分辨率,列分辨率,通道数]
#w卷积核描述,[行分辨率,列分辨率,通道数,核个数]
#核滑动步长,左右默认填1
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding=‘SAME‘)
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding=‘SAME‘)
def forward(x,train,regularizer):
conv1_w = get_weight([CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_KERNEL_NUM],
regularizer) # 初始化卷积核
conv1_b = get_bias([CONV1_KERNEL_NUM]) # 初始化偏置项
conv1 = conv2d(x, conv1_w) # 实现卷积运算
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
pool1 = max_pool_2x2(relu1) # 将激活后的输出进行最大池化
print("pool1‘size: ",pool1.get_shape())
conv2_w = get_weight([CONV2_SIZE, CONV2_SIZE, CONV1_KERNEL_NUM, CONV2_KERNEL_NUM], regularizer)
conv2_b = get_bias([CONV2_KERNEL_NUM])
conv2 = conv2d(pool1, conv2_w)
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
pool2 = max_pool_2x2(relu2)
#a.get_shape()中a的数据类型只能是tensor,且返回的是一个元组。
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool2,[pool_shape[0],nodes])
# 全连接层
fc1_w = get_weight([nodes,FC_SIZE],regularizer)
fc1_b = get_bias([FC_SIZE])
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_w)+fc1_b)
# 如果是训练阶段,
# 则对该层输出使用 dropout,也就是随机的将该层输出中的一半神经元置为无效,
# 是为了避免过拟合而设置的,一般只在全连接层中使用
if train:fc1 = tf.nn.dropout(fc1,0.5)
fc2_w = get_weight([FC_SIZE,OUTPUT_NODE],regularizer)
fc2_b = get_bias([OUTPUT_NODE])
y = tf.matmul(fc1,fc2_w)+fc2_b
return y
backward:
#coding:utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import numpy as np
import forward
# 定义训练过程中的超参数
BATCH_SIZE = 100 # 一个 batch 的数量
LEARNING_RATE_BASE = 0.005 # 初始学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
GEGULARIZER = 0.0001 # 正则化项的权重
STEPS = 50000 # 最大迭代次数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均的衰减率
MODEL_SAVE_PATH="./model/" # 保存模型的路径
MODEL_NAME="mnist_model" # 模型命名
def backward(mnist):
#x, y_是定义的占位符,需要指定参数的类型,维度(要和网络的输入与输出维度一致),类似
# 于函数的形参,运行时必须传入值
x = tf.placeholder(tf.float32,[
BATCH_SIZE,
forward.IMAGE_SIZE,
forward.IMAGE_SIZE,
forward.NUM_CHANNELS
])
y_ = tf.placeholder(tf.float32,[None,forward.OUTPUT_NODE])
y = forward.forward(x,True,GEGULARIZER)
global_step = tf.Variable(0,trainable=False)
#logits 为神经网络最后的输出,大小为[batch_size,output]
# 参数labels表示实际标签值,大小为[batch_size,output]
#第一步对网络最后输出做softmax,再将概率向量与实际标签向量做交叉熵
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection(‘losses‘)) # 加上w的损失
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 学习的滑动平均
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name=‘train‘)
saver = tf.train.Saver() # 实例化saver对象
with tf.Session() as sess:
init_op = tf.initialize_all_variables()
sess.run(init_op) # 执行训练过程
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
for i in range(STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(
BATCH_SIZE,
forward.IMAGE_SIZE,
forward.IMAGE_SIZE,
forward.NUM_CHANNELS
))
# 喂入训练图像和标签,开始训练
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
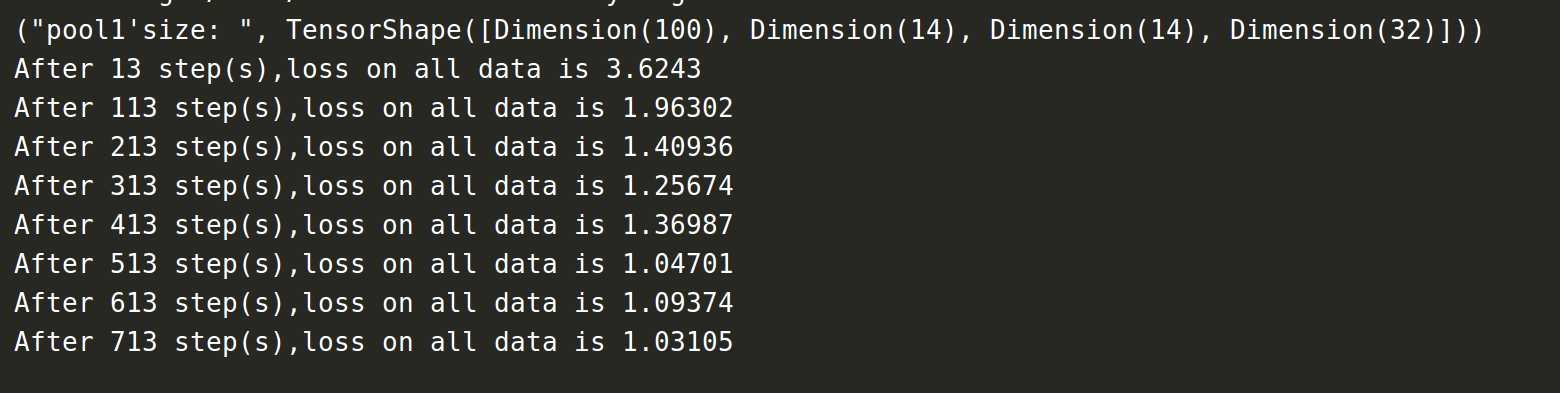
if i % 100 == 0:
print("After %d step(s),loss on all data is %g" % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
def main():
mnist = input_data.read_data_sets("./data/", one_hot=True)
backward(mnist)
if __name__ == ‘__main__‘:
main()
下一篇:PHP的基本语法—PHP标记
文章标题:TensorFlow基于Lenet模型手写数字识别
文章链接:http://soscw.com/index.php/essay/65732.html