50道Java集合经典面试题(收藏版)
2021-03-20 00:26
标签:val 性能 timsort lang length 容器 时移 mes cache 来了来了,50道Java集合面试题也来啦~ 已经上传github: https://github.com/whx123/JavaHome 可以从它们的底层数据结构、效率、开销进行阐述哈 Collection.sort是对list进行排序,Arrays.sort是对数组进行排序。 Collections.sort底层实现 Collections.sort方法调用了list.sort方法 Arrays的sort方法,如下: Timsort排序是结合了合并排序(merge.sort)和插入排序(insertion sort)而得出的排序方法; Queue队列中,poll() 和 remove() 都是从队列中取出一个元素,在队列元素为空的情况下,remove() 方法会抛出异常,poll() 方法只会返回 null 。 因为foreach删除会导致快速失败问题,fori顺序遍历会导致重复元素没删除,所以正确解法如下: 第二种,迭代器删除 数组是不能直接打印的哈,如下: 打印数组可以用流的方式Strem.of().foreach(),如下: 打印数组,最优雅的方式可以用这个APi,Arrays.toString() 如果在调用TreeMap的构造函数时没有指定比较器,则根据key执行自然排序。 Hashmap的扩容: 可以看一下HashSet的add方法,元素E作为HashMap的key,我们都知道HashMap的可以是不允许重复的,哈哈。 不是线性安全的。 线性安全的 线性不安全的 这个点,主要考察HashMap和TreeMap的区别。 TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按key的升序排序,也可以指定排序的比较器。当用Iterator遍历TreeMap时,得到的记录是排过序的。 List 转 Array 如果直接使用 toArray 无参方法,返回值只能是 Object[] 类,强转其他类型可能有问题,demo如下: 运行结果: 使用Arrays.asList() 把数组转换成集合时,不能使用修改集合相关的方法啦,如下: 运行结果如下: 因为 Arrays.asList不是返回java.util.ArrayList,而是一个内部类ArrayList。 方法如下: Iterator 主要是用来遍历集合用的,它的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。 很多朋友很可能想到用final关键字进行修饰,final修饰的这个成员变量,如果是基本数据类型,表示这个变量的值是不可改变的,如果是引用类型,则表示这个引用的地址值是不能改变的,但是这个引用所指向的对象里面的内容还是可以改变滴~验证一下,如下: 运行结果如下: 嘻嘻,那么,到底怎么确保一个集合不能被修改呢,看以下这三哥们~ 再看一下demo吧 运行结果: 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent 运行结果: 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。 运行结果: 其实,在java.util.concurrent 并发包的集合,如 ConcurrentHashMap, CopyOnWriteArrayList等,默认为都是安全失败的。 优先队列PriorityQueue是Queue接口的实现,可以对其中元素进行排序 方法: 特点: jdk8 放弃了分段锁而是用了Node锁,减低锁的粒度,提高性能,并使用CAS操作来确保Node的一些操作的原子性,取代了锁。 ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列,继承自AbstractBlockingQueue,间接的实现了Queue接口和Collection接口。底层以数组的形式保存数据(实际上可看作一个循环数组)。常用的操作包括 add ,offer,put,remove,poll,take,peek。 哈哈,看源码吧,是双向链表 ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。 为了能让HashMap存取高效,数据分配均匀。 可以看下我这篇文章哈~面试加分项-HashMap源码中这些常量的设计目的 聊到ConcurrenHashMap,需要跟面试官聊到安全性,分段锁segment,为什么放弃了分段锁,与及选择CAS,其实就是都是从效率和安全性触发,嘻嘻~ ArrayList 的默认大小是 10 个元素 可以用 Collections.sort()+ Comparator.comparing(),因为对对象排序,实际上是对对象的属性排序哈~ 这个跟之前那个不可变集合一样道理哈~ 在作为参数传递之前,使用Collections.unmodifiableCollection(Collection c)方法创建一个只读集合,这将确保改变集合的任何操作都会抛出UnsupportedOperationException。 看看它的add方法吧~ String、Integer等包装类的特性能够保证Hash值的不可更改性和计算准确性,能够有效的减少Hash碰撞的几率~ 重写hashCode()和equals()方法啦~ (这个答案来自互联网哈~) 其实这些点,结合平时工作,代码总结讲出来,更容易吸引到面试官呢 (这个答案来自互联网哈~) ArrayBlockingQueue: (有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。 元素重复与否是使用equals()方法进行判断的,这个可以跟面试官说说==和equals()的区别,hashcode()和equals 这道面试题,跟ArrayList,LinkedList,就是换汤不换药的~ 互联网上这个答案太详细啦(https://www.jianshu.com/p/939b8a672070) 因为ArrayList的底层是数组实现,并且数组的默认值是10,如果插入10000条要不断的扩容,耗费时间,所以我们调用ArrayList的指定容量的构造器方法ArrayList(int size) 就可以实现不扩容,就提高了性能。 看例子吧,哈哈,这个跟对象排序也是一样的呢~ 在 Java 7 中,ArrayList 的默认大小是 10 个元素,HashMap 的默认大小是16个元素(必须是2的幂)。 Hashmap解决hash冲突,使用的是链地址法,即数组+链表的形式来解决。put执行首先判断table[i]位置,如果为空就直接插入,不为空判断和当前值是否相等,相等就覆盖,如果不相等的话,判断是否是红黑树节点,如果不是,就从table[i]位置开始遍历链表,相等覆盖,不相等插入。 50道Java集合经典面试题(收藏版) 标签:val 性能 timsort lang length 容器 时移 mes cache 原文地址:https://blog.51cto.com/14989534/2547134
1. Arraylist与LinkedList区别
2. Collections.sort和Arrays.sort的实现原理

list.sort方法调用了Arrays.sort的方法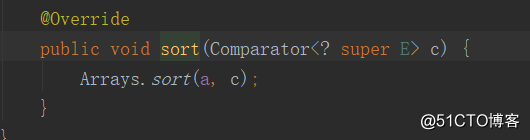
因此,Collections.sort方法底层就是调用的Array.sort方法Arrays.sort底层实现
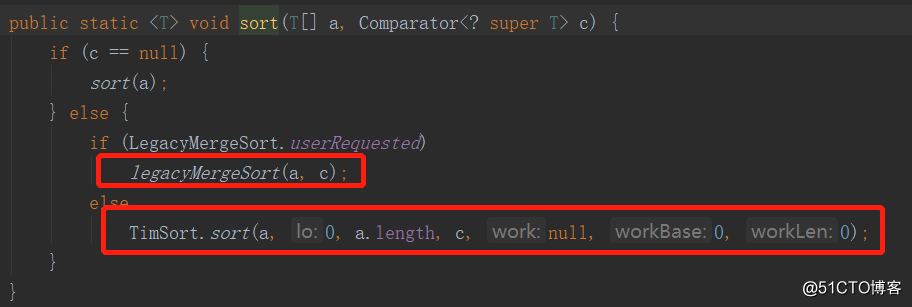
如果比较器为null,进入sort(a)方法。如下: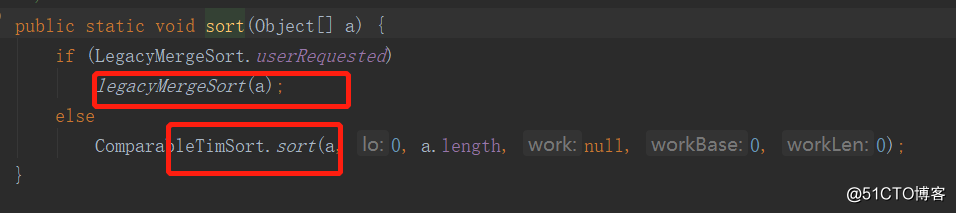
因此,Arrays的sort方法底层就是:
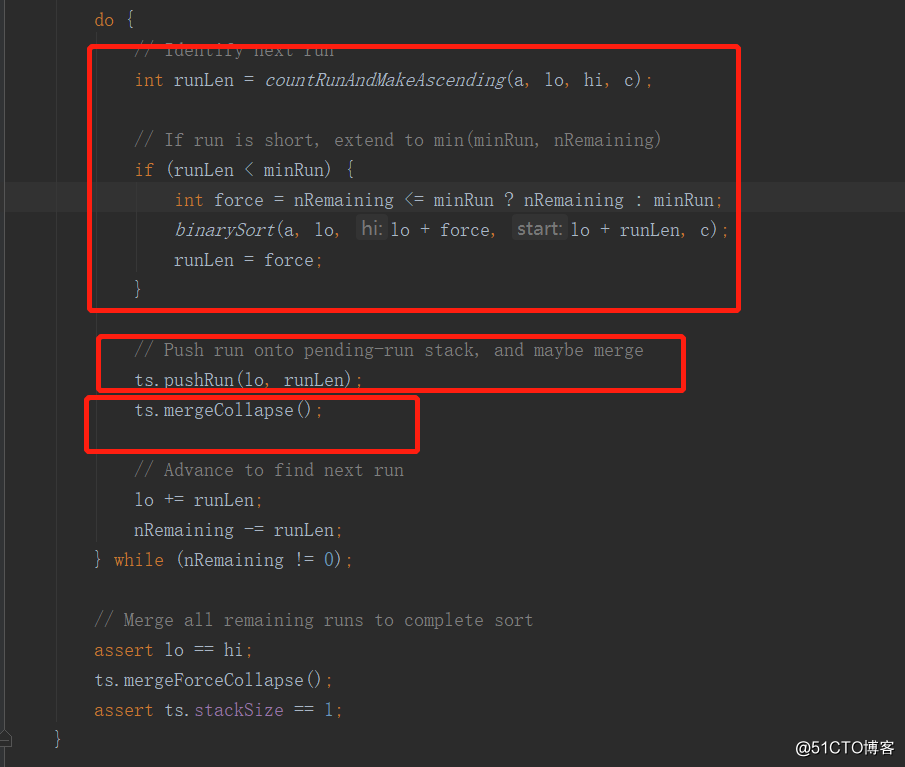
Timesort排序
1.当数组长度小于某个值,采用的是二分插入排序算法,如下: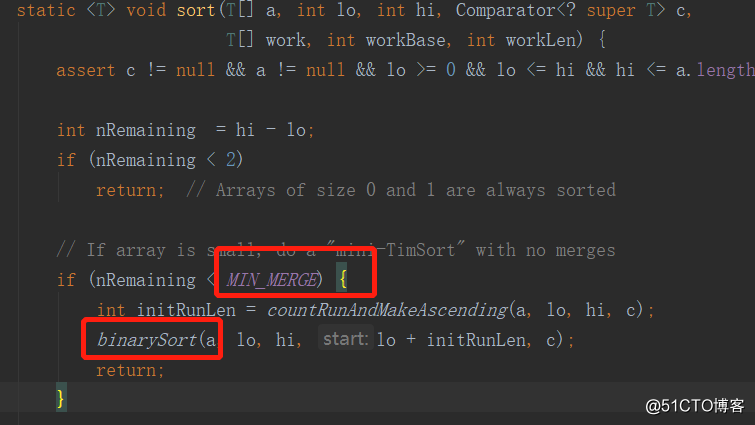

3. HashMap原理,java8做了什么改变
有关于HashMap这些常量设计目的,也可以看我这篇文章:面试加分项-HashMap源码中这些常量的设计目的4. List 和 Set,Map 的区别
5. poll()方法和 remove()方法的区别?
看一下源码的解释吧:/**
* Retrieves and removes the head of this queue. This method differs
* from {@link #poll poll} only in that it throws an exception if this
* queue is empty.
*
* @return the head of this queue
* @throws NoSuchElementException if this queue is empty
*/
E remove();
/**
* Retrieves and removes the head of this queue,
* or returns {@code null} if this queue is empty.
*
* @return the head of this queue, or {@code null} if this queue is empty
*/
E poll();
HashMap
HashTable
ConcurrentHashMap
7. 写一段代码在遍历 ArrayList 时移除一个元素
第一种遍历,倒叙遍历删除for(int i=list.size()-1; i>-1; i--){
if(list.get(i).equals("jay")){
list.remove(list.get(i));
}
}Iterator itr = list.iterator();
while(itr.hasNext()) {
if(itr.next().equals("jay") {
itr.remove();
}
}8. Java中怎么打印数组?
public class Test {
public static void main(String[] args) {
String[] jayArray = {"jay", "boy"};
System.out.println(jayArray);
}
}
//output
[Ljava.lang.String;@1540e19dpublic class Test {
public static void main(String[] args) {
String[] jayArray = {"jay", "boy"};
Stream.of(jayArray).forEach(System.out::println);
}
}
//output
jay
boypublic class Test {
public static void main(String[] args) {
String[] jayArray = {"jay", "boy"};
System.out.println(Arrays.toString(jayArray));
}
}
//output
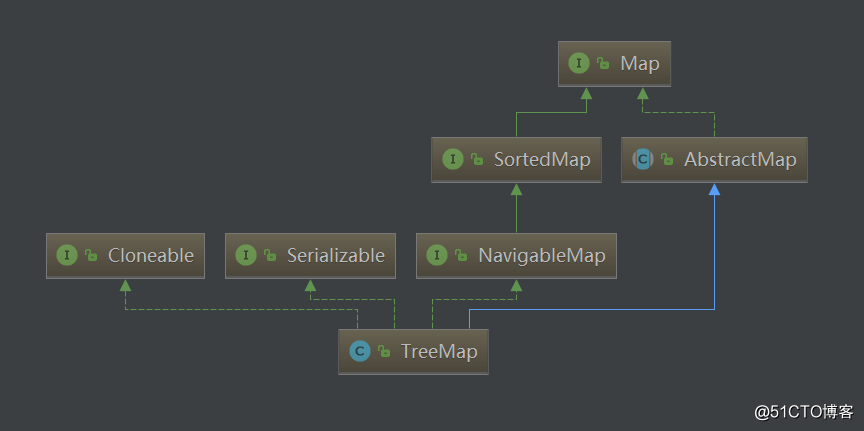
[jay, boy]9. TreeMap底层?
10. HashMap 的扩容过程
11. HashSet是如何保证不重复的
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}12. HashMap 是线程安全的吗,为什么不是线程安全的?死循环问题?
并发的情况下,扩容可能导致死循环问题。13. LinkedHashMap的应用,底层,原理
14. 哪些集合类是线程安全的?哪些不安全?
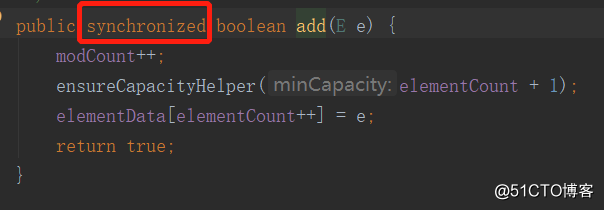
15. ArrayList 和 Vector 的区别是什么?
16. Collection与Collections的区别是什么?
public interface List
public static 17. 如何决定使用 HashMap 还是TreeMap?
18. 如何实现数组和 List之间的转换?
List 转Array,必须使用集合的 toArray(T[] array),如下:ListListException in thread "main" java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.String;
at Test.main(Test.java:14)Array 转List
String[] str = new String[] { "jay", "tianluo" };
List list = Arrays.asList(str);
list.add("boy");Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at Test.main(Test.java:13)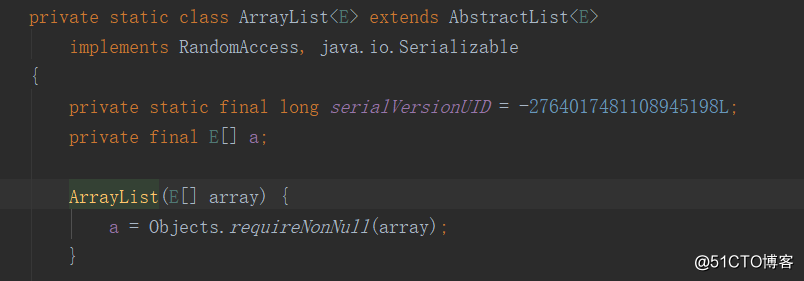
可以这样使用弥补这个缺点://方式一:
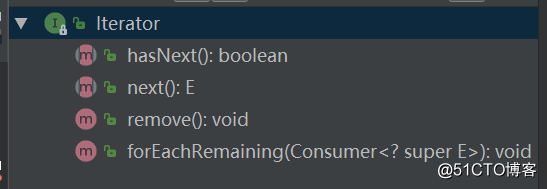
ArrayList arrayList = new ArrayList19. 迭代器 Iterator 是什么?怎么用,有什么特点?
public interface Collectionnext() 方法获得集合中的下一个元素
hasNext() 检查集合中是否还有元素
remove() 方法将迭代器新返回的元素删除
forEachRemaining(Consumer super E> action) 方法,遍历所有元素
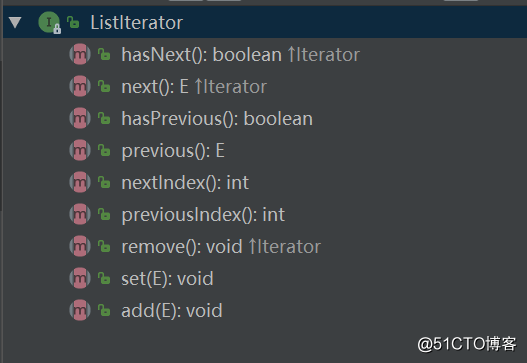
使用demo如下:List20. Iterator 和 ListIterator 有什么区别?
21. 怎么确保一个集合不能被修改?
public class Test {
//final 修饰
private static final Map//可以洗发现,final修饰,集合还是会被修改呢
boy
public class Test {
private static Map// 可以发现,unmodifiableMap确保集合不能修改啦,抛异常了
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.Collections$UnmodifiableMap.put(Collections.java:1457)
at Test.main(Test.java:14)
22. 快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
快速失败
Modification Exception。public class Test {
public static void main(String[] args) {
List1
Exception in thread "main" java.util.ConcurrentModificationException
3
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at Test.main(Test.java:12)安全失败
public class Test {
public static void main(String[] args) {
List1
list size:3
2
list size:423. 什么是Java优先级队列(Priority Queue)?
public class PriorityQueuepeek()//返回队首元素
poll()//返回队首元素,队首元素出队列
add()//添加元素
size()//返回队列元素个数
isEmpty()//判断队列是否为空,为空返回true,不空返回false
24. JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
可以跟面试官聊聊悲观锁和CAS乐观锁的区别,优缺点哈~25. 阻塞队列的实现,ArrayBlockingQueue的底层实现?
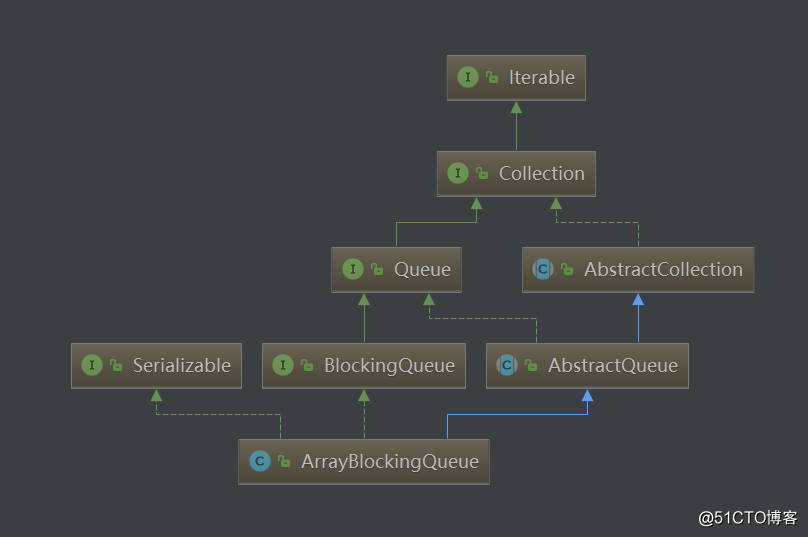
可以结合线程池跟面试官讲一下哦~26. Java 中的 LinkedList是单向链表还是双向链表?
private static class Node27. 说一说ArrayList 的扩容机制吧
public boolean add(E e) {
//扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//如果传入的是个空数组则最小容量取默认容量与minCapacity之间的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 如果最小需要空间比elementData的内存空间要大,则需要扩容
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 获取elementData数组的内存空间长度
int oldCapacity = elementData.length;
// 扩容至原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//校验容量是否够
if (newCapacity - minCapacity 0)
newCapacity = hugeCapacity(minCapacity);
// 调用Arrays.copyOf方法将elementData数组指向新的内存空间
//并将elementData的数据复制到新的内存空间
elementData = Arrays.copyOf(elementData, newCapacity);
}
28. HashMap 的长度为什么是2的幂次方,以及其他常量定义的含义~
看着呢,以下等式相等,但是位移运算比取余效率高很多呢~hash%length=hash&(length-1)29. ConcurrenHashMap 原理?1.8 中为什么要用红黑树?
java8不是用红黑树来管理hashmap,而是在hash值相同的情况下(且重复数量大于8),用红黑树来管理数据。
红黑树相当于排序数据。可以自动的使用二分法进行定位。性能较高。30. ArrayList的默认大小
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;31. 为何Collection不从Cloneable和Serializable接口继承?
32. Enumeration和Iterator接口的区别?
public interface Enumeration
33. 我们如何对一组对象进行排序?
public class Student {
private String name;
private int score;
public Student(String name, int score){
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student: " + this.name + " 分数:" + Integer.toString( this.score );
}
}
public class Test {
public static void main(String[] args) {
List34. 当一个集合被作为参数传递给一个函数时,如何才可以确保函数不能修改它?
35. 说一下HashSet的实现原理?
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}36. Array 和 ArrayList 有何区别?
37. 为什么HashMap中String、Integer这样的包装类适合作为key?
因为
38. 如果想用Object作为hashMap的Key?;
39. 讲讲红黑树的特点?
40. Java集合类框架的最佳实践有哪些?
41.谈谈线程池阻塞队列吧~
LinkedBlockingQueue: (可设置容量队列)基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newFixedThreadPool线程池使用了这个队列
DelayQueue:(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
PriorityBlockingQueue:(优先级队列)是具有优先级的***阻塞队列;
SynchronousQueue:(同步队列)一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。针对面试题:线程池都有哪几种工作队列?
我觉得,回答以上几种ArrayBlockingQueue,LinkedBlockingQueue,SynchronousQueue等,说出它们的特点,并结合使用到对应队列的常用线程池(如newFixedThreadPool线程池使用LinkedBlockingQueue),进行展开阐述, 就可以啦。
有兴趣的朋友,可以看看我的这篇文章哦~面试必备:Java线程池解析
42. HashSet和TreeSet有什么区别?
43. Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()?
44. 说出ArrayList,LinkedList的存储性能和特性
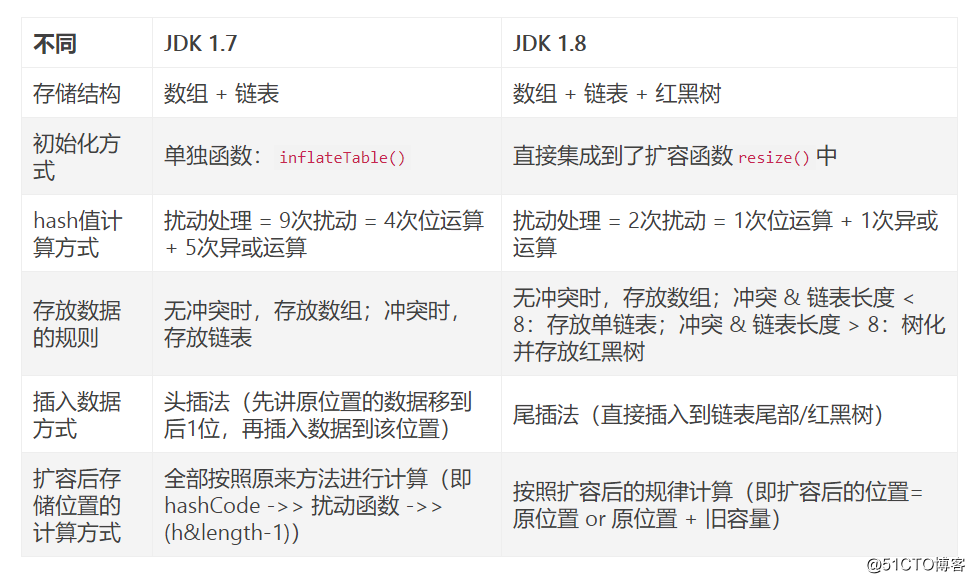
45. HashMap在JDK1.7和JDK1.8中有哪些不同?
46. ArrayList集合加入1万条数据,应该怎么提高效率
47. 如何对Object的list排序
public class Person {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
public class Test {
public static void main(String[] args) {
List48. ArrayList 和 HashMap 的默认大小是多数?
49. 有没有有顺序的Map实现类,如果有,他们是怎么保证有序的
50. HashMap是怎么解决哈希冲突的
个人公众号

上一篇:C++基础之C++编译调试
下一篇:SpringMVC常用注解
文章标题:50道Java集合经典面试题(收藏版)
文章链接:http://soscw.com/index.php/essay/66470.html