NODE JS实现原理
2021-03-20 19:27
标签:高性能 应用程序调用 pen 关注 多语言 一起 多用户 高效 mamicode Nodejs目前处境稍显尴尬,很多语言都已经拥有异步非阻塞的能力。阿里的思路是比较合适的,但是必须要注意,绝对不能让node做太多的业务逻辑,他只适合接收生成好的数据,然后或渲染后,或直接发送到客户端。 为什么nodejs 还可以成为主流技术哪? 是因为nodejs 对于大前端来说还是非常重要的技术!!!如果你理解nodejs 的编程原理,很容易就会理解angularjs,reactjs 和vuejs 的设计原理。 NodeJS Node是一个服务器端JavaScript解释器,用于方便地搭建响应速度快、易于扩展的网络应用。Node使用事件驱动,非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。 V8引擎 实际上,JavaScript引擎负责解释并执行代码。Google使用V8创建了一个用C++编写的超快解释器,该解释器拥有另一个独特特征;您可以下载该引擎并将其嵌入任何应用程序。V8 JavaScript引擎并不仅限于在一个浏览器中运行。 因此,Node实际上会使用Google编写的V8 JavaScript引擎,并将其重建为可在服务器上使用。 事件驱动 在我们使用Java,PHP等语言实现编程的时候,我们面向对象编程是完美的编程设计,这使得他们对其他编程方法不屑一顾。却不知大名鼎鼎Node使用的却是事件驱动编程的思想。那什么是事件驱动编程。 事件驱动模型主要包含3个对象:事件源、事件和事件处理程序。 ? 事件源:产生事件的地方(html元素) ? 事件:点击/鼠标操作/键盘操作等等 ? 事件对象:当某个事件发生时,可能会产生一个事件对象,该时间对象会封装好该时间的信息,传递给事件处理程序 ? 事件处理程序:响应用户事件的代码 运行原理 当我们搜索Node.js时,夺眶而出的关键字就是 “单线程,异步I/O,事件驱动”,应用程序的请求过程可以分为俩个部分:CPU运算和I/O读写,CPU计算速度通常远高于磁盘读写速度,这就导致CPU运算已经完成,但是不得不等待磁盘I/O任务完成之后再继续接下来的业务。 Node.js的单线程并不是真正的单线程,只是开启了单个线程进行业务处理(cpu的运算),同时开启了其他线程专门处理I/O。当一个指令到达主线程,主线程发现有I/O之后,直接把这个事件传给I/O线程,不会等待I/O结束后,再去处理下面的业务,而是拿到一个状态后立即往下走,这就是“单线程”、“异步I/O”。 优点 缺点 适合场景 这是适合 Node 的理想情况,因为您可以构建它来处理数万条连接。它仍然不需要大量逻辑;它本质上只是从某个数据库中查找一些值并将它们组成一个响应。由于响应是少量文本,入站请求也是少量的文本,因此流量不高,一台机器甚至也可以处理最繁忙的公司的 API 需求。 2、实时程序 比如聊天服务 聊天应用程序是最能体现 Node.js 优点的例子:轻量级、高流量并且能良好的应对跨平台设备上运行密集型数据(虽然计算能力低)。同时,聊天也是一个非常值得学习的用例,因为它很简单,并且涵盖了目前为止一个典型的 Node.js 会用到的大部分解决方案。 3、单页APP ajax很多。现在单页的机制似乎很流行,比如phonegap做出来的APP,一个页面包打天下的例子比比皆是。 总而言之,NodeJS适合运用在高并发、I/O密集、少量业务逻辑的场景 本来是想只做一个Nodejs运行原理-科普篇,但是收到了不少私信,要我多分享一些更进阶,更详细的内容,所以我会在接下来的两个月里继续更新Nodejs运行原理。 PS:此系列只做Nodejs的运行原理(架构,libuv,v8 etc),并不介绍Nodejs功能以及使用方法。 本文以两个view来看Nodejs的架构,一个是从模块依赖的角度,另一个是从函数调用的角度。 1.模块依赖 如上图所示:your code 为编辑代码,node.js 核心,Host environment 为宿主环境(提供各种服务,如文件管理,多线程,多进程,IO etc) 1.1node.js 这里重点介绍,nodejs组成部分:v8 engine, libuv, builtin modules, native modules以及其他辅助服务。 v8 engine:主要有两个作用 1.虚拟机的功能,执行js代码(自己的代码,第三方的代码和native modules的代码)。 2.提供C++函数接口,为nodejs提供v8初始化,创建context,scope等。 libuv:它是基于事件驱动的异步IO模型库,我们的js代码发出请求,最终由libuv完成,而我们所设置的回调函数则是在libuv触发。 builtin modules:它是由C++代码写成各类模块,包含了crypto,zlib, file stream etc 基础功能。(v8提供了函数接口,libuv提供异步IO模型库,以及一些nodejs函数,为builtin modules提供服务)。 native modules:它是由js写成,提供我们应用程序调用的库,同时这些模块又依赖builtin modules来获取相应的服务支持 简单总结一下:如果把nodejs看做一个黑匣子,起暴露给开发者的接口则是native modules,当我们发起请求时,请求自上而下,穿越native modules,通过builtin modules将请求传送至v8,libuv和其他辅助服务,请求结束,则从下回溯至上,最终调用我们的回调函数。 1.2your code 当我们执行node xxx.js的时候,node会先做一些v8初试化,libuv启动的工作,然后交由v8来执行native modules以及我们的js代码。 2.函数调用 这里我们以建立http server为例 如上图所示:v8执行js代码 server.listen()时,会通过一些基础服务到TCPWrap::listen(),TCPWrap是nodejs的內建模块,其通过libuv的api uv_listen()的方式,由libuv来完成异步调用。 图中1,2,3,4,5步骤标明了调用和返回的路径,这几步很快结束,留下callback TCPWrap::OnConnection()等着所需要的数据准备好后被调用。 libuv在得到所需要的请求后,会调用callback TCPWrap::OnConnection(),在该函数最后通过 tcp_wrap->MakeCallback(env->onconnection_string(), ARRAY_SIZE(argv), argv) 调用V8 engine中的JavaScript callback。 Node.js内建模块http其实是建立在模块net之上的。如果看net.js代码会发现,其通过 new TCP() 返回的类对象完成后续的TCP connect, bind, open等socket动作。 可以看到Node.js做的工作像是一座桥。左手V8,右手libuv,将2者有机连接在一起。例如HandleWrap::HandleWrap()中记录了V8 instance中的JavaScript对象以及TCPWrap对象。这样在TCPWrap::OnConnection()中可以拿到这两个对象,执行后续的callback调用。 NODE JS实现原理 标签:高性能 应用程序调用 pen 关注 多语言 一起 多用户 高效 mamicode 原文地址:https://www.cnblogs.com/chaosleo/p/12730950.html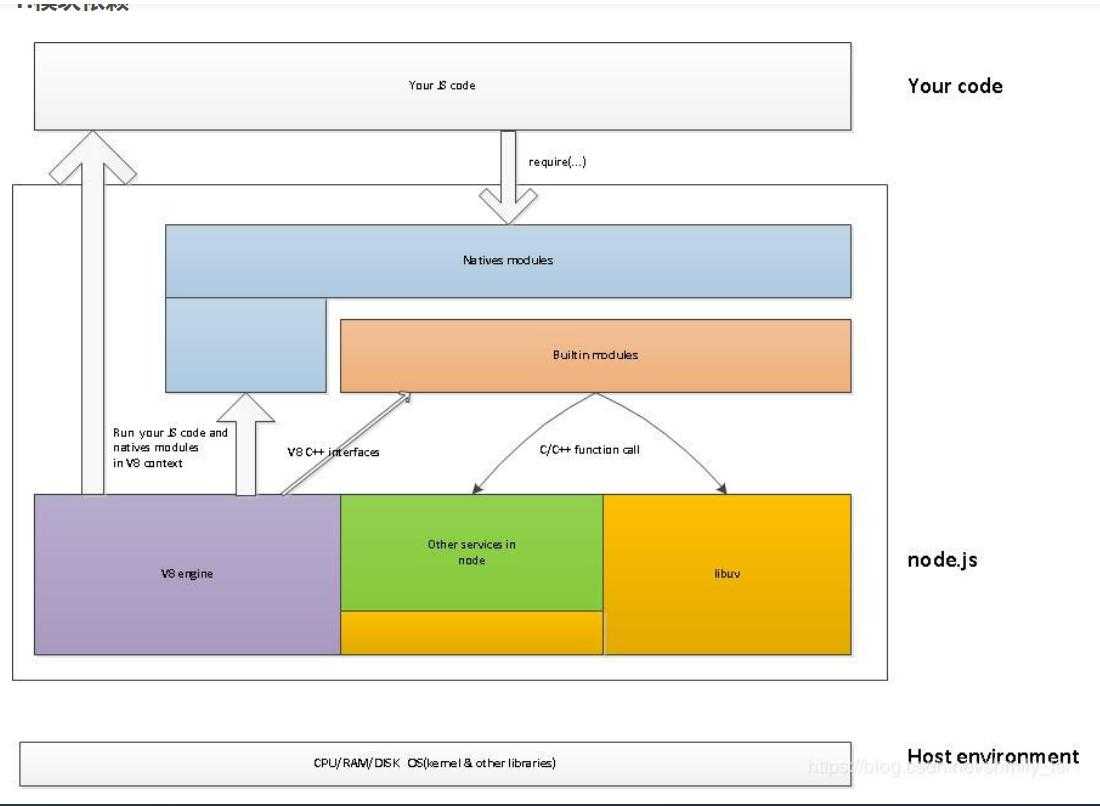
Node是一个可以让JavaScript运行在浏览器之外的平台。它实现了诸如文件系统、模块、包、操作系统 API、网络通信等Core JavaScript没有或者不完善的功能。历史上将JavaScript移植到浏览器外的计划不止一个,但Node.js 是最出色的一个。
V8 JavaScript引擎是Google用于其Chrome浏览器的底层JavaScript引擎。很少有人考虑JavaScript在客户机上实际做了些什么!
事件驱动编程,为需要处理的事件编写相应的事件处理程序。代码在事件发生时执行。
为需要处理的事件编写相应的事件处理程序。要理解事件驱动和程序,就需要与非事件驱动的程序进行比较。实际上,现代的程序大多是事件驱动的,比如多线程的程序,肯定是事件驱动的。早期则存在许多非事件驱动的程序,这样的程序,在需要等待某个条件触发时,会不断地检查这个条件,直到条件满足,这是很浪费cpu时间的。而事件驱动的程序,则有机会释放cpu从而进入睡眠态(注意是有机会,当然程序也可自行决定不释放cpu),当事件触发时被操作系统唤醒,这样就能更加有效地使用cpu。
来看一张简单的事件驱动模型(uml):
所以I/O才是应用程序的瓶颈所在,在I/O密集型业务中,假设请求需要100ms来完成,其中99ms化在I/O上。如果需要优化应用程序,让他能同时处理更多的请求,我们会采用多线程,同时开启100个、1000个线程来提高我们请求处理,当然这也是一种可观的方案。
但是由于一个CPU核心在一个时刻只能做一件事情,操作系统只能通过将CPU切分为时间片的方法,让线程可以较为均匀的使用CPU资源。但操作系统在内核切换线程的同时也要切换线程的上线文,当线程数量过多时,时间将会被消耗在上下文切换中。所以在大并发时,多线程结构还是无法做到强大的伸缩性。
那么是否可以另辟蹊径呢?!我们先来看看单线程,《深入浅出Node》一书提到 “单线程的最大好处,是不用像多线程编程那样处处在意状态的同步问题,这里没有死锁的存在,也没有线程上下文切换所带来的性能上的开销”,那么一个线程一次只能处理一个请求岂不是无稽之谈,先让我们看张图:
I/O操作完之后呢?Node.js的I/O 处理完之后会有一个回调事件,这个事件会放在一个事件处理队列里头,在进程启动时node会创建一个类似于While(true)的循环,它的每一次轮询都会去查看是否有事件需要处理,是否有事件关联的回调函数需要处理,如果有就处理,然后加入下一个轮询,如果没有就退出进程,这就是所谓的“事件驱动”。这也从Node的角度解释了什么是”事件驱动”。
在node.js中,事件主要来源于网络请求,文件I/O等,根据事件的不同对观察者进行了分类,有文件I/O观察者,网络I/O观察者。事件驱动是一个典型的生产者/消费者模型,请求到达观察者那里,事件循环从观察者进行消费,主线程就可以马不停蹄的只关注业务不用再去进行I/O等待。
Node 公开宣称的目标是 “旨在提供一种简单的构建可伸缩网络程序的方法”。我们来看一个简单的例子,在 Java和 PHP 这类语言中,每个连接都会生成一个新线程,每个新线程可能需要 2 MB 的配套内存。在一个拥有 8 GB RAM 的系统上,理论上最大的并发连接数量是 4,000 个用户。随着您的客户群的增长,如果希望您的 Web 应用程序支持更多用户,那么,您必须添加更多服务器。所以在传统的后台开发中,整个 Web 应用程序架构(包括流量、处理器速度和内存速度)中的瓶颈是:服务器能够处理的并发连接的最大数量。这个不同的架构承载的并发数量是不一致的。
而Node的出现就是为了解决这个问题:更改连接到服务器的方式。在Node 声称它不允许使用锁,它不会直接阻塞 I/O 调用。Node在每个连接发射一个在 Node 引擎的进程中运行的事件,而不是为每个连接生成一个新的 OS 线程(并为其分配一些配套内存)。
如上所述,nodejs的机制是单线程,这个线程里面,有一个事件循环机制,处理所有的请求。在事件处理过程中,它会智能地将一些涉及到IO、网络通信等耗时比较长的操作,交由worker threads去执行,执行完了再回调,这就是所谓的异步IO非阻塞吧。但是,那些非IO操作,只用CPU计算的操作,它就自己扛了,比如算什么斐波那契数列之类。它是单线程,这些自己扛的任务要一个接着一个地完成,前面那个没完成,后面的只能干等。因此,对CPU要求比较高的CPU密集型任务多的话,就有可能会造成号称高性能,适合高并发的node.js服务器反应缓慢。
1、RESTful API