Python3网页爬取
2021-03-27 06:27
标签:parse opened ror 服务 end book class 根据 == 有些服务器会拒绝非浏览器查看内容,此时需要添加headers参数,将爬虫程序伪装成浏览器 地址:chrome://version/ Python3网页爬取 标签:parse opened ror 服务 end book class 根据 == 原文地址:https://www.cnblogs.com/blue-lin/p/12153291.html常见问题
urllib.error.HTTPError: HTTP Error 403: Forbidden
Chrome版本信息
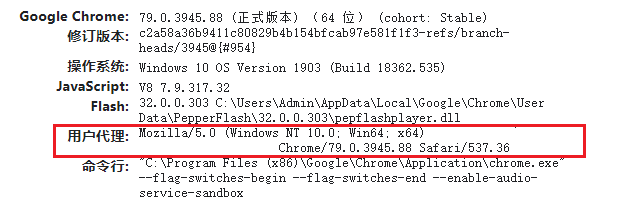


1 # coding: utf-8
2 import urllib #用urllib库进行页面爬取
3 from urllib.request import urlopen,Request #用request进行页面有关的操作
4 from bs4 import BeautifulSoup as bs
5 import chardet #查看页面的编码类型
6 from openpyxl import workbook # 写入Excel表所用
7 from openpyxl import load_workbook # 读取Excel表所用
8 import os
9 os.chdir(‘C:\Users\Admin\Desktop‘) # 更改工作目录为桌面
10
11 # 爬取网页
12 def getHtml(address, headers)
13 url = Request(url=address, headers=headers)
14 html = urlopen(url).read()
15 #charset = chardet.detect(html) #查看编码类型
16 #print(charset) #打印编码类型
17 html = html.decode(‘utf-8‘)
18 return html
19
20 def getTable(html)
21 soup = bs(html, ‘html.parser‘) # 将读取到的网页代码用指定解析器html.parser进行解析
22 tables = soup.find_all(‘div‘)
23
24 if __name__ == ‘__main__‘:
25 # 读取存在的Excel表测试
26 # wb = load_workbook(‘test.xlsx‘) #加载存在的Excel表
27 # a_sheet = wb.get_sheet_by_name(‘Sheet1‘) #根据表名获取表对象
28 # for row in a_sheet.rows: #遍历输出行数据
29 # for cell in row: #每行的每一个单元格
30 # print cell.value,
31
32 # 创建Excel表并写入数据
33 wb = workbook.Workbook() # 创建Excel对象
34 ws = wb.active # 获取当前正在操作的表对象
35 # 往表中写入标题行,以列表形式写入!
36 ws.append([‘信息页‘, ‘公司名称‘, ‘主营产品‘, ‘联系人‘, ‘电话‘])
37 headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/79.0.3945.88 Safari/537.36‘}
38 address = ‘http://b2b.huangye88.com/wuxi/zhuangxiuzhuangshi9586/pn2/‘
39 html = getHtml(address, headers)
40 getTable(html)