PySpark基于Python的Spark企业级大数据分析,以实际数据分析为驱动讲解
2021-03-27 09:25
标签:类型 调度 模块 name park https 空格 执行 移除 Python3实战Spark大数据分析及调度 学习资源 一、实例分析 二、代码解析 2.1.2 reduce() 语法 参数 参数 实例 四、实例 小练 PySpark基于Python的Spark企业级大数据分析,以实际数据分析为驱动讲解 标签:类型 调度 模块 name park https 空格 执行 移除 原文地址:https://www.cnblogs.com/spark356/p/13665743.html
1.1 数据 student.txt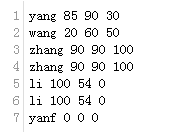
1.2 代码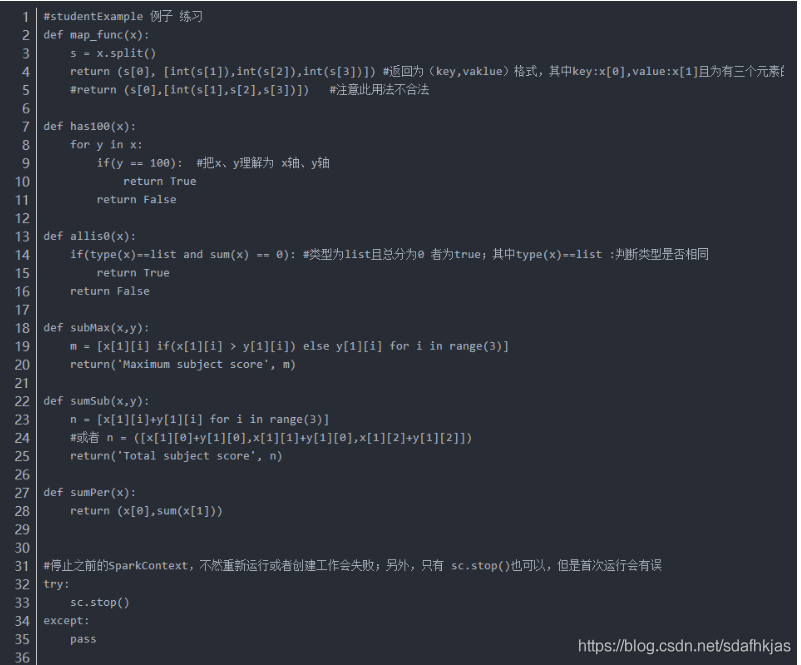
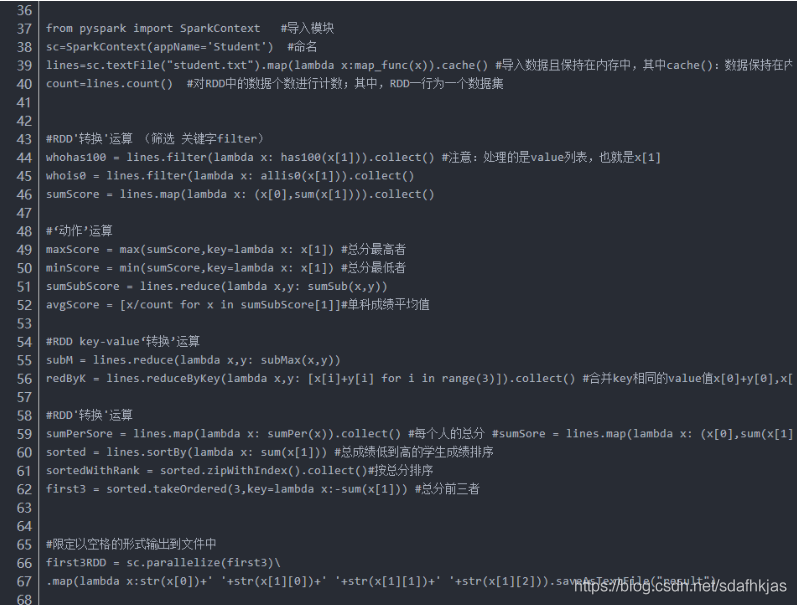
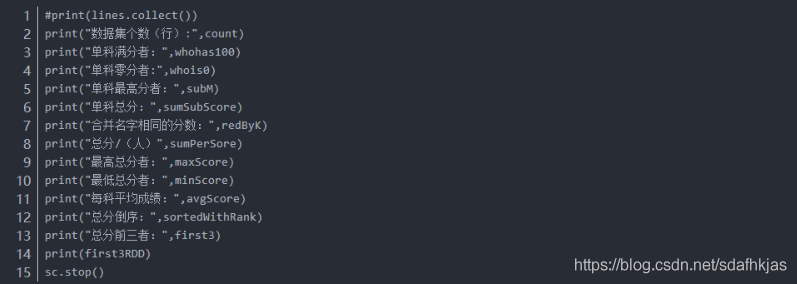
2.1函数解析
2.1.1 collect()
RDD的特性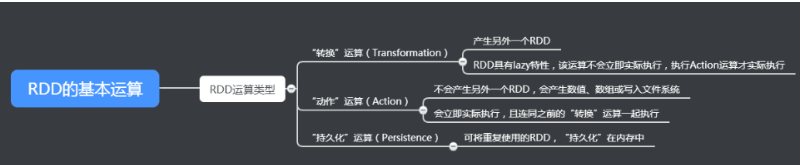 在进行基本RDD“转换”运算时不会立即执行,结果不会显示在显示屏中,collect()是一个“动作”运算,会立刻执行,显示结果。
在进行基本RDD“转换”运算时不会立即执行,结果不会显示在显示屏中,collect()是一个“动作”运算,会立刻执行,显示结果。
说明
reduce()函数会对参数序列中的元素进行累积。
reduce(function, iterable[, initializer])
function – 函数,有两个参数
iterable – 可迭代对象
initializer – 可选,初始参数
实例
说明:Python3的内建函数移除了reduce函数,reduce函数放在functools模块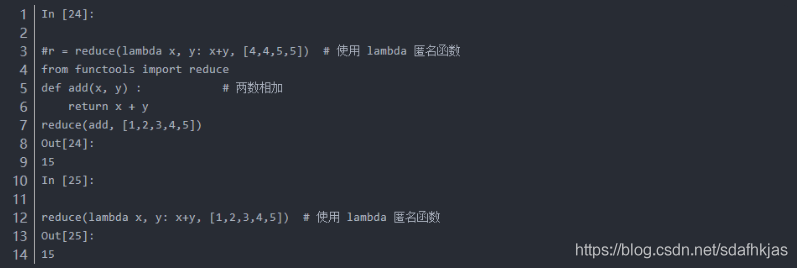
2.1.3 type()
语法
class type(name, bases, dict)
name – 类的名称。
bases – 基类的元组。
dict – 字典,类内定义的命名空间变量。
返回值
一个参数返回对象类型, 三个参数,返回新的类型对象。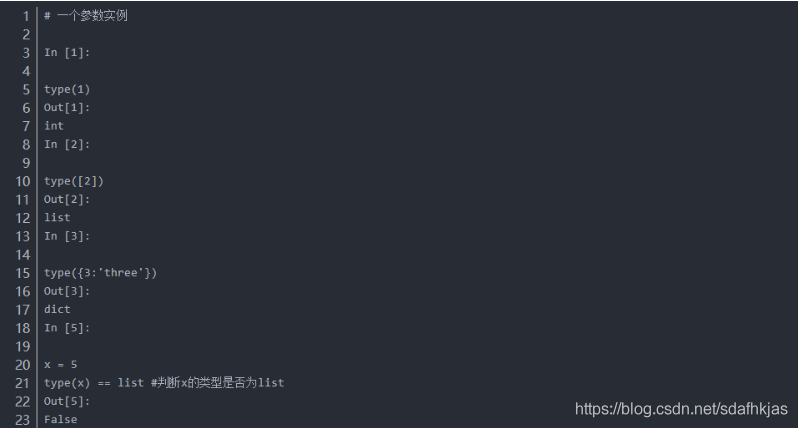

三、问题分析
解析
1、检查拼写是否有误
2、检查缩进是否合规
3、检查()是否一一配对
4.1 数据 user_small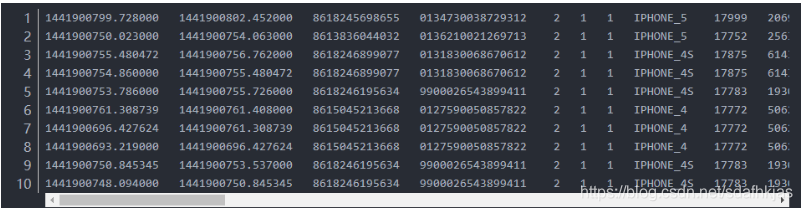
4.2 用户上网记录统计(一行为一条记录).(用户:第3列)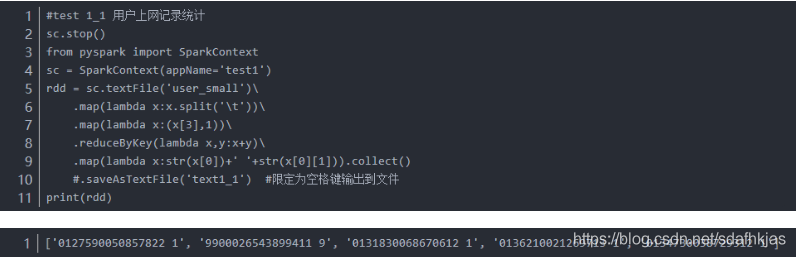
4.2用户流量统计。分别统计上行流量及下行流量并将结果各列以空格键隔开输出到文件。(用户:第3列;上行流量:第25列;下行流量:第26列)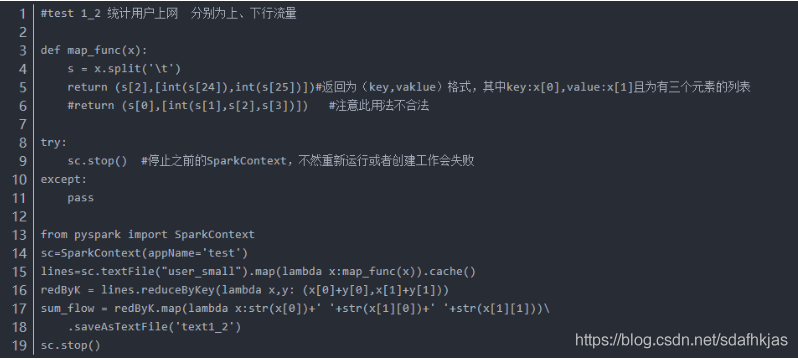
4.3 统计用户总流量
4.4、微信APP流量统计。(微信APP特征MicroMessenger,位于第20列,统计对应的下行流量值——第26列的数值。)
文章标题:PySpark基于Python的Spark企业级大数据分析,以实际数据分析为驱动讲解
文章链接:http://soscw.com/index.php/essay/68510.html