Java面试炼金系列 (1) | 关于String类的常见面试题剖析
2021-03-27 12:28
标签:整数 数据 答案 long stringbu search 可重复 才有 对象类型 文章以及源代码已被收录到:https://github.com/mio4/Java-Gold Java中的数据类型分为基本数据类型和引用数据类型: 举例说明: 运行上面的代码,可以得到以下结果: 可以看到str1和str2的内存地址都是 但是str3和str4的地址是不同的,所以判断为 在Java语言中,所有类都是继承于 可以看得出,这个方法很简单,就是比较对象的内存地址的。所以在对象没有重写这个方法时,默认使用此方法,即比较对象的内存地址值。但是类似于String、Integer等类均已重写了 很明显,String的equals()方法仅仅是对比它的 数据值,而不是对象的 内存地址 。 以 测试输出为如下,可以看出 Java中的集合(Collection)有三类,一类是List,一类是Queue,集合内的元素是有序的,元素可以重复;再有一类就是Set,一个集合内的元素无序,但元素不可重复。 前提: 谈到hashCode就不得不说equals方法,二者均是Object类里的方法。由于Object类是所有类的基类,所以一切类里都可以重写这两个方法。 总结来说,需要注意的是: 核心解释: ? 1.为了实现字符串池 ? 2.为了线程安全 ? 3.为了实现String可以创建HashCode不可变性 前者在常量池l中开辟一个常量,并返回相应的引用,而后者是在堆中开辟一个常量,再返回相应的对象。所以,两者的reference肯定是不同的: 而常量池中的常量是可以被共享用于节省内存开销和创建时间的开销(这也是引入常量池的原因),例如: 结合这两者,其实还可以回答另外一个常见的面试题目: 这句话创建了几个对象? 首先毫无疑问, 需要注意的是,如果在这个函数被调用前的别的地方,已经有了 String是不可变类,一旦创建了String对象,我们就无法改变它的值。因此,它是线程安全的,可以安全地用于多线程环境中。 因为字符串是不可变的,当创建字符串时,它的它的hashcode被缓存下来,不需要再次计算。因为HashMap内部实现是通过key的hashcode来确定value的存储位置,所以相比于其他对象更快。这也是为什么我们平时都使用String作为HashMap对象。 示例: 回顾到最开始的第一部分,为什么要引入 于是,如果引入了 关于上述代码的解释: s1会在常量池中创建,s2先查看常量池中有没有,如果有的话就指向它,如果没有就在常量池中创建一个然后指向它。所以s1和s2的两种比较是相同的。 答案是3个对象. 第一,行1 字符串池中的“hello”对象。 第二,行1,在堆内存中带有值“hello”的新字符串。 第三,行2,在堆内存中带有“hello”的新字符串。这里“hello”字符串池中的字符串被重用。 https://blog.csdn.net/justloveyou_/article/details/52464440 https://www.jianshu.com/p/875a3d2b5690 https://www.jianshu.com/p/9c7f5daac283 Java面试炼金系列 (1) | 关于String类的常见面试题剖析 标签:整数 数据 答案 long stringbu search 可重复 才有 对象类型 原文地址:https://www.cnblogs.com/Hooooober/p/13661843.htmlJava面试炼金系列 (1) | 关于String类的常见面试题剖析

0x0 基础知识
1. ‘==‘ 运算符
byte、short、int、long
float、double
char
boolean
== 比较的是它们的值== 比较的是它们在内存中存放的地址(堆内存地址) public static void main(String[] args) {
//基本数据类型
int num1 = 100;
int num2 = 100;
System.out.println("num1 == num2 : " + (num1 == num2) + "\n");
//引用类型,其中‘System.identityHashCode‘可以理解为打印对象地址
String str1 = "mio4";
String str2 = "mio4";
System.out.println("str1 address : " + System.identityHashCode(str1));
System.out.println("str2 address : " + System.identityHashCode(str1));
System.out.println("str1 == str2 : " + (str1 == str2) + "\n");
String str3 = new String("mio4");
String str4 = new String("mio4");
System.out.println("str3 address : " + System.identityHashCode(str3));
System.out.println("str4 address : " + System.identityHashCode(str4));
System.out.println("str3 == str4 : " + (str3 == str4));
}
num1 == num2 : true
str1 address : 1639705018
str2 address : 1639705018
str1 == str2 : true
str3 address : 1627674070
str4 address : 1360875712
str3 == str4 : false
1639705018,所以使用==判断为true,false。2. equals()方法
2.1 Object类equals()
Object这个超类的,在这个类中也有一个equals()方法,那么我们先来看一下这个方法。
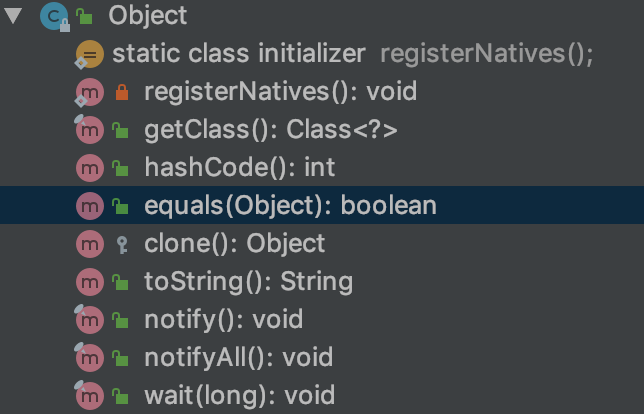
equals()。下面以String为例。2.2 String类equals()
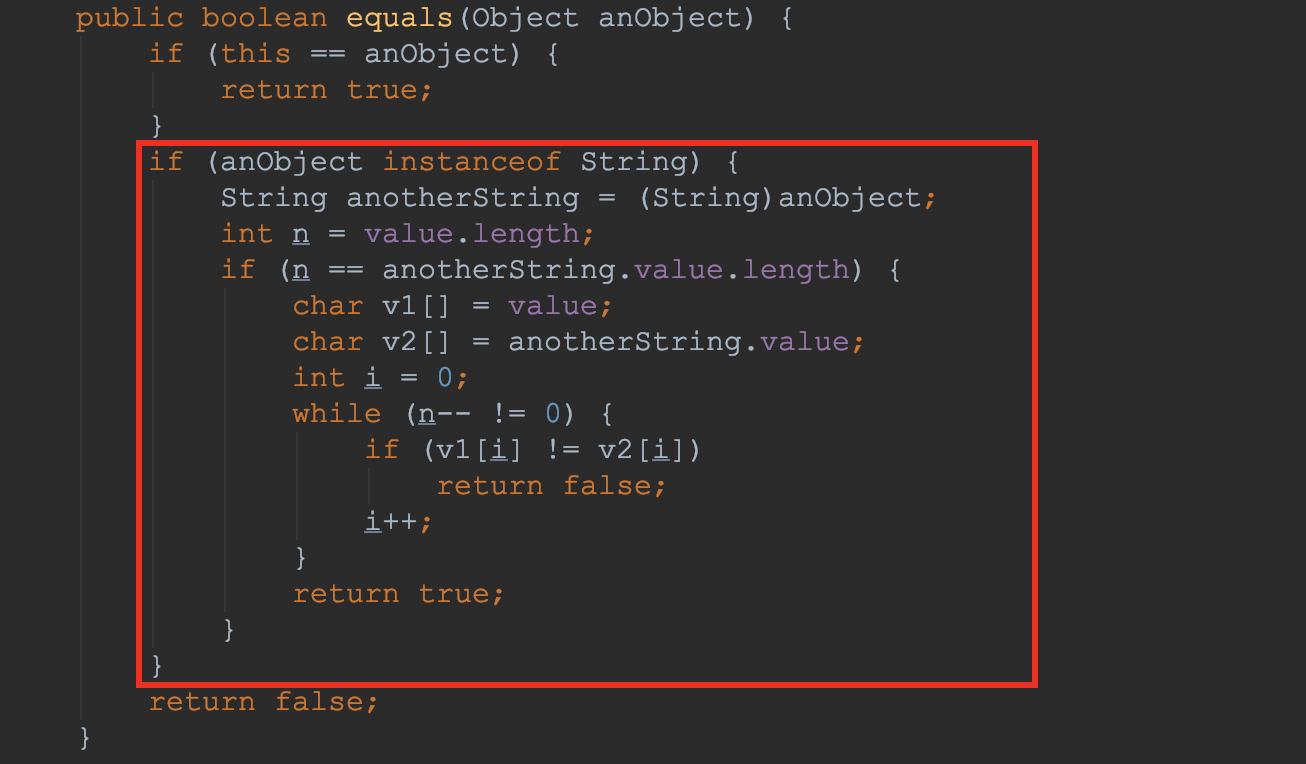
String 为例测试一下:public static void main(String[] args) {
String str1 = "mio4";
String str2 = "mio4";
String str3 = new String("mio4");
String str4 = new String("mio4");
System.out.println("str1 address : " + System.identityHashCode(str1));
System.out.println("str2 address : " + System.identityHashCode(str1));
System.out.println("str1.equals(str2) : " + str1.equals(str2) + "\n");
System.out.println("str3 address : " + System.identityHashCode(str3));
System.out.println("str4 address : " + System.identityHashCode(str4));
System.out.println("str3.equals(str4) : " + str3.equals(str4) + "\n");
}
str3和str4地址不同,但是因为String字符串内容相同,所以equals判断为truestr1 address : 1639705018
str2 address : 1639705018
str1.equals(str2) : true
str3 address : 1627674070
str4 address : 1360875712
str3.equals(str4) : true
3. hashCode()方法
3.1 为啥有这个方法?使用场景
3.2 hashCode()和equals()关联
0x1 高频面试题
1. 看过String源码吗?为啥用final修饰?
public final class String
implements java.io.Serializable, Comparable
2. String有哪些初始化方式?
String类型的初始化在Java中分为两类:
new像一个普通的对象那样初始化一个String实例。public static void main(String... args) {
String s1 = "abcd";
String s2 = new String("abcd");
System.out.println(s1 == s2); // false
}
public static void main(String... args) {
String s1 = "abcd";
String s2 = "abcd";
System.out.println(s1 == s2); // true
}
public static void main(String... args) {
String s = new String("abcd");
}
"abcd"本身是一个对象,被放于常量池。而由于这里使用了new关键字,所以s得到的对象必然是被创建在heap里的。所以,这里其实一共创建了2个对象。"abcd"这个字符串,那么它就事先在常量池中被创建了出来。此时,这里就只会创建一个对象,即创建在heap的new String("abcd")对象。3. String是线程安全的吗?
4. 为什么我们在使用HashMap的时候常用String做key?
5. String的intern()方法是什么?
String.intern()方法,可以在runtime期间将常量加入到常量池(constant pool)。它的运作方式是:
intern()方法返回这个存在于constant pool中的常量的引用。intern()方法返回这个新创建的常量的引用。public static void main(String... args) {
String s1 = "abcd";
String s2 = new String("abcd");
/**
* s2.intern() will first search String constant pool,
* of which the value is the same as s2.
*/
String s3 = s2.intern();
// As s1 comes from constant pool, and s3 is also comes from constant pool, they‘re same.
System.out.println(s1 == s3);
// As s2 comes from heap but s3 comes from constant pool, they‘re different.
System.out.println(s2 == s3);
}
/**
* Output:
* true
* false
*/
intern()这个函数呢?就是因为,虽然"abcd"是被分配在常量池里的,但是,一旦使用new String("abcd")就会在heap中新创建一个值为abcd的对象出来。试想,如果有100个这样的语句,岂不是就要在heap里创建100个同样值的对象?!这就造成了运行的低效和空间的浪费。intern()它就会直接去常量池找寻是否有值相同的String对象,这就极大地节省了空间也提高了运行效率。6. 关于常量池的一些编程题(1)
String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c";
System.out.println(s3 == s2); //false 不相等,s1是变量,编译的时候确定不了值,在内存中会创建值,s3在堆内存中,。s2在常量池,所以不相等。
System.out.println(s3.equals(s2)); //true 比较两个对象的值相等。
String s1 = "abc"; String s2 = "abc";
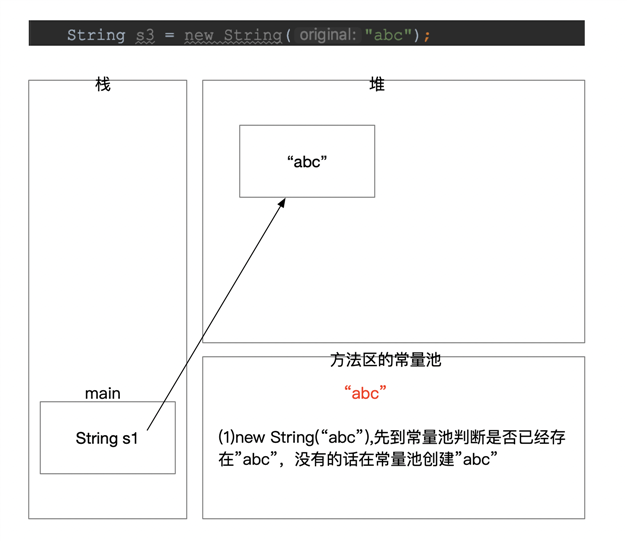
7. 关于常量池的一些编程题(2)
String s1 = new String("Hello");
String s2 = new String("Hello");
8. 浅谈一下String, StringBuffer,StringBuilder的区别?
synchronized 修饰:

参考|引用
文章标题:Java面试炼金系列 (1) | 关于String类的常见面试题剖析
文章链接:http://soscw.com/index.php/essay/68581.html