【C语言】预处理、宏定义、内联函数
2021-03-27 15:27
标签:报错 预处理器 info src 生成 的区别 预处理 本质 实现 1. 预处理: 源码经过预处理器的预处理变成预处理过的 2. 编译: 中间文件经过编译器编译形成 3. 汇编: 汇编文件经过汇编器生成目标文件 4. 链接: 链接器将目标文件链接成 在整个过程中,预处理用预处理器,编译用编译器,汇编用汇编器,链接用链接器,这几个工具再加上其他额外的可能会用到的工具,合起来叫编译工具链。 其中,编译器的主要目的是编译源代码,即将 在预处理的时候,预处理器将所包含的头文件的内容原处展开替换这 我们在 一般情况下,源程序中所有行都参与编译,但有时希望程序有多种配置,对一部分内容指定编译条件(如产品的调试版与正式版),这就是条件编译 这种判定方法类似于 预编译结果如下所示: 结果如下所示: 用 非带参宏主要结合条件编译使用,比较简单,其定义格式为 如下所示: 如下是在 预编译结果如图所示: 宏可以带参数,称为带参宏。带参宏的使用和带参函数非常相似,只是在使用上和处理上有一些差异,其定义格式为: 在定义带参宏时,每一个参数在宏体中引用时都必须加括号,最后整体再加括号,括号缺一不可。 不带括号的后果: 如上测试代码,我们想得到 1. 2. 这个宏需要注意的是 宏和函数各有千秋,最大的特点是:用函数的时候程序员不太用操心类型不匹配因为编译器会检查,用宏的时候程序员必须注意实际传参和宏所希望的参数类型一致,或者自行加入类型检查,否则可能编译不报错但是运行有误。 如对 测试代码: 内联函数本质上是函数,通过在函数定义前加 当函数的函数体很小,而且被大量频繁调用,应该做内联展开时,就可以使用内联函数。但编译器会不会作内联展开,编译器也会有自己的权衡(不合理的内联函数会降低 用 转自:https://blog.csdn.net/weixin_43955214/article/details/104255557 【C语言】预处理、宏定义、内联函数 标签:报错 预处理器 info src 生成 的区别 预处理 本质 实现 原文地址:https://www.cnblogs.com/zhj868/p/13658599.html一、由源码到可执行程序的过程
.i中间文件1 gcc -E test.c -o test.i
.s的汇编文件1 gcc -S test.i -o test.s
.o(机器语言)1 gcc -c test.s -o test.o
.exe可执行程序(Linux下是.elf)1 gcc test.o -o test.exe
gcc/g++就是一个编译工具链,在实际工程中并不会去手动生成那么多中间文件,而是直接一步到位:1 gcc test.c -o test.exe
.c的源代码(.i本质上就是预处理过的.c)转化成.s汇编代码。为了让编译器聚焦核心功能,就将一些非核心功能剥离到预处理器去了,也就是所让预处理器帮编译器做一些编译前的准备工作。二、编程中常见的预处理
#include#if #elif #endif...2.1 头文件包含
2.1.1
#include 和 #include ""的区别
#include 专门用来包含系统提供的头文件,如果使用,编译器只会到系统指定目录(编译器中配置的或OS配置的目录,如在Ubuntu中是/usr/include,编译器还允许用-I来附加指定其他的包含路径)去寻找这个头文件,如果找不到就会提示这个头文件不存在。#include ""用来包含程序员写的头文件,编译器默认先在当前目录下寻找相应的头文件,如果没找到再到系统指定目录去寻找,如果还没找到则提示文件不存在。使用原则
""-I参数寻找用2.1.2 头文件包含在预处理时的处理方式
#include语句。
如下所示分别是同一目录下的.c文件和.h文件: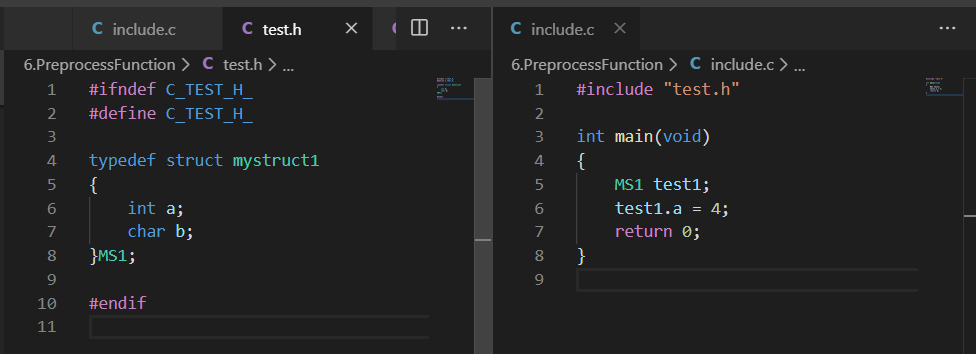
对其进行预编译生成.i文件后,.i文件的内容如下所示: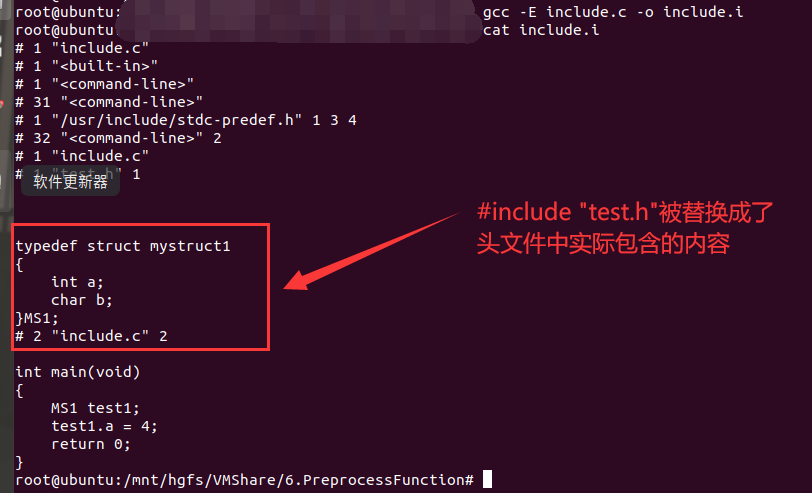
2.2 注释
.c源文件中写的注释,预处理器在预处理阶段会将其擦除(在.c文件依然存在,在.i文件中不存在)。其实这也正顺应了注释是写给使用程序的人看的,而不是给编译器看的。如下所示: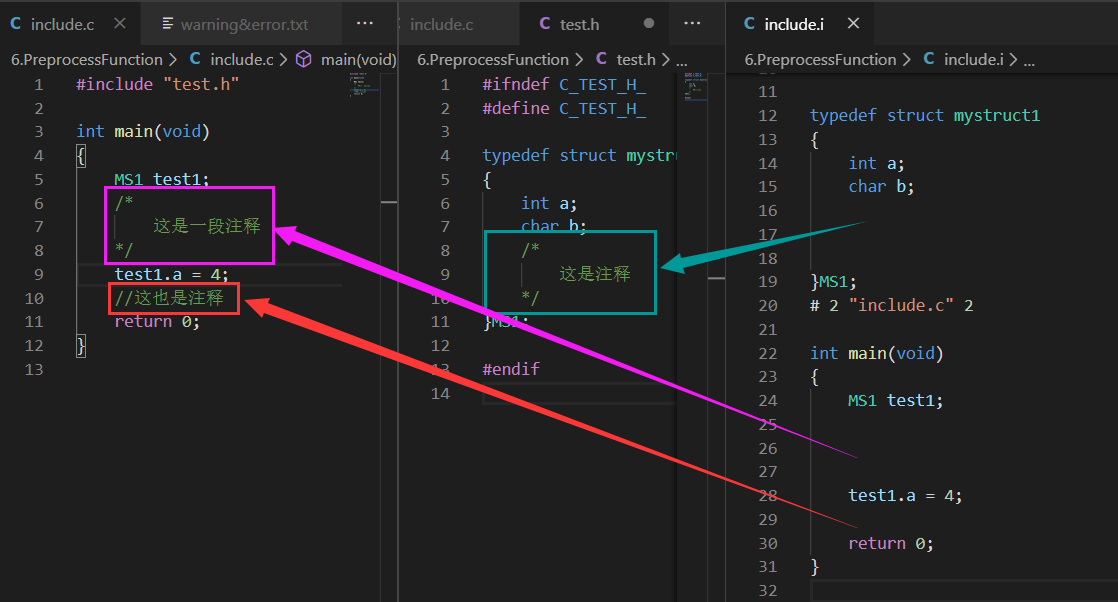
2.3 条件编译
(conditional compile),条件编译有以下两种判定方法:2.3.1
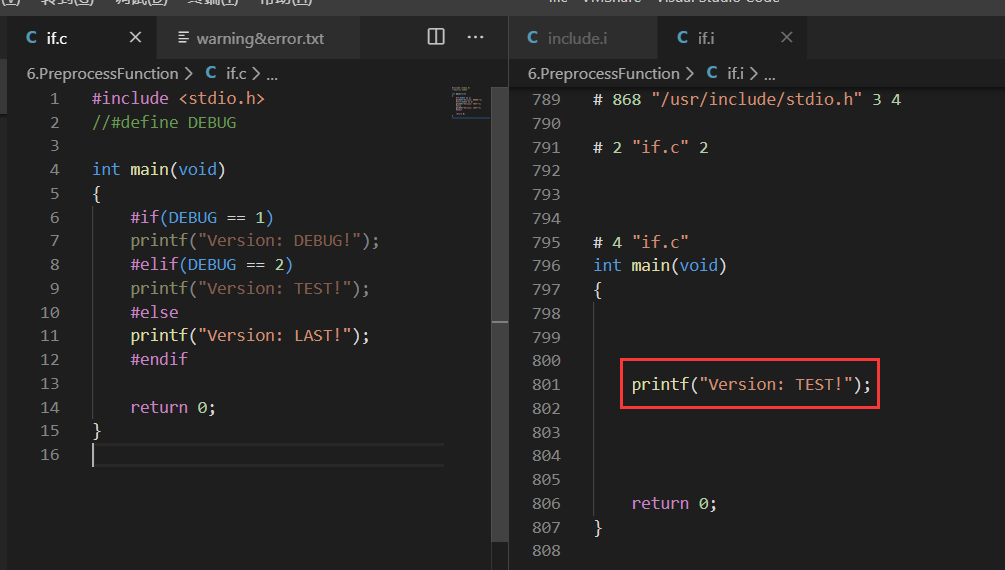
#ifif...else...语句,格式为#if (条件表达式),它的判定标准是()中的表达式是true还是flase,在进行预编译的过程中,只会保留条件表达式为真的那部分内容,如下所示测试代码: 1 #include
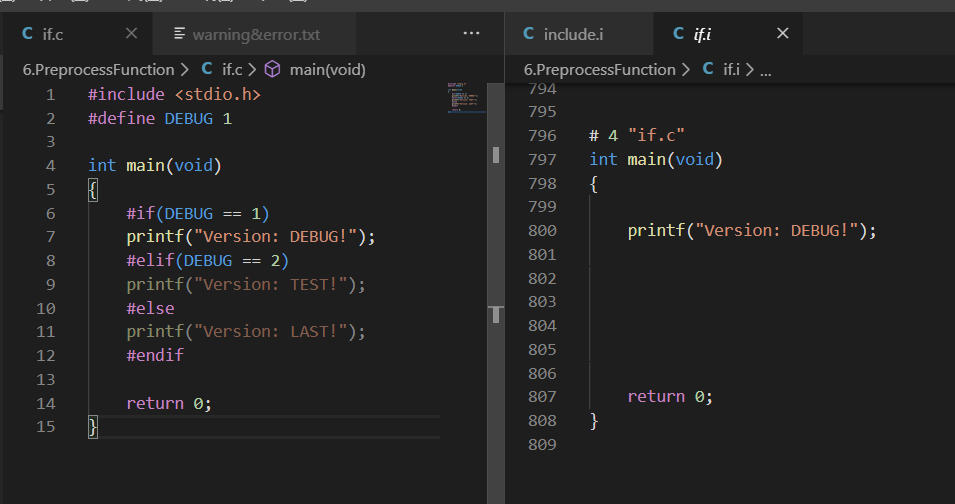
我们也可以不在源码中对DEBUG进行宏定义,而在编译的时候可以用如下方法对其进行宏定义并指定值:1 gcc -E -D DEBUG=2 test.c -o test.i
2.3.2
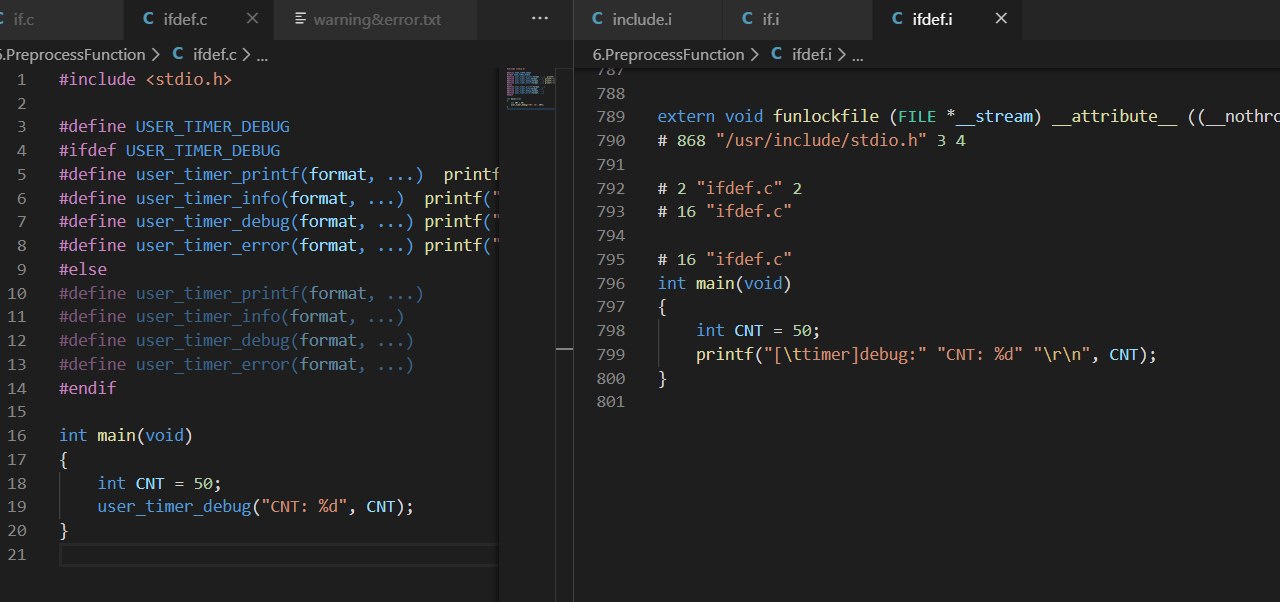
#ifdef#ifdef XXX判定条件成立与否时主要是看XXX这个符号在本语句之前有没有被定义,只要定义了,判断就成立,并不关心XXX的宏值为多少。测试代码及结果参见下文3.1非带参宏的内容三、宏定义
3.1 非带参宏
#define 宏名 替换列表(替换列表可有可无)1 #define DEBUG
2 #define TEST 1
3 #define TEST2 TEST
宏定义的预处理
STM32开发过程中常用的打印调试信息的一个调试代码段: 1 #include
3.2 带参宏
#define 标识符(参数1,参数2,...,参数n) 替换列表1 #include
(2 + 3) * 5的结果,但是由于宏在预处理的时候也是进行机械替换,int result = M(2 + 3, 5)变成了int result = 2 + 3 * 5,这及其容易出现逻辑上的错误3.2.1 带参宏示例
MAX宏: 求2个数中较大的一个#define MAX(a, b) (((a)>(b)) ? (a) : (b))SEC_PER_YEAR宏 用宏定义表示一年中有多少秒#define SEC_PER_YEAR (365*24*60*60UL)
intint类型存储的范围UL将其转为无符长整型3.2.2 带参宏和带参函数的区别
1.时间与空间
2.执行速度
3.类型检查
综合比较
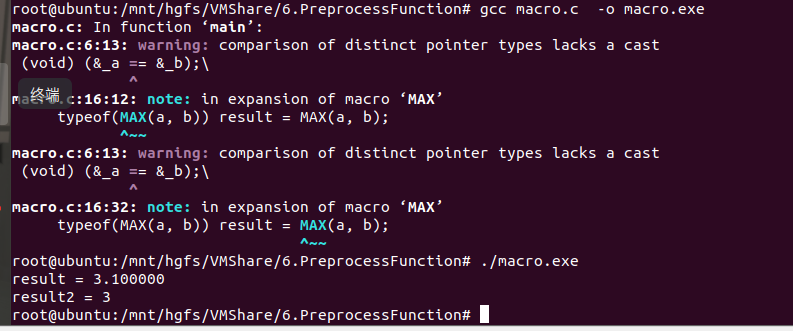
MAX宏加入类型检查:1 #define MAX(a, b) ({2 typeof(a) _a = (a); 3 typeof(b) _b = (b); 4 (void) (&_a == &_b);5 _a > _b ? _a : _b;})
1 #include
四、内联函数
inline关键字实现,是编译器负责处理的,可以做参数的静态类型检查。同时也有带参宏的展开特性,运行时没有调用开销。4.1 与常规函数对比
4.2 与宏的对比
4.3
noinline和always_inlineCPU寻址效率、函数运行效率、降低代码的可移植性…)。如果想告诉编译器一定要展开,或者不作展开,就可以使用noinline或always_inline对函数作一个属性声明。1 static inline int func(int *, int);//编译器权衡是否内联展开
2 static inline __attribute__((noinline)) int func(int *, int);//不内联展开
3 static inline __attribute__((always_inline)) int func(int *, int);//内联展开
static修饰呢是因为内联函数不一定会内联展开,当多个文件都包含同一个内联函数的定义时,如果没有static将函数的作用域限制在各自本地文件内,编译时就有可能报重定义错误
上一篇:python tgz包安装
下一篇:C语言学习DAY5