ThunderNet :像闪电一样,旷视再出超轻量级检测器,高达267fps | ICCV 2019
2021-03-28 01:26
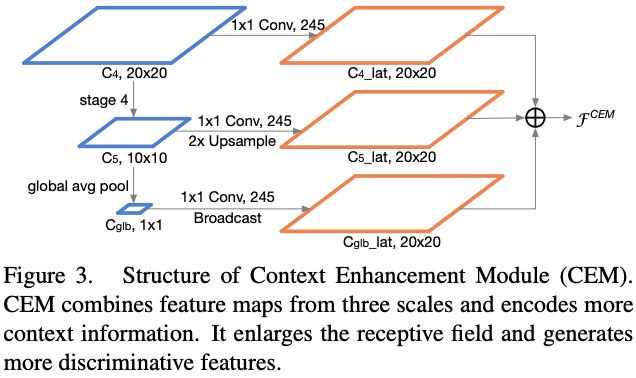
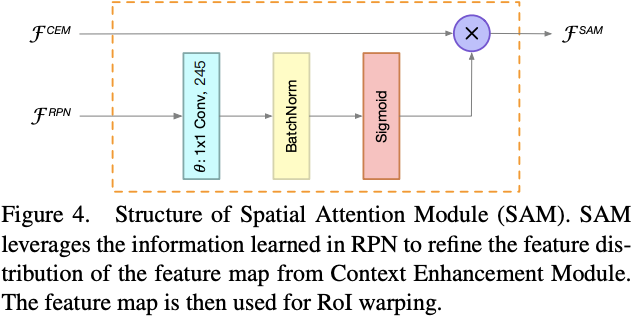
标签:维度 细节 中间 iso arp 接受 尺寸 增加 分辨率 论文提出了实时的超轻量级two-stage detector ThunderNet,靠着精心设计的主干网络以及提高特征表达能力的CEM和SAM模块,使用很少的计算量就能超越目前的one-stage detectors,在ARM平台也达到了实时性,GPU的速度更是达到267fps 论文: ThunderNet: Towards Real-time Generic Object Detection ? one-stage detector和two-stage detector分别有着实时优势和准确率优势。two-stage detector实时性较差,几乎不能在移动设备上运行,尽管已经有了light-head版本,但对于小主干网络而言,这依然是过度设计的。而one-stage由于缺少ROI-wise的特征提取,准确率一直较差 ? 为此,论文提出TunderNet,一个超轻量级的two-stage detector。在综合考虑输入分辨率,主干网络和detection head后,整体架构如图2,主要有两部分创新: ? ThunderNet准确率比目前的轻量级one-stage detector都要高,且仅用了很少的计算量,在ARM和x86设备上分别达到了24.1fps和47.3fps ? two-stage detector的输入通常都很大,为了减少计算量,ThunderNet使用$320\times 320$的输入分辨率。需要注意,输入分辨率应该与主干网络的能力匹配 ? 由于图像分类和图像检测需要主干网络用不同的属性,简单地直接应用图像分类的网络作为主干不是最优的: ? 目前的轻量级主干网络都不符合上面的因素:ShuffleNetV1/V2限制了感受域的大小(121 pixels vs. 320 pixels,(这里的计算方法暂时不了解,另外下面说V2为121 pixels,跟这里不一致,希望了解的读者能留言告知)),ShuffleNetV2和MobileNetV2则缺少了early-stage的特征,而Xception则没有足够的高层特征 ? 基于以上的观察,论文改造ShuffleNetV2,设计了轻量级主干网络SNet用于实时检测,共3个版本: SNet49更快速推理;SNet535更准确;SNet146是耗时和准确率的折中,结构如表1所示,主要改进如下: ? Light-Head R-CNN虽然已经够轻量级了,但是相对于小主干网络,仍然是过度设计的。为了解决这一问题,论文将256-channel 3x3卷积压缩为5x5深度卷积和256-channel 1x1卷积的组合,加大卷积核大小来增加感受域,而anchor box的尺寸和长宽比分别为${322,642,1282,2562,512^2}$和${1:2,3:4,1:1,4:3,2:1}$ ? Light-Head R-CNN使用Global Convolutional Network(GCN)来产生精简特征图,GCN使用$k\times 1 + 1\times k$和$1\times k + k\times 1$卷积代替$k\times k$卷积,这样能提升感受域,但会带来两倍的计算量,不能采用。因此,论文借鉴FPN的思想,提出了Context Enhancement Module(CEM)来整合多尺度的局部上下文信息和全局的上下文信息 ? CEM融合$C_4$,$C_5$和$C_{glb}$,其中$C_{glb}$为global average pooling的全局特征,然后用1x1卷积将每组特征图压缩至$\alpha\times p\times p=245$,再$C_5$和$C_{glb}$进行2x上采样和直接复制(broadcast),最后进行融合。通过利用局部和全局信息,CEM能够有效地扩大感受域和改善精简特征图的表达能力。对比FPN,CEM精算量相当小 ? 由于ThunderNet使用了更小的主干网络和输入分辨率,这增加了检测的难度。论文提出Spatial Attention Module(SAM),在空间维度对RoI warping前的特征图进行re-weight,核心思想是利用RPN的信息来优化特征图的特征分布 ? RPN能够识别目标区域,因此,RPN的中间特征能用来区分前景特征。SAM接受RPN的中间特征$\mathcal{F}{RPN}$和来自CEM的特征$\mathcal{F}{CEM}$,输出$\mathcal{F}^{SAM}$。整体流程如图4,$\theta$为维度转化函数,将特征图转化为特定channel,一般用1x1卷积,最后的Sigmoid将数值限制在$[0,1]$ ? SAM包含两个函数,第一个是推理函数,用来加强前景特征同时抑制背景特征。另一个是反向传播函数,因为SAM增加了额外的R-CNN梯度到RPN,需要稳定RPN的训练,RPN特征$i$与全部SAM特征$j$相关 ? 每张图训练和测试分别有2000和200 RoIs,输入分辨率为$320\times 320$,使用多尺寸训练${240,320,480}$,使用SSD的数据增强,在VOC和COCO分别训练62.5K和375K,使用OHEM和Soft-NMS ? 可以看到,ThunderNet能达到SOTA,而且相对于同准确率的模型,计算量降低了很多 ? MS COCO数据集包含很多小物体,尽管ThunderNet输入分辨率和主干网络都较小,但是准确率依然能在大幅减少参数量的情况下达到目前的SOTA ? 可以看到,小主干网络与大输入分辨率和大主干网络和小输入分辨率都达不到最优的结果,两者需要match ? 论文将SNet146和SNet49作为baselines,对主干网络的设计进行实验对比: ? 论文将压缩后的Light-Head R-CNN with SNet146作为baseline,对ThunderNet的detection part的设计进行对比: ? 论文对比了主干网络和head的关系,large-backbone-small-head的准确率要高点,可能由于small-backbone-large-head的主干网络的特征太弱了,导致head过度设计 ? 论文对比了不同设备上的不同网络的推理速度,Yhunder with SNet49在ARM和CPU上都能达到实时性,而所有的网络在GPU上都大于200fps,速度相当劲爆 ? ? 论文提出了实时的轻量级two-stage detector ThunderNet,在backbone部分,使用一个精心设计的目标检测专用的轻量级网络SNet,在detection部分,采用极度精简的detection head和RPN,提出Context Enhancement Module和Spatial Attention Module用于增强特征表达能力,最后对输入分辨率、backbone和detection head进行了缩减和平衡。ThunderNet使用很少量的计算量超越了目前的one-stage detectors,在ARM平台也达到了实时性,GPU的速度更是达到267fps ? ? 写作不易,未经允许不得转载~ ThunderNet :像闪电一样,旷视再出超轻量级检测器,高达267fps | ICCV 2019 标签:维度 细节 中间 iso arp 接受 尺寸 增加 分辨率 原文地址:https://www.cnblogs.com/VincentLee/p/12625878.html
?
来源:【晓飞的算法工程笔记】 公众号
Introduction
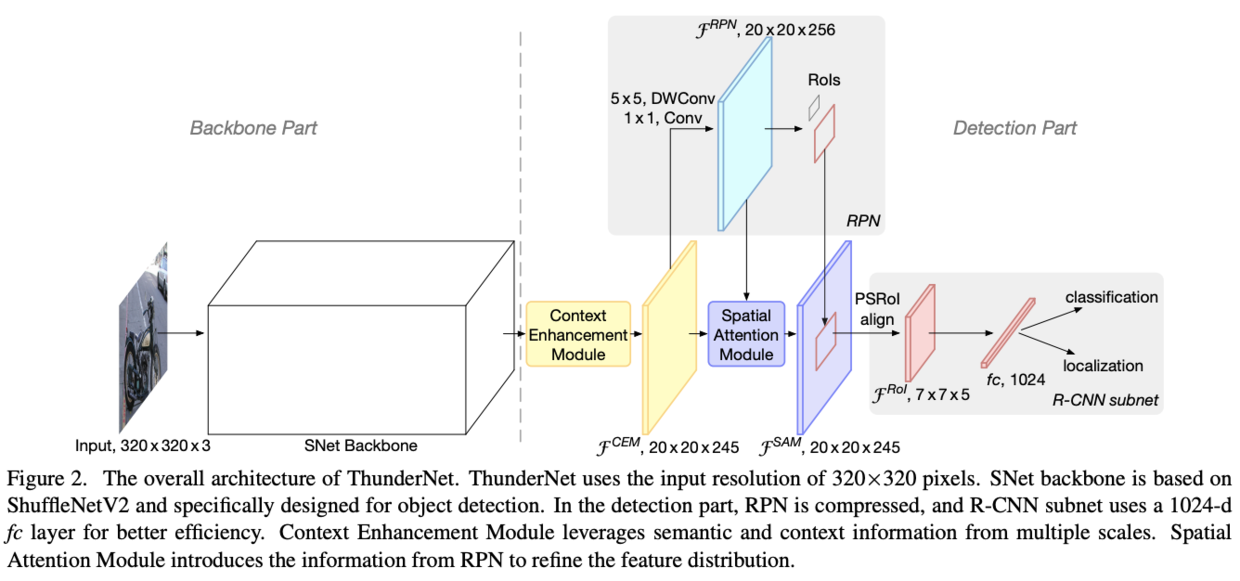
ThunderNet
Backbone Part
Input Resolution
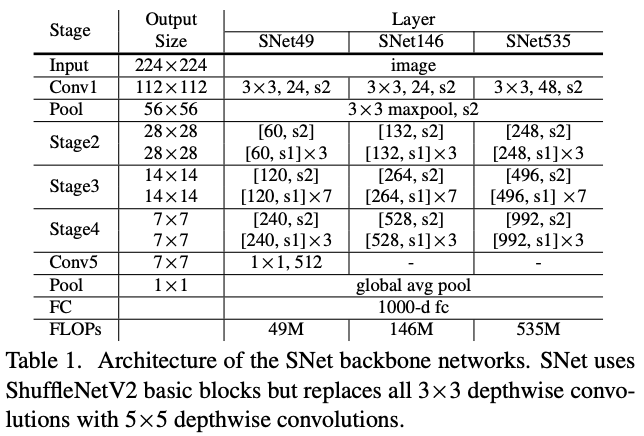
Backbone Networks
Detection Part
Compressing RPN and Detection Head
? 对于detection head,Light-Head R-CNN在RoI warping前生成很精简特征图(thin feature map)大小$\alpha\times p\times p$ ,$\alpha=10$,$p=7$为池化大小。由于主干网络更小,缩小$\alpha=5$来移除多余的计算,用PSRoI align($(p\times p\times c)\times w\times h$ to$c\times p\times p$)进行RoI warping,将245-d的RoI特征输出为$\alpha$-d,之后在R-CNN子网接一个1024-d全连接
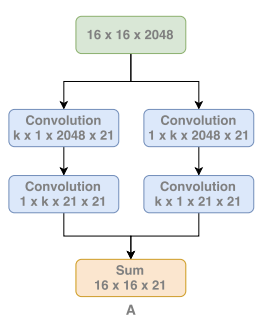
Context Enhancement Module(CEM)
Spatial Attention Module
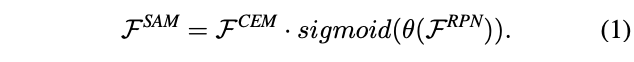
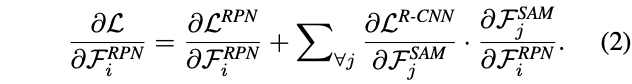
Experiments
Implementation Details
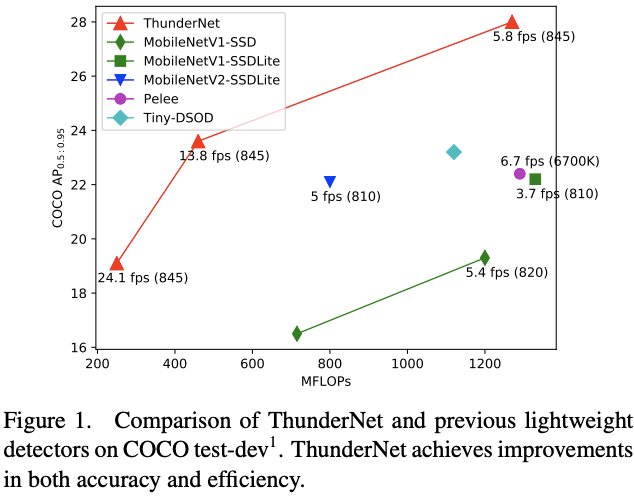
Results on PASCAL VOC
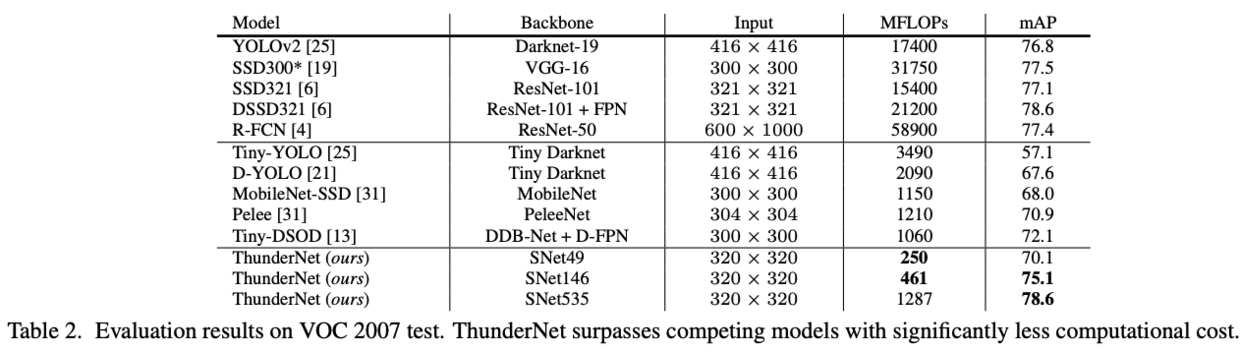
Results on MS COCO
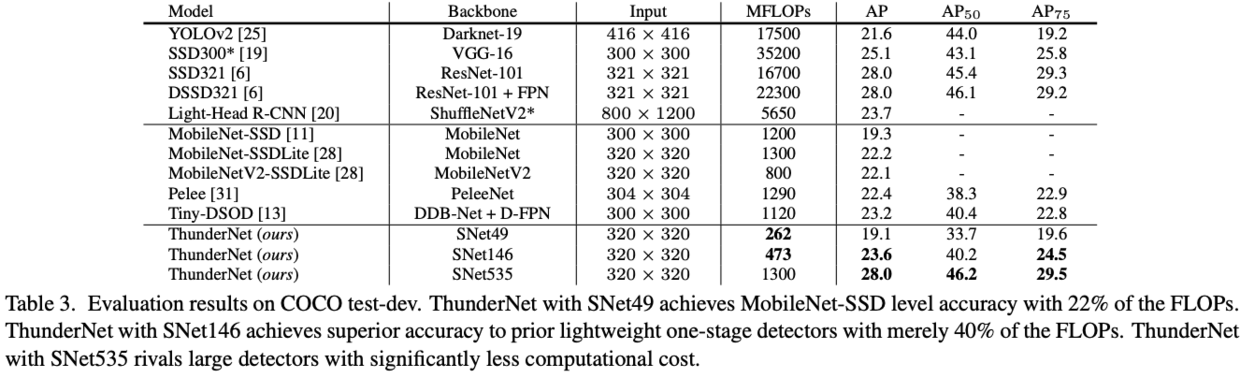
Ablation Experiments
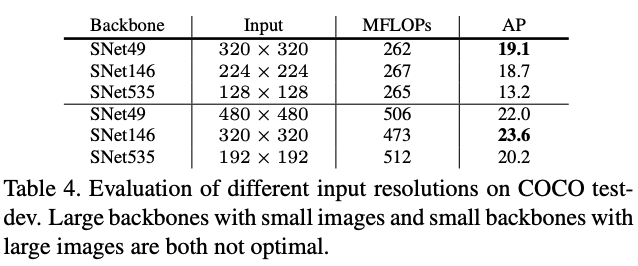
Input Resolution
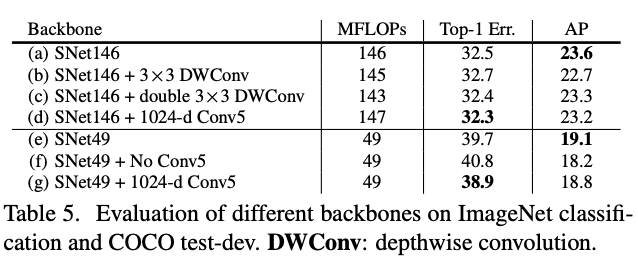
Backbone Networks
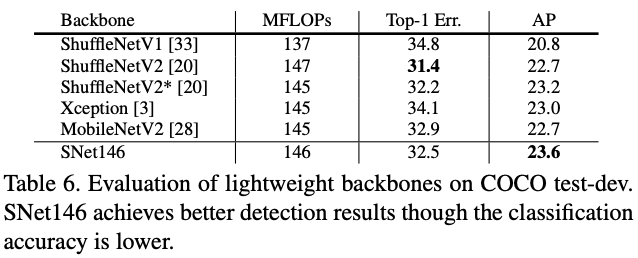
Detection Part
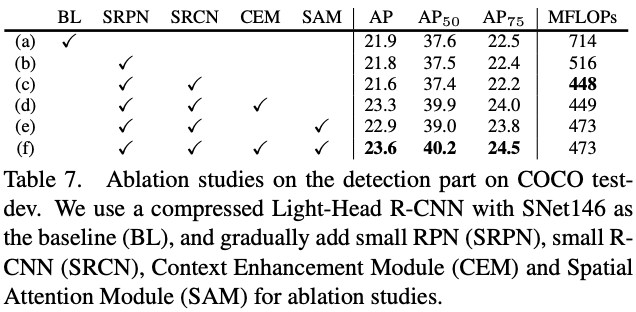

Balance between Backbone and Detection Head

Inference Speed

CONCLUSION
参考内容
?
?
更多内容请关注 微信公众号【晓飞的算法工程笔记】
上一篇:css使文字显示两行后显示省略号
文章标题:ThunderNet :像闪电一样,旷视再出超轻量级检测器,高达267fps | ICCV 2019
文章链接:http://soscw.com/index.php/essay/68825.html