ThunderNet: Towards Real-time Generic Object Detection
2021-03-28 04:25
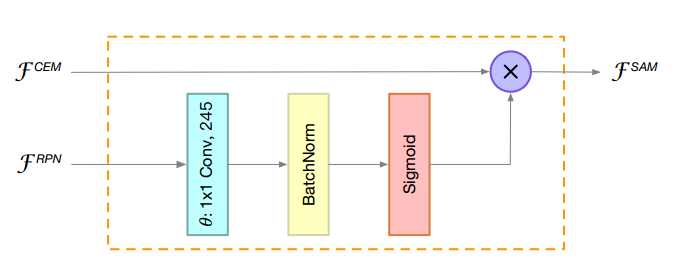
标签:counter ini ict adc different not 证明 rri amp Related Work CNN-based object detectors:CNN-based object detectors are commonly classified into two-stage detectors and one-stage detectors. In two-stage detectors, R-CNN [8] is among the earliest CNN-based detection systems. Since then, progressive improvements [9, 7] are proposed for better accuracy and efficiency. Faster R-CNN [27] proposes Region Proposal Network (RPN) to generate regions proposals instead of pre-handled proposals. R-FCN [4] designs a fully convolutional architecture which shares computation on the entire image. On the other hand, one-stage detectors such as SSD [19] and YOLO [24, 25, 26] achieve real-time inference on GPU with very competitive accuracy. RetinaNet [17] proposes focal loss to address the foregroundbackground class imbalance and achieves significant accuracy improvements. In this work, we present a two-stage detector which focuses on efficiency. 基于cnn的目标检测通常分为两级检测和一级检测。在两级探测器中,R-CNN[8]是最早的基于cnn的检测系统之一。此后,为了提高准确性和效率,提出了渐进式改进[9,7]。Faster R-CNN[27]提出区域建议网络(RPN)生成区域建议,而不是预先处理的建议。R-FCN[4]设计了一个完全卷积的架构,在整个图像上共享计算。另一方面,单级检测器如SSD[19]和YOLO[24, 25, 26]在GPU上实现实时推理,具有非常具有竞争力的准确性。RetinaNet[17]提出了 focal loss来解决前背景级的不平衡,并实现了显著的精度改进。在这项工作中,我们提出了一种关注效率的两级探测器。 Real-time generic object detection:Real-time object detection is another important problem for CNN-based detectors. Commonly, one-stage detectors are regarded as the key to real-time detection. For instance, YOLO [24, 25, 26] and SSD [19] run in real time on GPU. When coupled with small backbone networks, lightweight one-stage detectors, such as MobileNet-SSD [11], MobileNetV2-SSDLite [28], Pelee [31] and Tiny-DSOD [13], chieve inference on mobile devices at low frame rates.For two-stage detectors, Light-Head R-CNN [14] utilizes a light detection head and runs at over 100 fps on GPU. This raises a question: are two-stage detectors better than one-stage detectors in realtime detection? In this paper, we present the effectiveness of two-stage detectors in real time detection. Compared with prior lightweight one-stage detectors, ThunderNet achieves a better balance between accuracy and efficiency. 实时目标检测是基于cnn的检测器的另一个重要问题。通常,单级检测器被认为是实时检测的关键。例如,YOLO[24, 25, 26]和SSD[19]在GPU上实时运行。当与小型骨干网络相结合时,轻量级的单级检测器,如MobileNet-SSD[11]、MobileNetV2-SSDLite[28]、Pelee[31]和Tiny-DSOD[13],在低帧速率下用于移动设备的chieve推理。对于两级探测器,light - head R-CNN[14]使用一个轻检测头,在GPU上以超过100帧的速度运行。这就提出了一个问题:在实时检测中,两级检测器是否优于一级检测器?本文介绍了两级检测器在实时检测中的有效性。与以前的轻量级单级检测器相比,ThunderNet在精度和效率之间取得了更好的平衡。 Backbone networks for detection :Modern CNN-based detectors typically adopt image classification networks [30, 10, 32, 12] as the backbones. FPN [16] exploits the inherent multi-scale, pyramidal hierarchy of CNNs to construct feature pyramids. Lightweight detectors also benefit from the recent progress in small networks, such as MobileNet [11, 28] and ShuffleNet [33, 20]. However, image classification and object detection require different properties of networks. Therefore, simply transferring classification networks to object detection is not optimal. For this reason, DetNet [15] designs a backbone specifically for object detection. Recent lightweight detectors [31, 13] also design specialized backbones. However, this area is still not well studied. In this work, we investigate the drawbacks of prior lightweight backbones and present a lightweight backbone for real-time detection task. ThunderNet Backbone Part Input Resolution:The input resolution of two-stage detectors is usually very large, e.g., FPN [16] uses input images of 800× pixels. It brings several advantages but involves enormous computational cost as well. To improvethe inference speed, ThunderNet utilizes the input resolution of 320×320 pixels. Moreover, in practice, we observe that the input resolution should match the capability of the backbone. A small backbone with large inputs and a large backbone with small inputs are both not optimal. Backbone Networks :Backbone networks provide basic feature representation of the input image and have great influence on both accuracy and efficiency. CNN-based detectors usually use classification networks transferred from ImageNet classification as the backbone. However, as image classification and object detection require different properties from the backbone, simply transferring classification networks to object detection is not optimal. Receptive field:Receptive field: The receptive field size plays an important role in CNN models. CNNs can only capture information inside the receptive field. Thus, a large receptive field can leverage more context information and encode long-range relationship between pixels more effectively. This is crucial for the localization subtask, especially for the localization of large objects. Previous works [23, 14] have also demonstrated the effectiveness of the large receptive field in semantic segmentation and object detection. 感受野大小在CNN模型中起重要作用。CNNs只能捕获感受野内的信息。因此,一个大的感受野可以利用更多的上下文信息,更有效地编码像素之间的长期关系。这对于本地化子任务非常重要,特别是对于大型对象的本地化。前人的工作[23,14]也证明了大感受野在语义分割和目标检测中的有效性。 Early-stage and late-stage features :Early-stage and late-stage features: In the backbone, early stage feature maps are larger with low-level features which describe spatial details, while late-stage feature maps are smaller with high-level features which are more discriminative. Generally, localization is sensitive to low level features while high-level features are crucial for classification. In practice, we observe that localization is more difficult than classification for larger backbones, which indicates that early-stage features are more important. And the weak representation power restricts the accuracy in both subtasks for extremely tiny backbones, suggesting that both early-stage and late-stage features are crucial at this level. The designs of prior lightweight backbones violate the aforementioned factors: ShuffleNetV1/V2 [33, 20] have restricted receptive field (121 pixels vs. 320 pixels of input),ShuffleNetV2 [20] and MobileNetV2 [28] lack early stage features, and Xception [3] suffer from the insufficient highlevel features under small computational budgets. 之前的轻量级骨架的设计违背了上述因素:ShuffleNetV1/V2[33, 20]限制了接受域(121像素vs 320像素的输入),ShuffleNetV2[20]和MobileNetV2[28]缺乏早期阶段的特性,Xception[3]在小的计算预算下缺乏足够的高级特性。 Based on these insights, we start from ShuffleNetV2, and build a lightweight backbone named SNet for real-time detection. We present three SNet backbones: SNet49 for faster inference, SNet535 for better accuracy, and SNet146 for a better speed/accuracy trade-off. First, we replace all 3×3 depthwise convolutions in ShuffleNetV2 with 5×5 depthwise convolutions. In practice, 5×5 depthwise convolutions provide similar runtime speed to 3×3 counterparts while effectively enlarging the receptive field (from 121 to 193 pixels). In SNet146 and SNet535, we remove Conv5 and add more channels in early stages. This design generates more low-level features without additional computational cost. In SNet49, we compress Conv5 to 512 channels instead of removing it and increase the channels in the early stages for a better balance between low-level and high-level features. If we remove Conv5, the backbone cannot encode adequate information. But if the 1024-d Conv5 layer is preserved, the backbone suffers from limited low-level features. Table 1 shows the overall architecture of the backbones. Besides, the last output feature maps of Stage3 and Stage4 (Conv5 for SNet49) are denoted as C4 and C5. 基于这些见解,我们从ShuffleNetV2开始,并构建一个轻量级的主干,名为SNet,用于实时检测。我们提出了三个SNet主干:SNet49用于更快的推理,SNet535用于更好的准确性,SNet146用于更好的速度/准确性权衡。首先,我们将ShuffleNetV2中的所有3×3深度卷积替换为5×5深度卷积。在实践中,5×5深度卷积与3×3深度卷积的运行速度相当,同时有效地扩大了接受域(从121像素到193像素)。在SNet146和SNet535中,我们在早期删除了Conv5并添加了更多的通道。这种设计在不增加计算开销的情况下生成了更多的底层特性。在SNet49中,我们将Conv5压缩到512个通道,而不是删除它,并在早期增加通道,以更好地平衡低层和高层特征。如果我们移除Conv5,主干就无法编码足够的信息。但是,如果保留1024-d Conv5层,骨干就会受到有限的低层特征的影响。表1显示了主干的总体架构。此外,Stage3和Stage4(对于SNet49为Conv5)的最后输出特征映射分别表示为C4和C5。 Detection Part 两级检测器通常采用较大的RPN和较重的检测头。虽然Light-Head R-CNN[14]使用了一个轻量级的检测头,但是当它与小的主干结合时仍然太重,导致主干和检测部分之间不平衡。这种不平衡不仅会导致冗余计算,还会增加过拟合的风险。 To address this issue, we compress RPN by replacing the original 256-channel 3×3 convolution with a 5×5 depthwise convolution and a 256-channel 1×1 convolution. We increase the kernel size to enlarge the receptive field and encode more context information. Five scales f322, 642, 1282, 2562, 5122g and five aspect ratios f1:2, 3:4, 1:1, 4:3, 2:1g are used to generate anchor boxes. Other hyperparameters remain the same as in [14]. 为了解决这个问题,我们压缩RPN,将原来的256通道3×3卷积替换为5×5深度卷积和256通道1×1卷积。我们增加内核的大小,以扩大感受野和编码更多的上下文信息。五个比例f322, 642, 1282, 2562, 5122g和五个长宽比f1:2, 3:4, 1:1, 4:3, 2:1g用于生成anchor boxes。其他超参数与[14]相同。 In the detection head, Light-Head R-CNN generates a thin feature map with α × p × p channels before RoI warping, where p = 7 is the pooling size and α = 10. As the backbones and the input images are smaller in ThunderNet, we further narrow the feature map by halving α to 5 to eliminate redundant computation. For RoI warping, we opt for PSRoI align as it squeezes the number of channels to α. 在检测头,Light-Head R-CNN在RoI warping之前生成一个α × p × p 通道的thin feature map,RoI warping中p = 7的池大小和α= 10。随着在ThunderNet中,主干和输入图像都比较小,为了消除冗余计算,我们通过减半α到5进一步缩小feature map。对于RoI warping,我们选择 PSRoI align为α挤压通道的数量。 As the RoI feature from PSRoI align is merely 245-d, we apply a 1024-d fully-connected (fc) layer in R-CNN subnet. this design further reduces the computational cost of R-CNN subnet without sacrificing accuracy. Besides, due to the small feature maps, we reducethe number of RoIs for testing. 由于PSRoI align的RoI特性仅仅是245-d,因此我们在R-CNN子网中应用了一个1024-d的全连接(fc)层。该设计在不牺牲精度的前提下,进一步降低了R-CNN子网的计算成本。此外,由于小的特征图,我们减少了测试的roi数量。 Context Enhancement Module :Light-Head R-CNN applies Global Convolutional Network (GCN) [23] to generate the thin feature map. It significantly increases the receptive field but involves enormous computational cost. Coupled with SNet146, GCN requires 2× the FLOPs needed by the backbone (596M vs. 298M). For this reason, we decide to abandon this design in ThunderNet. However, the network suffers from the small receptive field and fails to encode sufficient context information without GCN. A common technique to address this issue is Feature Pyramid Network (FPN) [16]. However, prior FPN structures [16, 6, 13, 26] involve many extra convolutions and multiple detection branches, which increases the computational cost and induces enormous runtime latency. 然而,网络的感受野较小,没有GCN无法编码足够的上下文信息。解决这一问题的常用技术是特征金字塔网络(FPN)[16]。然而,先前的FPN结构[16,6,13,26]涉及许多额外的卷积和多个检测分支,这增加了计算成本,并导致巨大的运行时延迟。 For this reason, we design an efficient Context Enhancement Module (CEM) to enlarge the receptive field. The key idea of CEM is to aggregate multi-scale local context information and global context information to generate more discriminative features. In CEM, the feature maps from three scales are merged: C4, C5 and Cglb. Cglb is the global context feature vector by applying a global average pooling on C5. We then apply a 1 × 1 convolution on each feature map to squeeze the number of channels to α × p × p = 245. Afterwards, C5 is upsampled by 2× and Cglb is broadcast so that the spatial dimensions of the three feature maps are equal. At last, the three generated feature maps are aggregated. By leveraging both local and global context, CEM effectively enlarges the receptive field and refines the representation ability of the thin feature map. Compared with prior FPN structures, CEM involves only two 1×1 convolutions and a fc layer, which is more computation-friendly. 为此,我们设计了一个有效的上下文增强模块(CEM)来扩大接受域。CEM的核心思想是将多尺度的局部上下文信息和全局上下文信息聚合在一起,以生成更有鉴别性的特征。CEM融合了C4、C5和Cglb三种尺度的特征图。Cglb是在C5上应用全局平均池的全局上下文特征向量。然后在每个特征图上应用1×1卷积把通道数量压缩到α×p×p = 245。然后对C5进行2×上采样,广播Cglb,使三幅地物图的空间尺寸相等。最后,对生成的三种特征图进行了聚合。通过利用局部和全局上下文,CEM有效地扩展了接受域,提高了thin feature map的表示能力。与之前的FPN结构相比,CEM只涉及两个1×1的卷积和一个fc层,计算友好。 上下文增强模块(CEM)的结构。CEM结合了三种尺度的特征图,并对更多的上下文信息进行编码。它扩大了感受野,产生了更多的区别性特征。 Spatial Attention Module :During RoI warping, we expect the features in the background regions to be small and the foreground counterparts to be high. However, compared with large models, as ThunderNet utilizes lightweight backbones and small input images, it is more difficult for the network itself to learn a proper feature distribution. 在RoI warping过程中,我们期望背景区域的特征是小而前景区域的特征是高。但是,与大型模型相比,由于ThunderNet采用的是轻量级的主干和较小的输入图像,网络本身很难学习到合适的特征分布。 For this reason, we design a computation-friendly Spatial Attention Module (SAM) to explicitly re-weight the feature map before RoI warping over the spatial dimensions. The key idea of SAM is to use the knowledge from RPN to refine the feature distribution of the feature map. RPN is trained to recognize foreground regions under the supervision of ground truths. Therefore, the intermediate features in RPN can be used to distinguish foreground features from background features. SAM accepts two inputs: the intermediate feature map from RPN F RPN and the thin feature map from CEM F CEM. The output of SAM F SAM is defined as: 为此,我们设计了一个计算友好的空间注意模块(SAM),在空间维度上RoI warping之前显式地重新调整特征图的权重。SAM的核心思想是利用RPN中的知识来细化特征图的特征分布。RPN被训练在基本事实的监督下识别前景区域。因此,RPN中的中间特征可以用来区分前景特征和背景特征。SAM接受两个输入:来自RPN F (RPN)的中间特征映射和来自CEM F (CEM)的thin feature map。SAM F(SAM)的输出定义为: Here θ(·) is a dimension transformation to match the number of channels in both feature maps. The sigmoid function is used to constrain the values within [0, 1]. At last, F(CEM)is re-weighted by the generated feature map for better feature distribution. For computational efficiency, we simply apply a 1×1 convolution as θ(·), so the computational cost of CEM is negligible. 这里θ(·)是一个维度变换去匹配两者特征图中通道的数量。sigmoid函数用于约束[0,1]内的值。最后根据生成的特征图对F(CEM)进行重新加权,得到更好的特征分布。计算效率,我们简单地应用1×1卷积作为θ(·),所以CEM的计算成本可以忽略不计。 空间注意模块(SAM)的结构。SAM利用在RPN中学习到的信息去细化来自上下文增强模块中特征图的特征分布。然后使用特征图进行RoI warping。 SAM has two functions. The first one is to refine the feature distribution by strengthening foreground features and suppressing background features. The second one is to stabilize the training of RPN as SAM enables extra gradient flow from R-CNN subnet to RPN: SAM有两个功能。一是通过增强前景特征和抑制背景特征来细化特征分布。二是稳定RPN的训练,因为SAM可以使额外的梯度流从R-CNN子网流向RPN: As a result, RPN receives additional supervision from R-CNN subnet, which helps the training of RPN. 因此,RPN接受来自R-CNN子网的额外监督,有助于RPN的训练。 ThunderNet: Towards Real-time Generic Object Detection 标签:counter ini ict adc different not 证明 rri amp 原文地址:https://www.cnblogs.com/chicaideniaoer/p/12620093.html
现代基于cnn的探测器一般采用图像分类网络[30,10,32,12]作为骨架。FPN[16]利用CNNs固有的多尺度金字塔结构构建特征金字塔。轻量级检测器还受益于最近小型网络的进展,如MobileNet[11,28]和ShuffleNet[33,20]。然而,图像分类和目标检测需要不同的网络特性。因此,简单地将分类网络转移到目标检测中并不是最优的。因此,DetNet[15]设计了一个专门用于对象检测的主干。最近的轻量级探测器[31,13]也设计了专门的骨干。然而,这一领域还没有得到很好的研究。在这项工作中,我们研究了现有的轻量级骨干的缺点,并提出了一种用于实时检测任务的轻量级骨干。
In this section, we present the details of ThunderNet. Our design mainly focuses on efficiency, but our model still achieves superior accuracy.在本节中,我们将介绍ThunderNet的详细信息。我们的设计主要关注效率,但是我们的模型仍然达到了更高的精度。
两级探测器的输入分辨率通常非常大,例如FPN[16]使用800×像素的输入图像。它有几个优点,但也涉及到巨大的计算成本。为了提高推理速度,ThunderNet采用320×320像素的输入分辨率。此外,在实践中,我们注意到输入分辨率应该与主干的能力相匹配。具有大输入的小主干和具有小输入的大主干都不是最优的。
骨干网提供了输入图像的基本特征表示,对精度和效率都有很大的影响。基于cnn的检测器通常使用从ImageNet分类中传输的分类网络作为主干。然而,由于图像分类和目标检测需要从主干中获取不同的属性,简单地将分类网络转移到目标检测中并不是最优的。
早期特征和后期特征:在主干中,早期特征图较大,低层特征描述空间细节,后期特征图较小,高层特征更有鉴别性。一般情况下,定位对低层特征敏感,而高层特征对分类至关重要。在实践中,我们观察到对于较大的主干,定位比分类更困难,这说明早期特征更重要。而弱表示能力限制了这两个子任务对于极其微小的主干的准确性,这表明早期和晚期特征在这个层次上都是至关重要的。
Compressing RPN and Detection Head: Two-stage detectors usually adopt large RPN and a heavy detection head. Although Light-Head R-CNN [14] uses a lightweight detection head, it is still too heavy when coupled with small backbones and induces imbalance between the backbone and the detection part. This imbalance not only leads to redundant computation but increases the risk of overfitting.
Light-Head R-CNN应用GCN[23]生成thin feature map。它显著地增加了感受野,但涉及了巨大的计算成本。加上SNet146, GCN需要2×主干网所需的FLOPs (596M vs. 298M)。基于这个原因,我们决定在ThunderNet上放弃这个设计。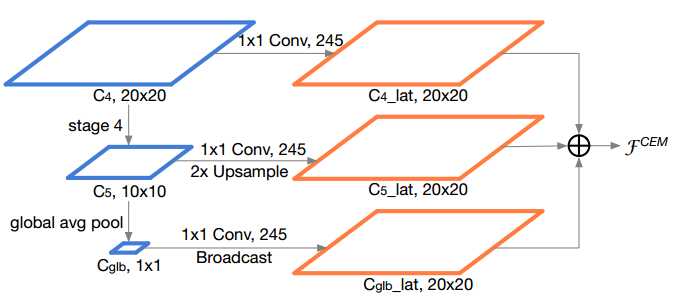
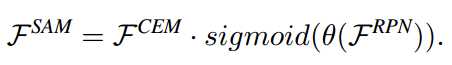
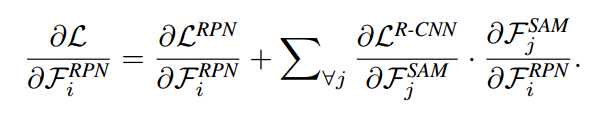
文章标题:ThunderNet: Towards Real-time Generic Object Detection
文章链接:http://soscw.com/index.php/essay/68883.html