flume与hdfs
2021-03-28 07:28
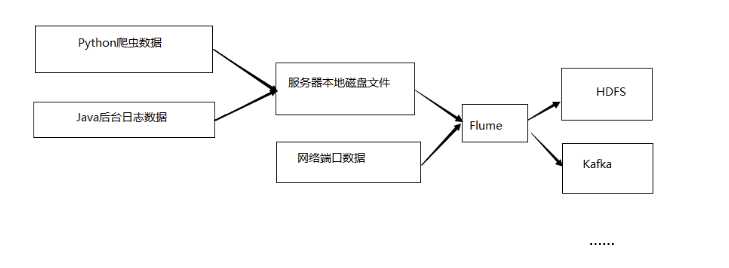
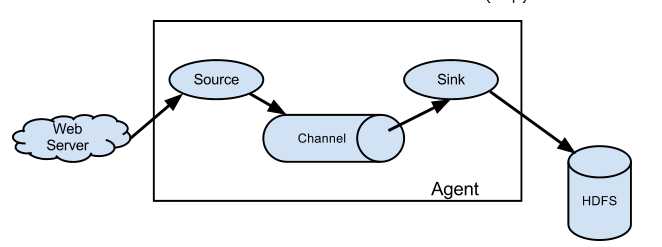
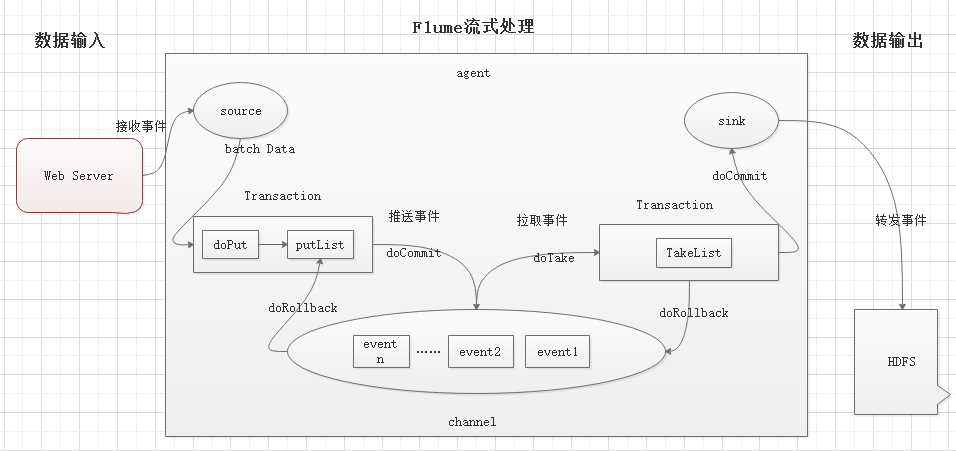
标签:direct 自定义 允许 src commit bsp 为什么 提取 flume Flume定义: Flume是Cloudera提供的一个高可用的、高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构, 灵活简单。 为什么选用Flume 主要作用: 实时读取服务器本地磁盘的数据, 将数据写入到HDFS Flume的组织架构 1、最简单的组织架构 2、Flume流式处理过程 说明: source: 数据输入端 常见类型: spooling directory, exec, syslog, avro, netcat等 channel:位于source和sink之间的缓冲区 memory: 基于内存缓存, 允许数据有丢失 file: 持久化channel, 系统宕机不会丢失数据 sink: 数据输出端 常见的目的地有: HDFS, Kafka, logger, avro, File, 自定义 Put事务流程: doPut: 将批数据写入临时缓冲区putList doCommit: 检查channel内存队列是否足够合并 doRollback: 内存队列空间不足, 回滚数据 Take事务流程: doTake: 将批数据提取到临时缓冲区takeList doCommit: 如果数据全部发送成功, 则清空临时缓冲区takeList doRollback: 如果数据发送过程中出现异常, 则将临时缓冲区takeList中数据返还给channel flume与hdfs 标签:direct 自定义 允许 src commit bsp 为什么 提取 flume 原文地址:https://www.cnblogs.com/kongzhagen/p/12623208.html