爬虫毕设(三):爬取动态网页
2021-03-28 16:24
标签:wing text actor strong pes js代码 subject spl strip 按照上一篇的分析,直接使用XPath找到该标签,然后通过parse提取出数据,在写入到item中就完事了。但是,当信心满满的写完代码后却发现,控制台输入了一个简简单单的 打开NetWork,找到 这是由于网页执行js代码,通过Ajax请求数据来重新渲染页面的。所以我们需要找到有数据的那一个请求,然后再对该请求的目标url爬取。 这次我们的思路是先拿到每部电视剧的url,然后再回调二次解析的函数获取详细信息。运行爬虫,可以看到我们已经得到了自己想要的结果。 然后整整二十部电视剧的简介疯狂刷屏: 爬虫毕设(三):爬取动态网页 标签:wing text actor strong pes js代码 subject spl strip 原文地址:https://www.cnblogs.com/bzsheng/p/12616967.html动态网页分析
[]。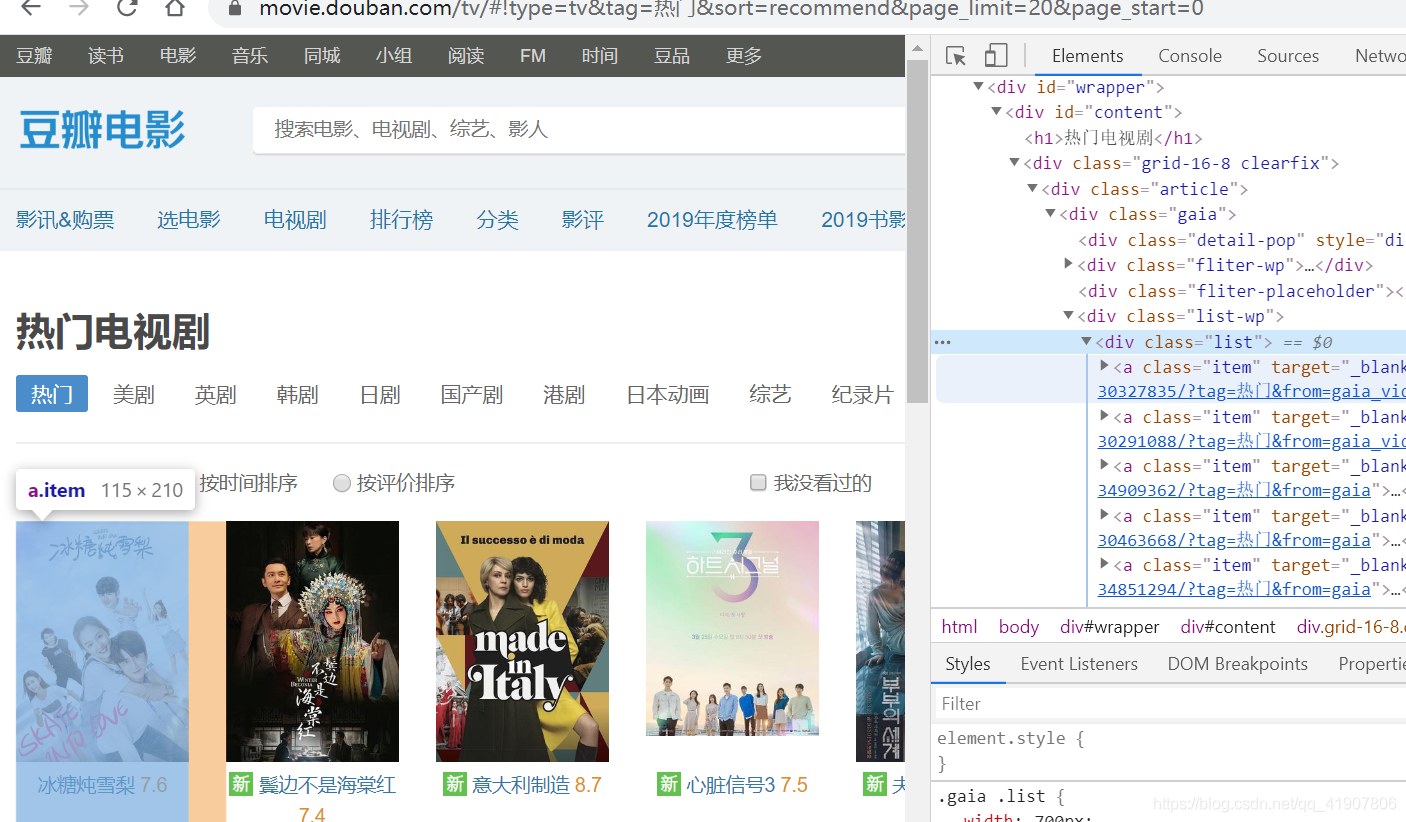
小问号你是否有很多朋友。
一顿操作猛如虎,一看输出数据无。那么这到底是怎么回事呢?我们从头开始分析。tv/,点开Preview,结果发现只有一个框架,内容却是空白的。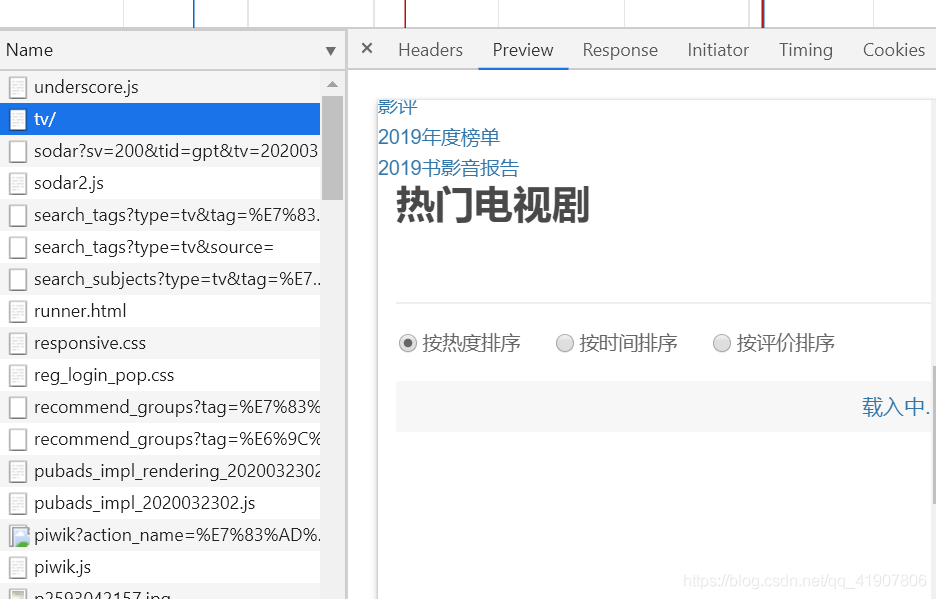
可以在preview中看到这就是我们想要的数据。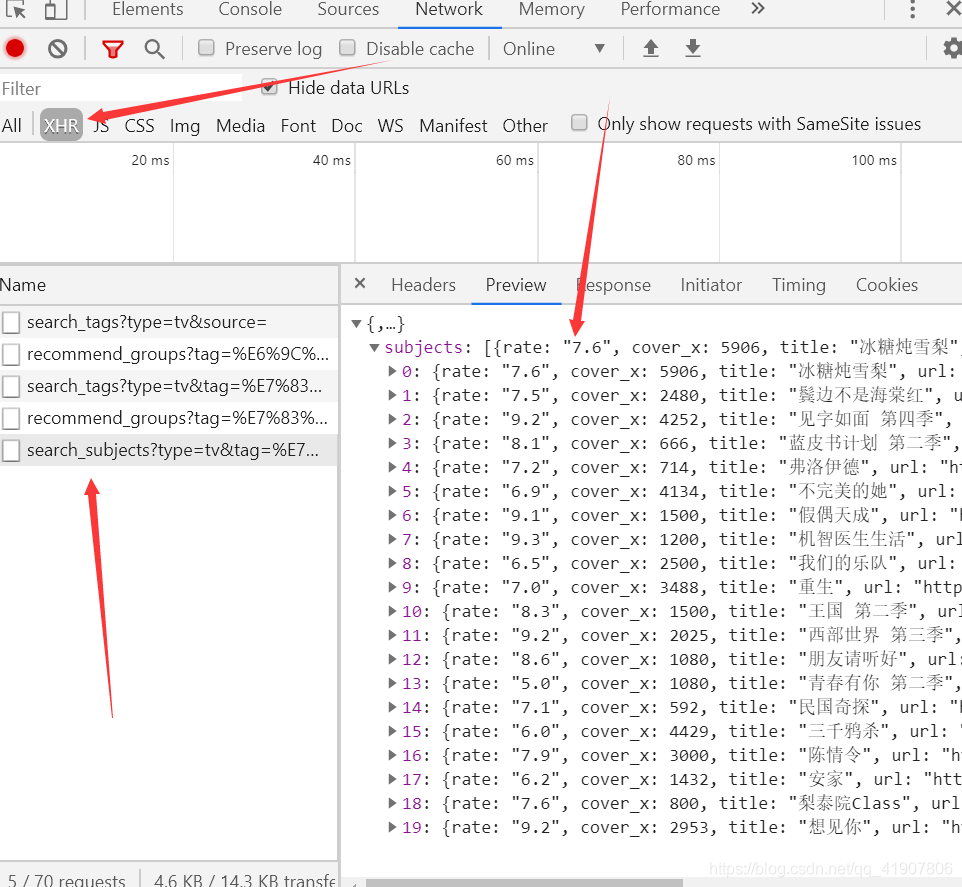
我们再找到该请求的header,找到Request URL。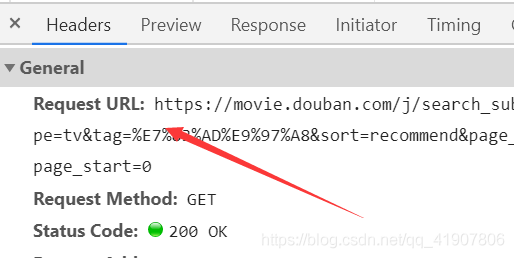
我们直接复制链接到地址栏中,看到我们想要的数据,这熟悉的格式,不就是json吗。
动手撸代码,爬取这个网页,处理json数据,拿到自己想要的数据。class tvSpider(scrapy.Spider):
name = "douban_tv"
allowed_domain = ["movie.douban.com"]
def __init__(self, *args, **kwargs):
super(tvSpider, self).__init__(*args, **kwargs)
self.start_urls = ["https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0"]
def parse(self, response):
results = json.loads(response.body)[‘subjects‘]
for result in results:
tv_item = TvListItem()
url = result[‘url‘]
tv_item[‘url‘] = url.strip()
print(url)
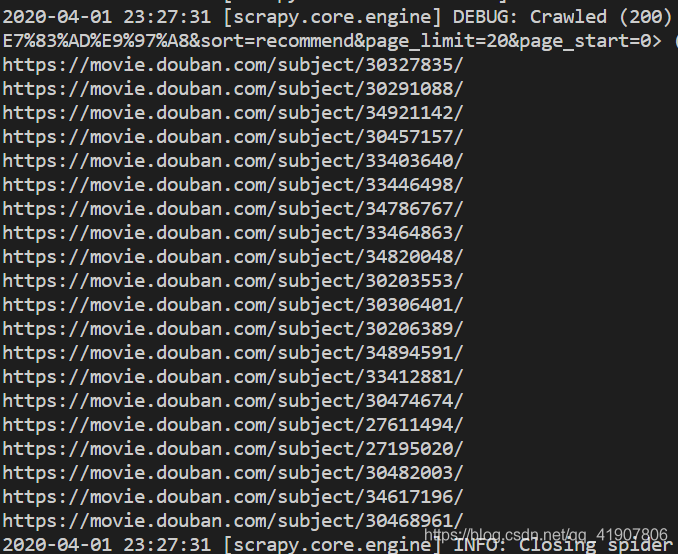 接下在就迭代使用
接下在就迭代使用scrapy.Request()请求每一个url,再使用二次解析函数parse_detait获取详细数据。
two years later。经过漫长的debug,终于得到以下代码代码: def parse_detail(self, response):
tv_item = response.meta[‘tv_item‘]
result = Selector(response)
# 字符串前加u表示处理中文字符
# 剧名
title = result.xpath(u‘//div[@id="content"]/h1/span[1]/text()‘).extract()[0] + result.xpath(‘//div[@id="content"]/h1/span[2]/text()‘).extract()[0]
# 又名
has_alias = result.xpath(u‘//div[@id="info"]//span[text()="又名:"]‘).extract()
if has_alias:
alias = result.xpath(u‘//div[@id="info"]//span[text()="又名:"]/following::text()[1]‘).extract()[0]
else:
alias = ‘‘
# 图片
tv_img = result.xpath(‘//a[@class="nbgnbg"]/img/@src‘).extract()[0]
# 导演
has_dir = result.xpath(‘//div[@id="content"]//span[text()="导演"]‘)
if has_dir:
directors = result.xpath(‘//div[@id="info"]//span[@class="attrs"]//a[@rel="v:directedBy"]/text()‘)
director_lsit = directors.extract()
director = ‘/‘.join(director_lsit)
# 主演
all_actors = result.xpath(‘//div[@id="info"]//span[@class="attrs"]//a[@rel="v:starring"]/text()‘)
actors_list = all_actors[:5].extract()
actors = ‘/‘.join(actors_list)
# 类型
tv_types = result.xpath(‘//div[@id="info"]//span[@property="v:genre"]/text()‘)
type_list = tv_types.extract()
tv_type = ‘/‘.join(type_list)
# 制片地区或国家
country_or_region = result.xpath(u‘//div[@id="info"]//span[text()="制片国家/地区:"]/following::text()[1]‘).extract()[0]
# 首播
first_time = result.xpath(‘//div[@id="content"]//span[@property="v:initialReleaseDate"]/text()‘).extract()[0]
# 集数
series = result.xpath(u‘//div[@id="content"]//span[text()="集数:"]/following::text()[1]‘).extract()[0]
# 单集
has_single = result.xpath(‘//div[@id="content"]//span[text()="单集片长:"]‘)
if has_single:
single = result.xpath(u‘//div[@id="content"]//span[text()="单集片长:"]/following::text()[1]‘).extract()[0]
# 评分
rate = result.xpath(‘//strong/text()‘).extract()[0]
# 评分人数
votes_num = result.xpath(‘//span[@property="v:votes"]/text()‘).extract()[0]
# 简介
synopsis = result.xpath(‘//span[@property="v:summary"]/text()‘).extract()[0].strip()
tv_item[‘title‘] = title.strip()
tv_item[‘alias‘] = alias.split()
tv_item[‘tv_img‘] = tv_img.strip()
tv_item[‘director‘] = director.strip()
tv_item[‘actors‘] = actors.strip()
tv_item[‘tv_type‘] = tv_type.strip()
tv_item[‘country_or_region‘] = country_or_region.strip()
tv_item[‘first_time‘] = first_time.strip()
tv_item[‘series‘] = series.strip()
tv_item[‘single‘] = single.strip()
tv_item[‘rate‘] = rate.strip()
tv_item[‘votes_num‘] = votes_num.strip()
tv_item[‘synopsis‘] = synopsis
print(‘电视剧信息>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>‘)
print(‘剧名:‘ + title)
print(‘又名:‘ + alias)
print(‘海报:‘ + tv_img)
print(‘导演:‘ + director)
print(‘主演:‘ + actors)
print(‘类型:‘ + tv_type)
print(‘制片国家或地区:‘ + country_or_region)
print(‘首播:‘ + first_time)
print(‘集数:‘ + series)
print(‘单集时长:‘ + single)
print(‘评分:‘ + rate)
print(‘评分人数:‘ + votes_num)
print(‘简介:‘ + synopsis)
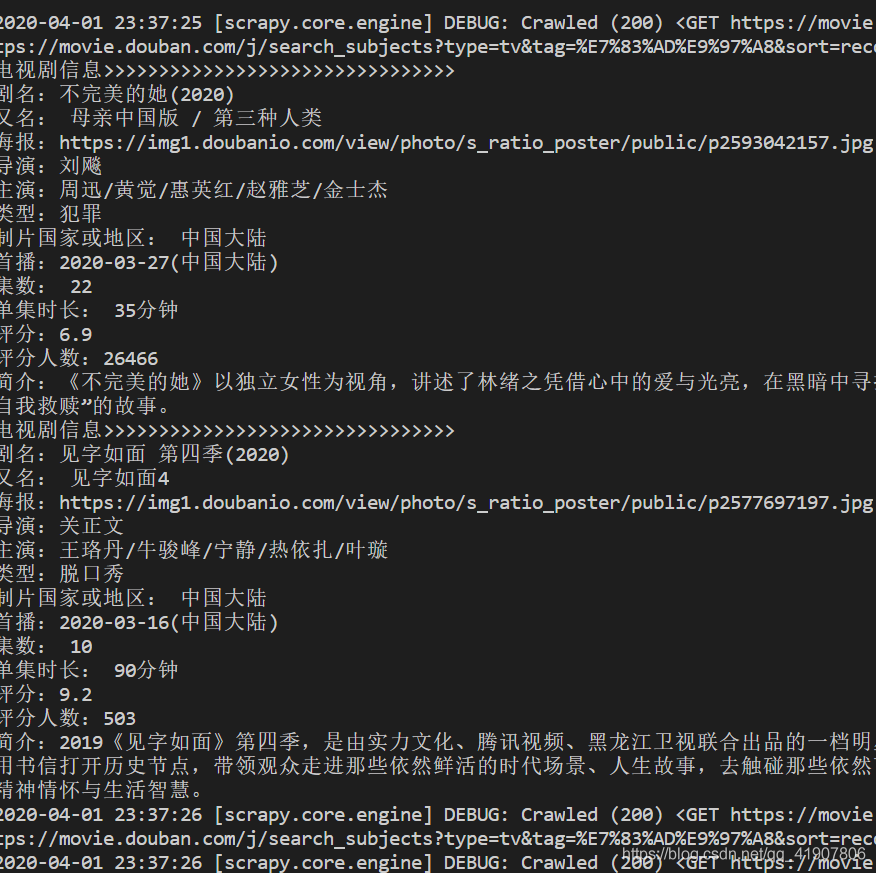
虽然经历了一番腰酸背痛,头眼昏花,问题好歹是解决了。
上一篇:java 获取真实IP
下一篇:url编解码