2、Namenode是如何启动web服务的
2021-03-29 07:27
标签:available interval rom 不难 nan get 观察 pause ati 首先Namenode启动的总体流程大概是这样的: 上一篇内容(https://www.cnblogs.com/niutao/p/12609621.html),分析是怎么从main函数走到initialize; 那么接下来要介绍的就是: 首先对initialize方法整体做个流程介绍 代码(有注释): 首先经历的流程是: 接下来在看下startHttpServer这个方法: 1、构建了NameNodeHttpServer 2、启动这个web服务 3、设置启动跟踪器 查看NameNodeHttpServer构造函数,会发现就是单纯的赋值操作: 然后观察httpServer.start()方法: 1、构建web的socket服务地址 2、封装自己的HttpServer2 3、绑定各种功能 4、绑定servlet 5、启动web服务 源码(注释): 在这里的流程大概就是: 程序会根据当前的role角色来判断是否是namenode , 如果是:则启动web服务 启动web服务过程中,首先要构建一个HttpServer2(基于HttpServer增强类),然后绑定各种servlet(每一个servlet都是一种功能); 然后启动http服务,对外提供方法的调用和页面的展示 从代码中(54行),setupServlets(httpServer, conf),不难看出: HttpServer2绑定了一堆servlet,定义好了接收哪些http请求,接收到了请求由谁来处理。 从此处不难看出,http也是一种RPC,因为它也可以实现不同进程方法的调用 到目前为止,我们大体接收了从namenode的启动到如何去启动namenode的HTTP服务 所以到现在为止,我们可以总结为: 对应的流程图大概是: 2、Namenode是如何启动web服务的 标签:available interval rom 不难 nan get 观察 pause ati 原文地址:https://www.cnblogs.com/niutao/p/12609742.html
NameNode.main() // 入口函数
|——createNameNode(); // 通过new NameNode()进行实例化
|——initialize(); // 方法进行初始化操作
|——startHttpServer(); // 启动HttpServer
|——loadNamesystem(); // 加载元数据
|——createRpcServer(); // 创建并初始化rpc server实例
|——startCommonServices();
|——namesystem.startCommonServices(); // 启动一些磁盘检查、安全模式等一些后台服务及线程
|——new NameNodeResourceChecker(); // 实例化一个NameNodeResourceChecker并准备出所有需要检查的磁盘路径
|——checkAvailableResources(); // 开始磁盘空间检查
|——NameNode.getStartupProgress(); // 获取StartupProgress实例用来获取NameNode各任务的启动信息
|——setBlockTotal(); // 设置所有的block,用于后面判断是否进入安全模式
|——blockManager.activate(); // 启动BlockManager里面的一堆关于block副本处理的后台线程
|——rpcServer.start(); // 启动rpcServer
|——join()
1、initialize内容
2、启动web服务
1、 在这个方法中执行了一系列的成员变量初始化
2、 进行安全认证
|-- 去配置文件中找,是否进行了安全认证,如果进行了安全认证,则校验
3、 启动namenode上的http服务
|-- hadoop在原有的http服务基础上自己进一步封装了HttpServer
|-- 然后在这儿里面启动了httpServer.start();
|--setupServlets(httpServer, conf) 从此处不难看出,http也是一种RPC,因为它也可以实现不同进程方法的调用
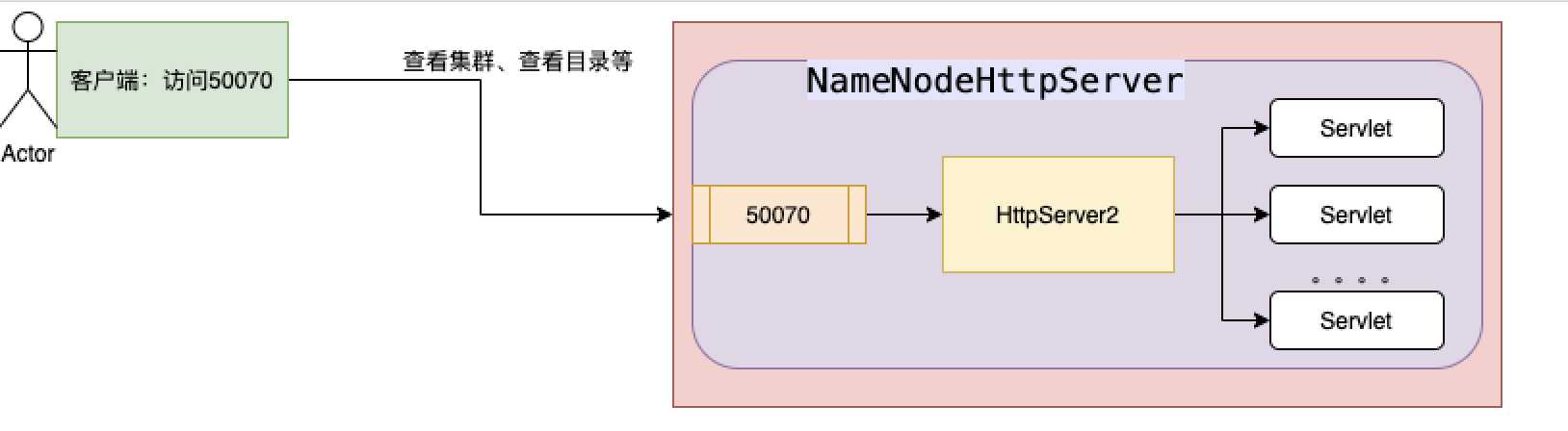
当然,这里面有我们比较熟悉的一些页面功能,都是通过httpServer实现的,比如:在50070页面浏览目录信息,就是通过这个 hadoop01:50070/listPaths/
4、 namenode启动时从本地文件系统加载镜像并重做编辑日志
loadNamesystem(conf);
(暂时不需要理这块儿,因为刚启动,namenode还没有什么元数据呢)
5、 创建hadoop的RPC服务
|-- rpcServer = createRpcServer(conf)
NameNodeRpcServer里面有两个主要的RPC服务:
1):clientRpcServer , 主要管理的协议是hdfs的客户端(用户)去操作HDFS的方法
2):ServletRpcServer , 服务之间互相进行的方法的调用(注册、心跳等)
因为 NameNodeRpcServer里面有两个主要的RPC服务 ,所以在这个构造方法中,hadoop也将clientRpcServer和ServletRpcServer构造出来,
并给对应的RPC上绑定了很多的协议
最后把ServletRpcServer和clientRpcServer的服务地址绑定给namenode
6、 startCommonServices(conf);
启动一些公共服务,NameNode的RPC服务就是在这里启动
1):进行资源的检查,检查是否有足够的磁盘来存储元数据
比如:hadoop-daemon.sh start namenode 这个时候就会检查存储元数据的磁盘,是否满足100M
2):进行安全模式检查,检查是否可以退出安全模式
|-- namesystem.startCommonServices(conf, haContext);
NameNode核心成员变量用来管理元数据(实现对DataNode、Block的管理以及读写日志)
|-- nnResourceChecker = new NameNodeResourceChecker(conf);
需要检查3个涉及到元数据的目录:
Namenode2个目录:fsimage、editlog(默认情况下这两个是在同一个目录)
高可用模式下的journalNode里面也有存储袁术的目录
|-- checkAvailableResources(); 检查可用资源是否足够:如果不够,日志打印警告信息,然后进入安全模式
(主要是检查存储元数据的磁盘空间是否大于100M,如果不大于就进入安全模式)
|-- setBlockTotal(); 设置所有的block,用于后面判断是否进入安全模式
|-- getCompleteBlocksTotal 获取所有正常使用的block个数
|-- total - numUCBlocks
|-- blockManager.activate(conf) /启动等待复制线程和启动管理心跳服务
|-- rpcServer.start(); 启动NameNodeRpcServer服务
protected void initialize(Configuration conf) throws IOException {
//设置metrics的监控间隔
if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
if (intervals != null) {
conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
intervals);
}
}
//设置权限,根据hadoop.security.authentication获取认证方式及规则
UserGroupInformation.setConfiguration(conf);
//登录:如果认证方式为simple则退出该方法
//否则调用UserGroupInformation.loginUserFromKeytab进行登陆,
// 登陆使用dfs.namenode.kerberos.principal作为用户名
loginAsNameNodeUser(conf);
//初始化度量系统,用于度量namenode服务状态
NameNode.initMetrics(conf, this.getRole());
StartupProgressMetrics.register(startupProgress);
if (NamenodeRole.NAMENODE == role) {
//启动namenode上的http服务
//hadoop01:50070
startHttpServer(conf);
}
//hadoop的跟踪器,默认不开启,生成htrace.out跟踪日志。
// 什么时候开启?比如Zipkin + hadoop,进行跟踪系统报告
this.spanReceiverHost = SpanReceiverHost.getInstance(conf);
//TODO 这一步很关键,根据命令对命名空间进行操作
/**
* 实际就是:加载本地fsimage和edits,在内存中建立命名空间的映像
* 但是最开始不会在此处做重点分析,后面再分析元数据管理阶段,会重点讲
* 因为,我们启动弄刚初始化,其实还没有什么元数据
* */
loadNamesystem(conf);
//TODO hadoop的RPC
/**
* NameNodeRpcServer里面有两个主要的RPC服务:
* 1):clientRpcServer , 主要管理的协议是hdfs的客户端(用户)去操作HDFS的方法
* 2):ServletRpcServer , 服务之间互相进行的方法的调用(注册、心跳等)
* */
rpcServer = createRpcServer(conf);
if (clientNamenodeAddress == null) {
// This is expected for MiniDFSCluster. Set it now using
// the RPC server‘s bind address.
clientNamenodeAddress =
NetUtils.getHostPortString(rpcServer.getRpcAddress());
LOG.info("Clients are to use " + clientNamenodeAddress + " to access"
+ " this namenode/service.");
}
if (NamenodeRole.NAMENODE == role) {
httpServer.setNameNodeAddress(getNameNodeAddress());
httpServer.setFSImage(getFSImage());
}
pauseMonitor = new JvmPauseMonitor(conf);
pauseMonitor.start();
metrics.getJvmMetrics().setPauseMonitor(pauseMonitor);
/**
* 启动一些公共服务,NameNode的RPC服务就是在这里启动
* 1):进行资源的检查,检查是否有足够的磁盘来存储元数据
* 比如:hadoop-daemon.sh start namenode 这个时候就会检查存储元数据的磁盘,是否满足100M
* 2):进行安全模式检查,检查是否可以退出安全模式
* */
startCommonServices(conf);
}
1、 在这个方法中执行了一系列的成员变量初始化
2、 进行安全认证
|-- 去配置文件中找,是否进行了安全认证,如果进行了安全认证,则校验
1 //设置metrics的监控间隔
2 if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
3 String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
4 if (intervals != null) {
5 conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
6 intervals);
7 }
8 }
9 //设置权限,根据hadoop.security.authentication获取认证方式及规则
10 UserGroupInformation.setConfiguration(conf);
11 //登录:如果认证方式为simple则退出该方法
12 //否则调用UserGroupInformation.loginUserFromKeytab进行登陆,
13 // 登陆使用dfs.namenode.kerberos.principal作为用户名
14 loginAsNameNodeUser(conf);
15 //初始化度量系统,用于度量namenode服务状态
16 NameNode.initMetrics(conf, this.getRole());
17 StartupProgressMetrics.register(startupProgress);
然后就会判断当前的角色role,是否是namenode来判断启动web服务
1 if (NamenodeRole.NAMENODE == role) {
2 //启动namenode上的http服务
3 //hadoop01:50070
4 startHttpServer(conf);
5 }
1 private void startHttpServer(final Configuration conf) throws IOException {
2 httpServer = new NameNodeHttpServer(conf, this, getHttpServerBindAddress(conf));
3 httpServer.start();
4 httpServer.setStartupProgress(startupProgress);
5 }
1 NameNodeHttpServer(Configuration conf, NameNode nn,
2 InetSocketAddress bindAddress) {
3 this.conf = conf;
4 this.nn = nn;
5 this.bindAddress = bindAddress;
6 }
1 void start() throws IOException {
2 //去hdfs-default.xml得到文本传输协议:HTTP_ONLY
3 HttpConfig.Policy policy = DFSUtil.getHttpPolicy(conf);
4 //得到namenode的页面访问IP地址,默认是:0.0.0.0
5 final String infoHost = bindAddress.getHostName();
6 //得到namenode的http页面访问地址:0.0.0.0/0.0.0.0:50070
7 final InetSocketAddress httpAddr = bindAddress;
8 //得到https服务的端口,默认是0.0.0.0:50470
9 final String httpsAddrString = conf.getTrimmed(
10 DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_KEY,
11 DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_DEFAULT);
12 //拼接https服务的url路径,既将:"/" + 0.0.0.0:50470
13 InetSocketAddress httpsAddr = NetUtils.createSocketAddr(httpsAddrString);
14 if (httpsAddr != null) {
15 //如果httpsAddr不为空,那么得到HTTPS的真实地址。bindHost
16 //TODO
17 // final String bindHost = conf.getTrimmed(DFSConfigKeys.DFS_NAMENODE_HTTPS_BIND_HOST_KEY);
18 final String bindHost = "localhost";
19 if (bindHost != null && !bindHost.isEmpty()) {
20 /**
21 * 根据HTTPS的真实地址,重构InetSocketAddress httpsAddr
22 * httpsAddr.getPort()默认是50470
23 * */
24 httpsAddr = new InetSocketAddress(bindHost, httpsAddr.getPort());
25 }
26 }
27 /**
28 * hadoop喜欢封装自己的东西,比如本来是有RPC的,但是hadoop会封装hadoopRPC
29 * 这里面也一样,hadoop封装自己的HttpServer2
30 * */
31 HttpServer2.Builder builder = DFSUtil.httpServerTemplateForNNAndJN(conf,
32 httpAddr, httpsAddr, "hdfs",
33 DFSConfigKeys.DFS_NAMENODE_KERBEROS_INTERNAL_SPNEGO_PRINCIPAL_KEY,
34 DFSConfigKeys.DFS_NAMENODE_KEYTAB_FILE_KEY);
35
36 httpServer = builder.build();
37
38 if (policy.isHttpsEnabled()) {
39 // assume same ssl port for all datanodes
40 InetSocketAddress datanodeSslPort = NetUtils.createSocketAddr(conf.getTrimmed(
41 DFSConfigKeys.DFS_DATANODE_HTTPS_ADDRESS_KEY, infoHost + ":"
42 + DFSConfigKeys.DFS_DATANODE_HTTPS_DEFAULT_PORT));
43 httpServer.setAttribute(DFSConfigKeys.DFS_DATANODE_HTTPS_PORT_KEY,
44 datanodeSslPort.getPort());
45 }
46
47 initWebHdfs(conf);
48
49 httpServer.setAttribute(NAMENODE_ATTRIBUTE_KEY, nn);
50 httpServer.setAttribute(JspHelper.CURRENT_CONF, conf);
51 /**
52 * 核心代码:HttpServer2绑定了一堆servlet,定义好了接收哪些http请求,接收到了请求由谁来处理。
53 * */
54 setupServlets(httpServer, conf);
55 /**启动httpServer服务,对外开发50070端口*/
56 httpServer.start();
57
58 int connIdx = 0;
59 if (policy.isHttpEnabled()) {
60 httpAddress = httpServer.getConnectorAddress(connIdx++);
61 conf.set(DFSConfigKeys.DFS_NAMENODE_HTTP_ADDRESS_KEY,
62 NetUtils.getHostPortString(httpAddress));
63 }
64
65 if (policy.isHttpsEnabled()) {
66 httpsAddress = httpServer.getConnectorAddress(connIdx);
67 conf.set(DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_KEY,
68 NetUtils.getHostPortString(httpsAddress));
69 }
70 }
NameNode.main() // 入口函数
|——createNameNode(); // 通过new NameNode()进行实例化
|——initialize(); // 方法进行初始化操作
|——startHttpServer(); // 启动HttpServer
|——httpServer = new NameNodeHttpServer(); // 通过实例化HttpServer进行启动
|——httpServer.start(); // 具体的一些启动细节:servlet等配置
|——setupServlets();
|——httpServer.start();
|——join()
文章标题:2、Namenode是如何启动web服务的
文章链接:http://soscw.com/index.php/essay/69422.html