19-json与pickle模块
2021-03-29 10:26
标签:python 哈哈哈 简单方法 monkey 入口 mic code ror 16px 1、序列化写入文件 2、反序列化读取文件 1、json格式不可与python混淆,str为双引号。 2、json中只有以上格式,不能识别某一语言所独有的类型。
3、json在python3.5以后,可以识别bytes类型,但只可读,不可写。(wb模式下,不可直接使用 json.dump(user_dict,f),其内部会将user_dict转换成str再写入,而此时系统分配的文件权限是b模式) 4、在json中出现中文,会以Unicode的二进制编码以字符串类型存入 在入口处打猴子补丁,不用改原代码,也无须在子文件中处处改为 import ujson as json 19-json与pickle模块 标签:python 哈哈哈 简单方法 monkey 入口 mic code ror 16px 原文地址:https://www.cnblogs.com/zhubincheng/p/12609113.html一、json模块
1.1 什么是序列化&反序列化
内存中的数据类型---->序列化---->特定的格式(json格式或者pickle格式)
内存中的数据类型
土办法:
{‘aaa‘:111}--->序列化str({‘aaa‘:111})----->"{‘aaa‘:111}"
{‘aaa‘:111}1.2 为何要序列化
序列化得到结果=>特定的格式的内容有两种用途
1、可用于存储=》用于存档
2、传输给其他平台使用=》跨平台数据交互
python java
列表 特定的格式 数组
强调:
针对用途1的特定一格式:可是一种专用的格式=》pickle只有python可以识别
针对用途2的特定一格式:应该是一种通用、能够被所有语言识别的格式=》json1.3 如何序列化与反序列化
# 示范1
import json
# 序列化
json_res=json.dumps([1,‘aaa‘,True,False])
print(json_res,type(json_res)) # "[1, "aaa", true, false]"
#
# 反序列化
l=json.loads(json_res)
print(l,type(l))
import json
# 序列化的结果写入文件的复杂方法
json_res=json.dumps([1,‘aaa‘,True,False])
# print(json_res,type(json_res)) # "[1, "aaa", true, false]"
with open(‘test.json‘,mode=‘wt‘,encoding=‘utf-8‘) as f:
f.write(json_res)
# 将序列化的结果写入文件的简单方法
with open(‘test.json‘,mode=‘wt‘,encoding=‘utf-8‘) as f:
json.dump([1,‘aaa‘,True,False],f)
# 从文件读取json格式的字符串进行反序列化操作的复杂方法
with open(‘test.json‘,mode=‘rt‘,encoding=‘utf-8‘) as f:
json_res=f.read()
l=json.loads(json_res)
print(l,type(l))
# 从文件读取json格式的字符串进行反序列化操作的简单方法
with open(‘test.json‘,mode=‘rt‘,encoding=‘utf-8‘) as f:
l=json.load(f)
print(l,type(l))
1.4 json格式
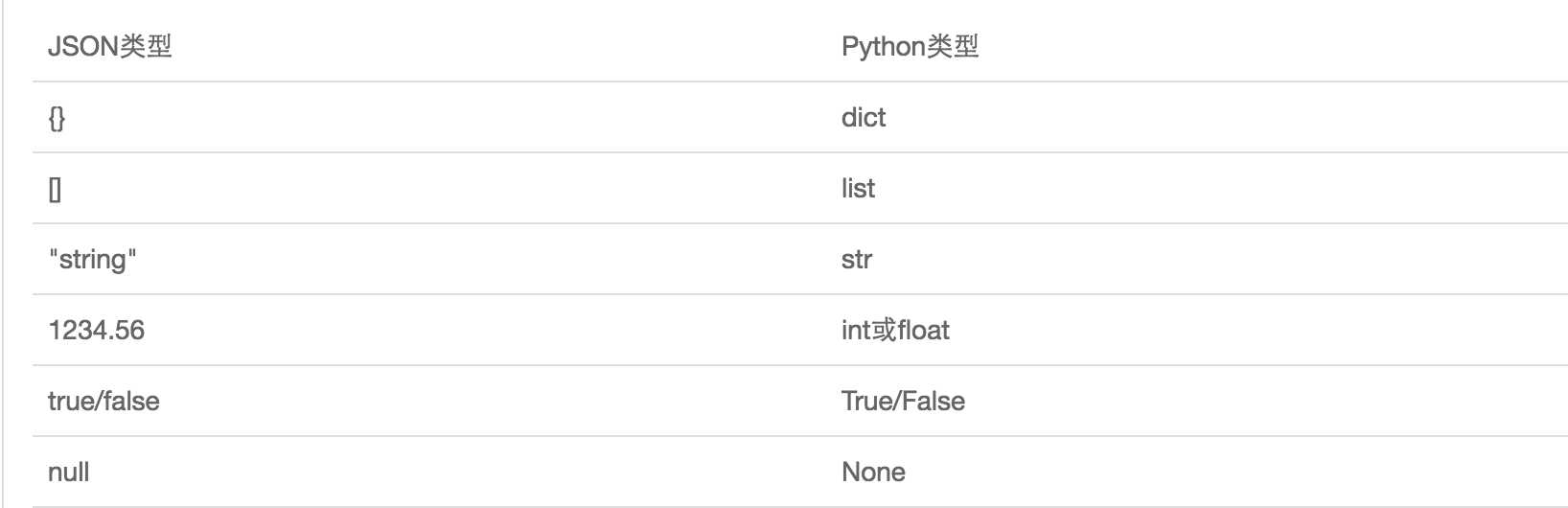
import json
# json验证: json格式兼容的是所有语言通用的数据类型,不能识别某一语言的所独有的类型
# json.dumps({1,2,3,4,5}) # error: Object of type set is not JSON serializable
# json强调:一定要搞清楚json格式,不要与python混淆
l=json.loads(‘[1, "aaa", true, false]‘) # corroct
l=json.loads("[1,1.3,true,‘aaa‘, true, false]") # error:json.decoder.JSONDecodeError: Expecting value: line 1 column 13 (char 12)
print(l[0])

l = json.loads(b‘[1, "aaa", true, false]‘)
print(l, type(l))
#
with open(‘test.json‘,mode=‘rb‘) as f:
l=json.load(f)
res=json.dumps({‘name‘:‘哈哈哈‘})
print(res,type(res)) # {"name": "\u54c8\u54c8\u54c8"}
1.5 猴子补丁
# 在入口处打猴子补丁
import json
import ujson
def monkey_patch_json():
json.__name__ = ‘ujson‘
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json() # 在入口文件出运行