静态路由算法 vs 动态路由算法
2021-03-29 12:28
标签:csdn 查表 base pat 数据包 环路 现在 ase sdn 动态路由算法大致可以分为两类: 下面我们来看一下这两类算法的特点: 距离矢量路由算法(Distance Vector Routing),它是网络上最早使用的动态路由算法,也称为Bellman-Ford或者Ford-Fulkerson算法。基于这类算法实现的协议有:RIP、BGP等。 每隔一段时间当前路由器会向所有的邻居节点发送自己的这个表,同时它也会接收每个邻居发来的它们的表。并会将邻居的表和自己的表做一个对比更新。 就这样继续类推,要不了多久,每个路由器就可以将网络中所有路由节点和子网线路都汇聚起来了。这样的话,每个路由器只需要查找自己的表就可以很容易的知道到达目的地的最佳出口(接口)是哪个了。 当然,当网络结构发生变化的时候,各个路由器中的矢量表也会随之动态更新。 好了,讲到这里,基本上对「距离矢量路由算法」大概原理有个认识了,现在我们再来仔细分析分析这个算法的名字,可以发现,它的名字取的还是蛮有意思的,非常贴切。“距离”这个词就基本表明了这个算法是通过 距离(跳数/时间)来度量2个路由网络之间的线路的,而“矢量”这个词,可以看出线路是有方向性的,且路由表中只记录了数据包去往目的地应该走哪个出口方向,并不会记录到达目的地的整条路径。 「距离矢量路由算法」的优点很明显:非常简单清晰,且任何加入到网络中的新节点都能很快的与其它节点建立起联系获得补充信息。 缺点呢,首先就是每次发送信息的时候,要发送整个全局路由表,太大了,因为每个路由器需要在矢量表中记录下整个网络的信息,导致需要较大存储、CPU、网络开销,对资源的要求越来越高。还有一个问题就是收敛时间太慢,也就是路由器共享路由信息并使各台路由器掌握的网络情况达到一致所需的时间比较久,收敛速度慢会导致有些路由器的表更新慢,从而造成路由环路的问题。 链路状态路由算法(Link State Routing ),基于Dijkstra算法,它是以图论作为理论基础,用图来表示网络拓扑结构,用图论中的最短路径算法来计算网络间的最佳路由。基于这类算法实现的协议有:OSPF 等。 这类算法的基本思路是:采用的是不停的拼接地图的方式。每一个路由器首先都会发现自己身边的邻居节点,然后将自己与邻居节点之间的链路状态包广播出去,发送到整个网络。这样,当某个路由器收到从网络中其它路由器广播来的路由信息包(链路状态包)之后,会将这个包中的信息与自己路由器上的信息进行拼装,最终形成一个全网的拓扑视图。 静态路由算法 vs 动态路由算法 标签:csdn 查表 base pat 数据包 环路 现在 ase sdn 原文地址:https://www.cnblogs.com/kakaisgood/p/13606600.html
静态路由算法主要有洪泛法,随机走动法,最短路径法,基于流量的路由算法
1.洪泛法(Flooding)
节点收到一个报文分组后,向所有可能的方向复制转发。每个节点不接受重复分组,网络局部故障也不影响通信,但大量重复分组加重了网络负担。这种方法适宜于网络规模小,通信负载轻,可靠性要求极高的通信场合——如军用通信中常用。
其改进方法是选择前进方向的扩散法,可大大减少重复分组的数量。
2.随机走动法(Random Walk)
节点收到分组后,向所有与之相邻的节点中为分组随机选择出一个节点转发出去;分组在网络中乱窜,总有可能到达。这种方法虽然简单,但不是最佳路由,通信效率低,分组传输延迟也不可预测,实用价值低。
3.最短路径法(Shortest Path,SP)
一般来讲,网络节点直接相连,传输时延也不是绝对最小,这与线路质量、网络节点“忙”与“闲”状态,节点处理能力等很多因素有关。定量分析中,常用“费用最小”作为网络节点之间选择依据,节点间的传输时延是决定费用的主要因素。
最短路径法,是由Dijkstra提出的,其基本思想是:将源节点到网络中所有节点的最短通路都找出来,作为这个节点的路由表,当网络的拓扑结构不变、通信量平稳时,该点到网络内任何其它节点的最佳路径都在它的路由表中。如果每一个节点都生成和保存这样一张路由表,则整个网络通信都在最佳路径下进行。每个节点收到分组后,查表决定向哪个后继节点转发。
4.基于流量的路由算法(Flow-based Routing,FR)
SP算法只考虑网络拓扑结构、寻找最短路径,没有考虑网络流量、负载对路由选择的影响,而FR算法就结合了网络拓扑结构和通信流量两方面的因素进行路由选择。
FR算法需要知道网络拓扑结构、节点之间的平均流量、各条线路的容量,然后在此基础上采用适当的选择算法,从而找出最佳路由。
FR算法的基本原理是根据知道一条线路的负荷和平均流量,用排队计算出该线路的分组平均时延,再由所有线路的平均时延直接计算出流量加权平均值,从而得到整个网络的平均分组时延。此方法可使网络通信量更加平衡,得到较小的平均分组时延。
一、距离矢量路由算法
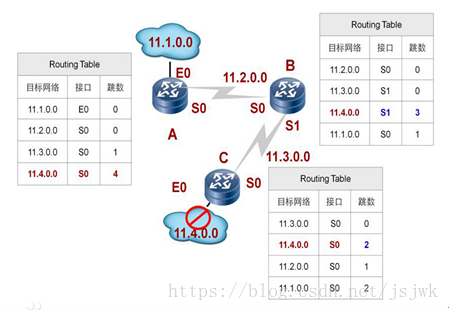
如图,
这类算法的基本思路是:网络中每一个路由器都要维护一张 矢量表 ,这个 矢量表 中的每一行都记录了从当前位置能到达的目标路由器的最佳出口(接口)和距离(跳数)。
比如当前 路由器X 离 邻居Y路由器 的距离是m,此时收到 邻居Y 发来的表中写到了“ 邻居Y离路由器Z的距离是n ”,那 当前路由器X 就知道它离 路由器Z 的距离可能就是 m+n 了,如图:
二、链路状态路由算法
如图,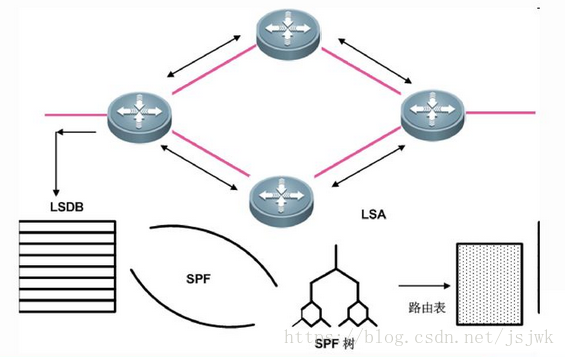
上一篇:数组实现一个简单的栈结构
下一篇:快速定位网站性能问题,提前下班!