一篇文章教会你利用Python网络爬虫实现豆瓣电影采集
2021-03-29 21:28
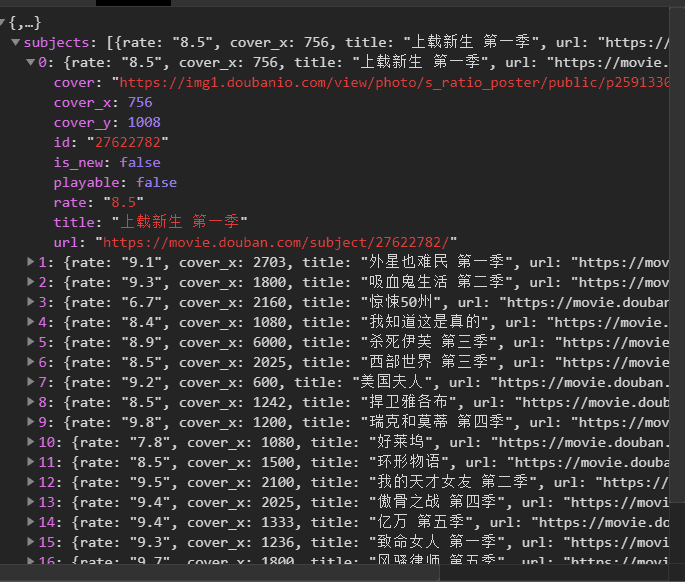
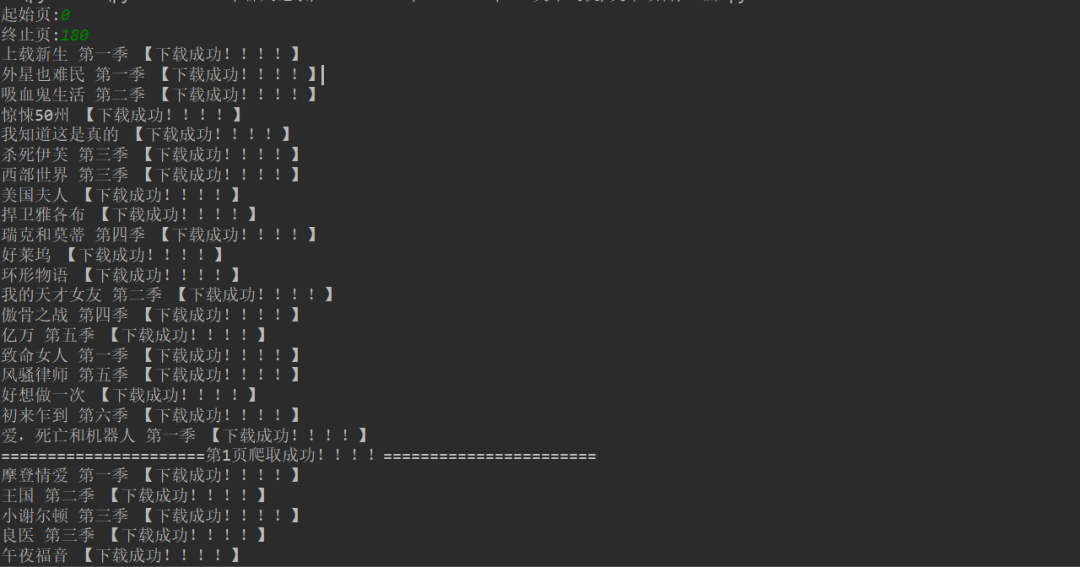
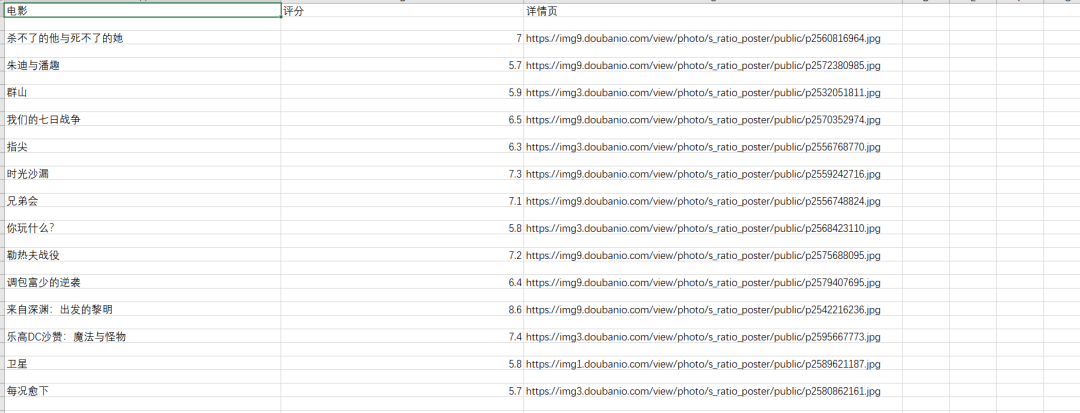
标签:一个 pre 标题 采集 gem 分析 mit obj review 豆瓣电影提供最新的电影介绍及评论包括上映影片的影讯查询及购票服务。可以记录想看、在看和看过的电影电视剧 、顺便打分、写影评。极大地方便了人们的生活。 今天以电视剧(美剧)为例,批量爬取对应的电影,写入csv文档 。用户可以通过评分,更好的选择自己想要的电影。 【二、项目目标】 获取对应的电影名称,评分,详情链接,下载 电影的图片,保存文档。 【三、涉及的库和网站】 1、网址如下: 2、涉及的库:requests**、fake_useragent、json**、csv 3、软件:PyCharm 【四、项目分析】 1、如何多网页请求? 点击下一页时,每增加一页paged自增加20,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。 2、如何获取真正请求的地址? 请求数据时,发现页面上并没有对应数据。其实豆瓣网采用javascript动态加载内容,防止采集。 1)F12右键检查,找到Network,左边菜单Name , 找到第五个数据,点击Preview。 2)点开subjects,可以看到 title 就是对应电影名称。rate就是对应评分。通过js解析subjects字典,找到需要的字段。 当点击下一页时,每增加一页page自增加20,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。 【五、项目实施】 1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。导入需要的库和请求网址。 2、随机产生UserAgent,构造请求头,防止反爬。 3、发送请求 ,获取响应,页面回调,方便下次请求。 4、json解析页面数据,获取对应的字典。 5、for遍历,获取对应的电影名、 评分、下详情页链接。 6、创建csv文件进行写入,定义对应的标题头内容,保存数据 。 7、图片地址进行请求。定义图片名称,保存文档。 8、调用方法,实现功能。 9、项目优化: 1)设置时间延时。 2)定义一个变量u, for遍历,表示爬取的是第几页。(更清晰可观)。 【六、效果展示】 1、点击绿色小三角运行输入起始页,终止页( ?从0页开始 )。 2、将下载成功信息显示在控制台。 3、保存csv文档。 4、电影图片展示。 【七、总结】 1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。 2、本文章就Python爬取豆瓣网,在应用中出现的难点和重点,以及如何防止反爬,做出了相对于的解决方案。 3、希望通过这个项目,能够帮助了解json解析页面的基本流程,字符串是如何拼接,format函数如何运用。 4、本文基于Python网络爬虫,利用爬虫库,实现豆瓣电影及其图片的获取。实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。 5、需要本文源码的小伙伴,后台回复“豆瓣电影”四个字,即可获取。 看完本文有收获?请转发分享给更多的人 IT共享之家 入群请在微信后台回复【入群】 一篇文章教会你利用Python网络爬虫实现豆瓣电影采集 标签:一个 pre 标题 采集 gem 分析 mit obj review 原文地址:https://blog.51cto.com/13389043/2526187https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}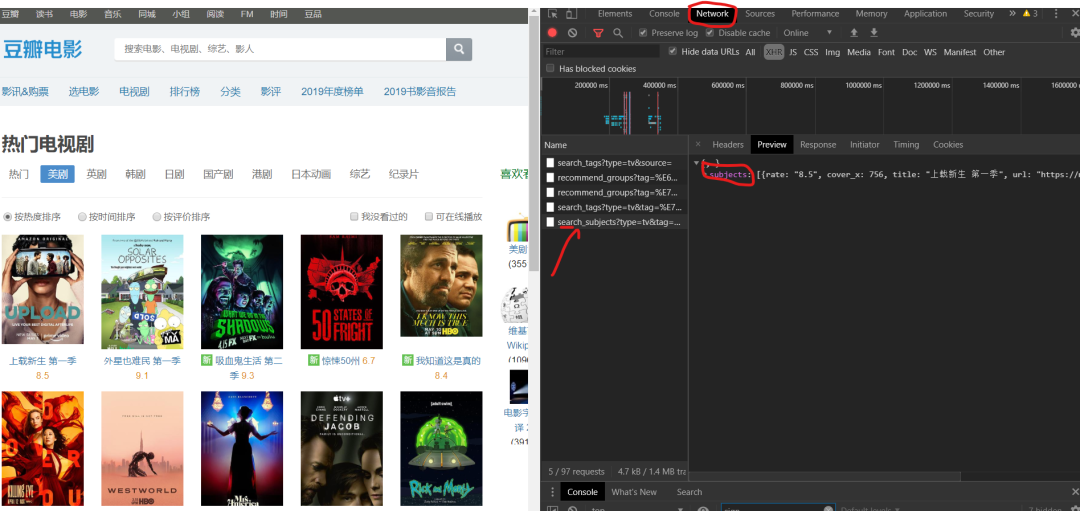
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
def main(self):
pass
if __name__ == ‘__main__‘:
Siper = Doban()
Siper.main()for i in range(1, 50):
self.headers = {
‘User-Agent‘: ua.random,
} def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html data = json.loads(html)[‘subjects‘]
# print(data[0]) print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath(‘//div[@class="entry"]/p/text()‘) # 创建csv文件进行写入
csv_file = open(‘scr.csv‘, ‘a‘, encoding=‘gbk‘)
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow([‘电影‘, ‘评分‘, "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll]) html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, ‘wb‘) as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id) html = self.get_page(url)
self.parse_page(html) time.sleep(1.4) u = 0
self.u += 1;
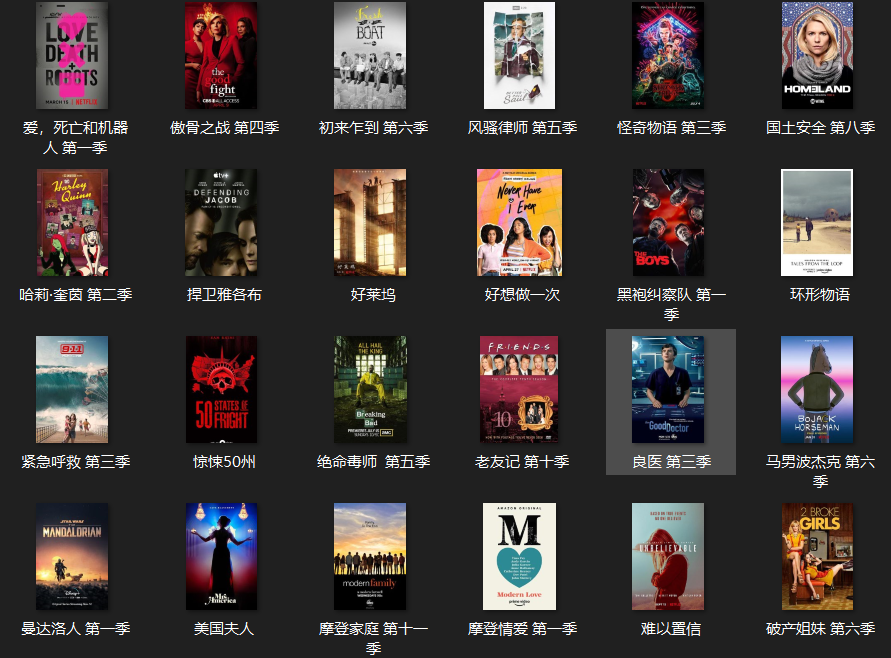

文章标题:一篇文章教会你利用Python网络爬虫实现豆瓣电影采集
文章链接:http://soscw.com/index.php/essay/69698.html