Fer2013 表情识别 pytorch (CNN、VGG、Resnet)
2021-03-30 04:26
标签:view 转换 宽高 技术 make 黑白 矩阵 return ide 让我们看看残差块的设计给我们带来…… 带来了更好的过拟合效果(逃 事已至此,我们浏览一下混淆矩阵 貌似除了开心和惊喜,其他表情准确率都挺一言难尽的,可能这两个比较好认,笑了就是开心,O型嘴就是惊喜,其他表情别说机器,人都不一定认得出 Fer2013 表情识别 pytorch (CNN、VGG、Resnet) 标签:view 转换 宽高 技术 make 黑白 矩阵 return ide 原文地址:https://www.cnblogs.com/weiba180/p/12600259.htmlfer2013数据集
数据集介绍

数据整理
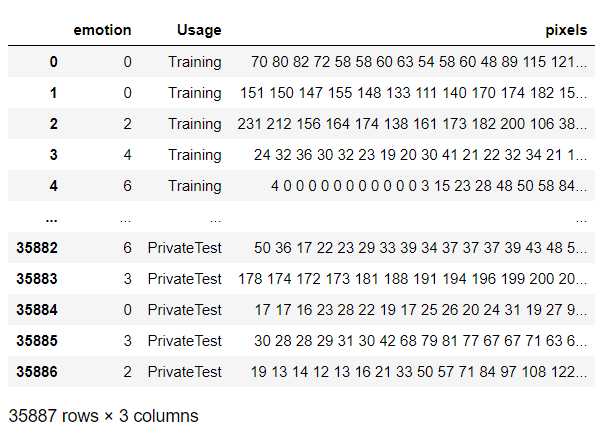
import numpy as np
import pandas as pd
from PIL import Image
import os
train_path = ‘./data/train/‘
vaild_path = ‘./data/vaild/‘
data_path = ‘./icml_face_data.csv‘
def make_dir():
for i in range(0,7):
p1 = os.path.join(train_path,str(i))
p2 = os.path.join(vaild_path,str(i))
if not os.path.exists(p1):
os.makedirs(p1)
if not os.path.exists(p2):
os.makedirs(p2)
def save_images():
df = pd.read_csv(data_path)
t_i = [1 for i in range(0,7)]
v_i = [1 for i in range(0,7)]
for index in range(len(df)):
emotion = df.loc[index][0]
usage = df.loc[index][1]
image = df.loc[index][2]
data_array = list(map(float, image.split()))
data_array = np.asarray(data_array)
image = data_array.reshape(48, 48)
im = Image.fromarray(image).convert(‘L‘)#8位黑白图片
if(usage==‘Training‘):
t_p = os.path.join(train_path,str(emotion),‘{}.jpg‘.format(t_i[emotion]))
im.save(t_p)
t_i[emotion] += 1
#print(t_p)
else:
v_p = os.path.join(vaild_path,str(emotion),‘{}.jpg‘.format(v_i[emotion]))
im.save(v_p)
v_i[emotion] += 1
#print(v_p)
make_dir()
save_images()
简单分析
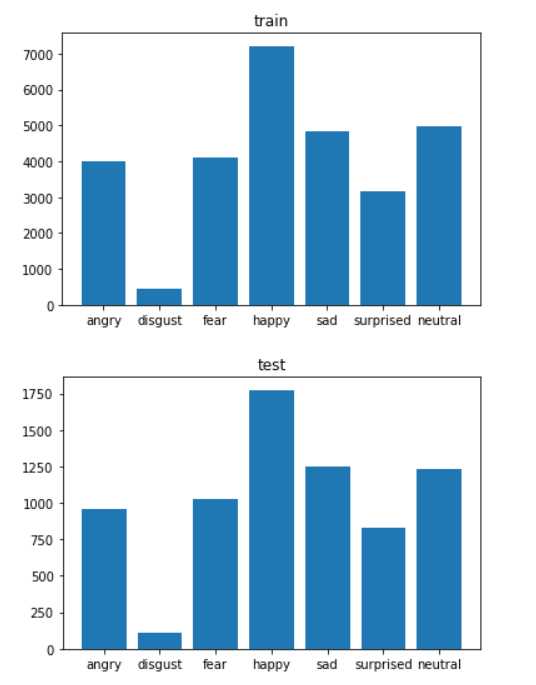
数据预处理
path_train = ‘./data/train/‘
path_vaild = ‘./data/vaild/‘
transforms_train = transforms.Compose([
transforms.Grayscale(),#使用ImageFolder默认扩展为三通道,重新变回去就行
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5),#随机调整亮度和对比度
transforms.ToTensor()
])
transforms_vaild = transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
data_train = torchvision.datasets.ImageFolder(root=path_train,transform=transforms_train)
data_vaild = torchvision.datasets.ImageFolder(root=path_vaild,transform=transforms_vaild)
train_set = torch.utils.data.DataLoader(dataset=data_train,batch_size=BATCH_SIZE,shuffle=True)
vaild_set = torch.utils.data.DataLoader(dataset=data_vaild,batch_size=BATCH_SIZE,shuffle=False)
for i in range(1,16+1):
plt.subplot(4,4,i)
plt.imshow(data_train[0][0],cmap=‘Greys_r‘)
plt.axis(‘off‘)
plt.show()

CNN
模型搭建
CNN = nn.Sequential(
nn.Conv2d(1,64,3),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(64,256,3),
nn.ReLU(True),
nn.MaxPool2d(3,3),
Reshape(),# 两个卷积和池化后,tensor形状为(batchsize,256,7,7)
nn.Linear(256*7*7,4096),
nn.ReLU(True),
nn.Linear(4096,1024),
nn.ReLU(True),
nn.Linear(1024,7)
)
class Reshape(nn.Module):
def __init__(self, *args):
super(Reshape, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
训练效果
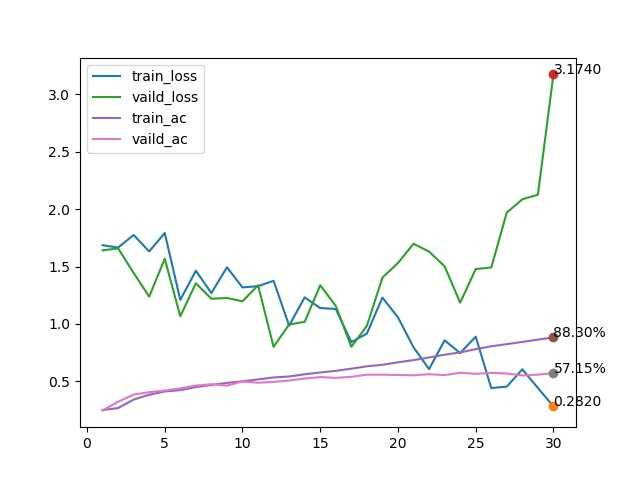
VGG
模型搭建
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
Reshape(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
conv_arch = ((1, 3, 32), (1, 32, 64), (2, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 1024
model = vgg(conv_arch, fc_features, fc_hidden_units)
训练效果
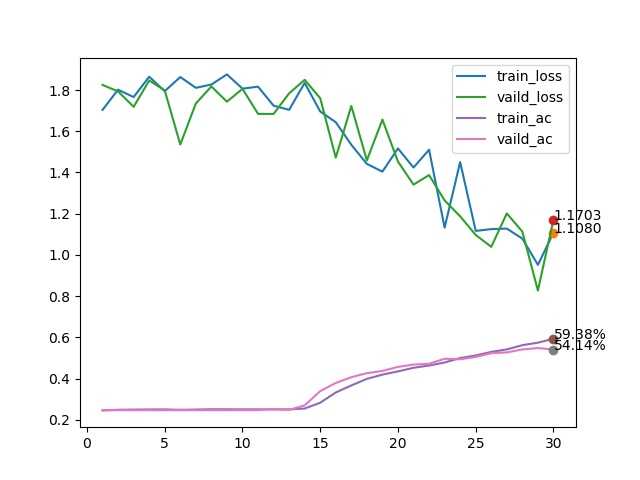
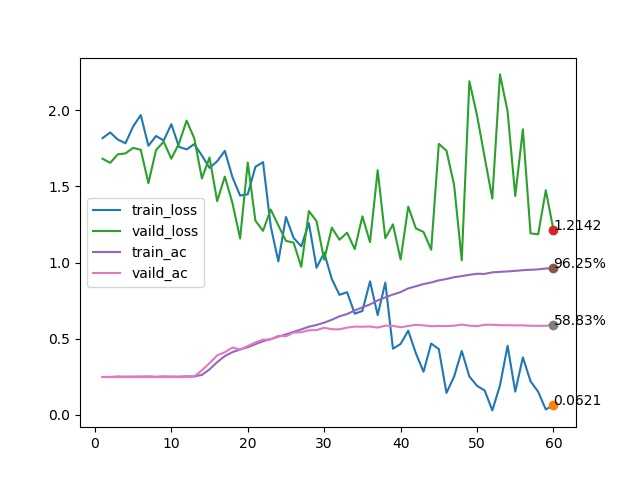
Resnet
模型搭建
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
net = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
net.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
net.add_module("fc", nn.Sequential(Reshape(), nn.Linear(512, 7)))
训练效果
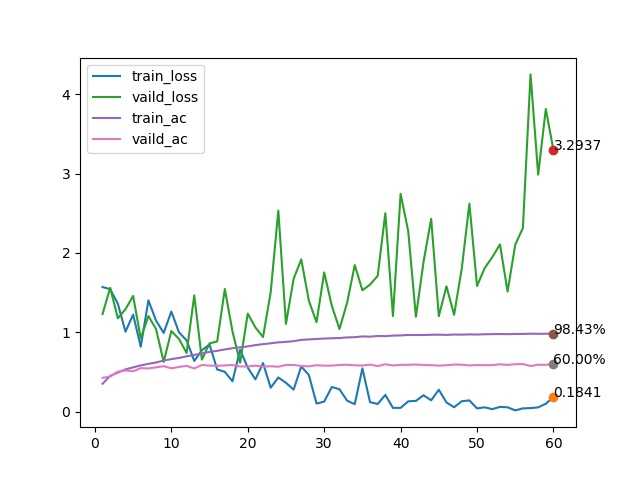
总结
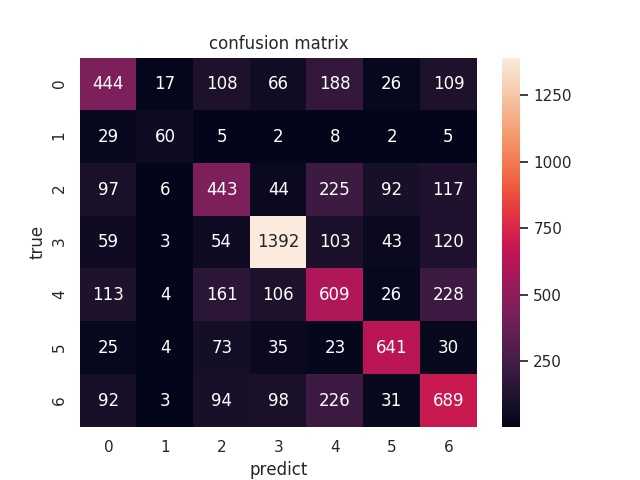

文章标题:Fer2013 表情识别 pytorch (CNN、VGG、Resnet)
文章链接:http://soscw.com/index.php/essay/69827.html