Apache Druid 底层存储设计(列存储与全文检索)
2021-03-30 07:26
标签:描述 调整 apach col schema 构建 数据模型 结构 维度 导读:首先你将通过这篇文章了解到 Apache Druid 底层的数据存储方式。其次将知道为什么 Apache Druid 兼具数据仓库,全文检索和时间序列的特点。最后将学习到一种优雅的底层数据文件结构。 今日格言:优秀的软件,从模仿开始的原创。 了解过 Apache Druid 或之前看过本系列前期文章的同学应该都知道 Druid 兼具数据仓库,全文检索和时间序列的能力。那么为什么其可以具有这些能力,Druid 在实现这些能力时做了怎样的设计和努力? Druid 的底层数据存储方式就是其可以实现这些能力的关键。本篇文章将为你详细讲解 Druid 底层文件 Segment 的组织方式。 带着问题阅读: Druid 将数据存储在 segment 文件中,segment 文件按时间分区。在基本配置中,将为每一个时间间隔创建一个 segment 文件,其中时间间隔可以通过 下面将描述 segment 文件的内部数据结构,该结构本质上是列式的,每一列数据都放置在单独的数据结构中。通过分别存储每个列,Druid 可以通过仅扫描实际需要的那些列来减少查询延迟。 Druid 共有三种基本列类型:时间戳列,维度列和指标列,如下图所示: 为什么需要这三种数据结构? 为了具体了解这些数据结构,考虑上面示例中的“page”列,下图说明了表示该维度的三个数据结构。 注意 如果数据源使用多值列,则 segment 文件中的数据结构看起来会有所不同。假设在上面的示例中,第二行同时标记了“ Ke \$ ha” 和 “ Justin Bieber”主题。在这种情况下,这三个数据结构现在看起来如下: 注意列数据和 segment 标识通常由 在底层,一个 segment 由下面几个文件组成: 这些文件中存储着一系列二进制数据。 这些 还有一个特殊的列,称为 在代码库中,segment 具有内部格式版本。当前的 segment 格式版本为 每列存储为两部分: ColumnDescriptor 本质上是一个对象。它由一些有关该列的元数据组成(它是什么类型,它是否是多值的,等等),然后是可以反序列化其余二进制数的序列化/反序列化 list。 对于同一数据源,在相同的时间间隔内可能存在多个 segment。这些 segment 形成一个 在对时间间隔的查询 该规则的例外是使用线性分片规范。线性分片规范不会强制“完整性”,即使分片未加载到系统中,查询也可以完成。例如,如果你的实时摄取创建了 3 个使用线性分片规范进行分片的 segment,并且系统中仅加载了两个 segment,则查询将仅返回这 2 个 segment 的结果。 Druid 使用 datasource,interval,version 和 partition number 唯一地标识 segment。如果在一段时间内创建了多个 segment,则分区号仅在 segment ID 中可见。例如,如果你有一个一小时时间范围的 segment,但是一个小时内的数据量超过单个 segment 所能容纳的时间,则可以在同一小时内创建多个 segment。这些 segment 将共享相同的 datasource,interval 和 version,但 partition number 线性增加。 在上面的示例 segment 中,dataSource = foo,interval = 2015-01-01 / 2015-01-02,version = v1,partitionNum =0。如果在以后的某个时间点,你使用新的模式重新索引数据,新创建的 segment 将具有更高的版本 ID。 Druid 批量索引(基于 Hadoop 或基于 IndexTask 的索引)可确保每个间隔的原子更新。在我们的示例中,在将所有 请注意,跨越多个 segment 间隔的更新仅是每个间隔内具有原子性。在整个更新过程中,它们不是原子的。例如,当你具有以下 segment: 在 在这种情况下,查询可能会同时出现 同一数据源的 segment 可能具有不同的 schema。如果一个 segment 中存在一个字符串列(维),但另一个 segment 中不存在,则涉及这两个 segment 的查询仍然有效。缺少维的 segment 查询将表现得好像维只有空值。同样,如果一个 segment 包含一个数字列(指标),而另一部分则没有,则对缺少该指标的 segment 的查询通常会“做正确的事”。缺少该指标的聚合的行为就好像该指标缺失。 *请持续关注,后期将为你拓展更多知识。对 Druid 感兴趣的同学也可以回顾我之前的系列文章。 关注公众号 MageByte,设置星标点「在看」是我们创造好文的动力。后台回复 “加群” 进入技术交流群获更多技术成长。 Apache Druid 底层存储设计(列存储与全文检索) 标签:描述 调整 apach col schema 构建 数据模型 结构 维度 原文地址:https://blog.51cto.com/14745561/2483051
Segment 文件
granularitySpec的segmentGranularity参数配置。为了使 Druid 在繁重的查询负载下正常运行,segment 的文件大小应该在建议的 300mb-700mb 范围内。如果你的 segment 文件大于这个范围,那么可以考虑修改时间间隔粒度或是对数据分区,并调整partitionSpec的targetPartitonSize参数(这个参数的默认值是 500 万行)。数据结构
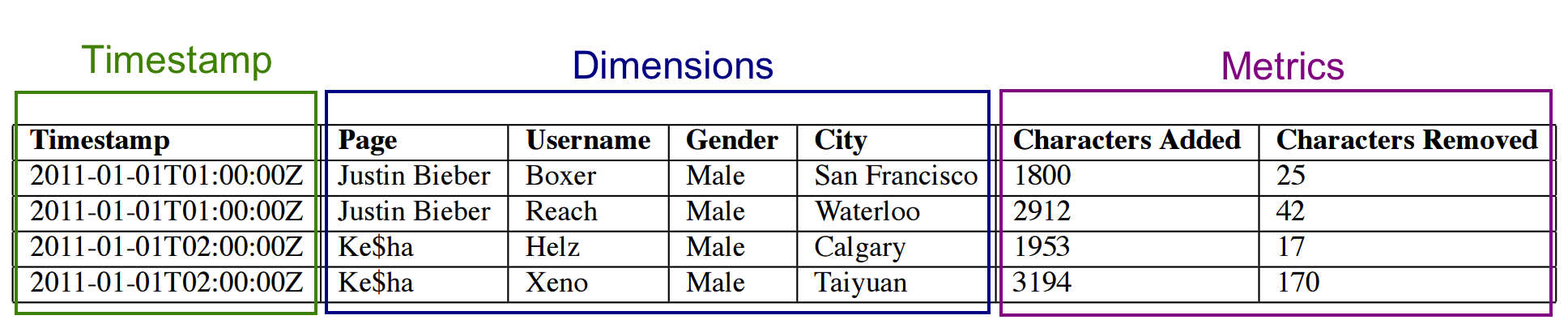
timestamp和metric列很简单:在底层,它们都是由 LZ4 压缩的 interger 或 float 的数组。一旦查询知道需要选择的行,它就简单的解压缩这些行,取出相关的行,然后应用所需的聚合操作。与所有列一样,如果查询不需要某一列,则该列的数据会被跳过。维度列就有所不同,因为它们支持过滤和分组操作,所以每个维度都需要下列三种数据结构:
字典仅将字符串映射成整数 id,以便可以紧凑的表示 2 和 3 中的值。3 中的bitmap也称为反向索引,允许快速过滤操作(特别是,位图便于快速进行 AND 和 OR 操作)。最后,group by和TopN需要 2 中的值列表,换句话说,仅基于过滤器汇总的查询无需查询存储在其中的维度值列表。1: 编码列值的字典
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2: 列数据
[0,0,1,1]
3: Bitmaps - 每个列唯一值对应一个
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,0,1,1]bitmap和前两种数据结构不同:前两种在数据大小上呈线性增长(在最坏的情况下),而 bitmap 部分的大小则是数据大小和列基数的乘积。压缩将在这里为我们提供帮助,因为我们知道,对于“列数据”中的每一行,只有一个位图具有非零的条目。这意味着高基数列将具有极为稀疏的可压缩高度位图。Druid 使用特别适合位图的压缩算法来压缩 bitmap,如roaring bitmap compressing(有兴趣的同学可以深入去了解一下)。1: 编码列值的字段
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2: 列数据
[0,
[0,1], Ke$ha位图中第二行的更改,如果一行的一个列有多个值,则其在“列数据“中的输入是一组值。此外,在”列数据“中具有 n 个值的行在位图中将具有 n 个非零值条目。命名约定
数据源,间隔开始时间(ISO 8601 format),间隔结束时间(ISO 8601 format)和版本号构成。如果数据因为超出时间范围被分片,则 segment 标识符还将包含分区号。如下:segment identifier=datasource_intervalStart_intervalEnd_version_partitionNumSegment 文件组成
version.bin
4 个字节,以整数表示当前 segment 的版本。例如,对于 v9 segment,版本为 0x0, 0x0, 0x0, 0x9。meta.smoosh
存储关于其他 smooth 文件的元数据(文件名和偏移量)。XXXXX.smoothsmoosh文件代表一起被“ smooshed”的多个文件,分成多个文件可以减少必须打开的文件描述符的数量。它们的大小最大 2GB(以匹配 Java 中内存映射的 ByteBuffer 的限制)。这些smoosh文件包含数据中每个列的单独文件,以及index.drd带有有关该 segment 的额外元数据的文件。__time,是该 segment 的时间列。v9。列格式
分片数据
分片
block间隔。根据shardSpec来配置分片数据,仅当block完成时,Druid 查询才可能完成。也就是说,如果一个块由 3 个 segment 组成,例如:sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_0
sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_1
sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_22011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z完成之前,必须装入所有 3 个 segment。模式变更
替换 segment
foo_2015-01-01/2015-01-02_v1_0
foo_2015-01-01/2015-01-02_v1_1
foo_2015-01-01/2015-01-02_v1_2foo_2015-01-01/2015-01-02_v2_0
foo_2015-01-01/2015-01-02_v2_1
foo_2015-01-01/2015-01-02_v2_2v2segment2015-01-01/2015-01-02都加载到 Druid 集群中之前,查询仅使用v1segment。一旦v2加载了所有 segment 并可以查询,所有查询将忽略v1segment 并切换到这些v2segment。之后不久,v1segment 将被集群卸载。foo_2015-01-01/2015-01-02_v1_0
foo_2015-01-02/2015-01-03_v1_1
foo_2015-01-03/2015-01-04_v1_2v2构建完并替换掉v1segment 这段时间期内,v2segment 将被加载进集群之中。因此在完全加载v2segment 之前,群集中可能同时存在v1和v2segment。foo_2015-01-01/2015-01-02_v1_0
foo_2015-01-02/2015-01-03_v2_1
foo_2015-01-03/2015-01-04_v1_2v1和和v2segment。segment 多个不同模式
最后
一、文章开头的问题,你是否已经有答案
二、知识扩展
roaring bitmap compressing压缩算法。

文章标题:Apache Druid 底层存储设计(列存储与全文检索)
文章链接:http://soscw.com/index.php/essay/69886.html