怎么用Python画出好看的词云图?
2021-03-30 09:25
标签:没有 目标 最大的 哪些 生成 分词 分析师 enc 第一时间 点击上方“Python读数”,选择“星标”公众号 上面的这种图叫做词云图,主要用途是将文本数据中出现频率较高的关键词以可视化的形式展现出来,使人一眼就可以领略文本数据的主要表达意思。词云图中,词的大小代表了其词频,越大的字代表其出现频率更高。 明天就过年了,所以我也特地去找了几首新年歌,将它们的歌词汇总起来作为本次展示用的文本数据,大家可以看看新年歌中哪些词的出现频率比较高。我们先绘制一个比较简单的词云图: 一张简单的词云图就成功生成啦,但看起来好像并没有特别好看,怎么生成带特定形状的词云呢? 想生成带特定形状的词云,首先得准备一张该形状的图片,且除了目标形状外,其他地方都是空白的,如下面这张用于演示的图。 上图中除了福字之外都是白色的,准备好之后就上代码 代码部分和普通的图基本一致,区别在于要导入相应形状的图片,并在wordcloud设置了mask参数。 是不是还挺简单的,借这张图也祝福大家2020年都福气满满! 往期精彩回顾 互联网寒冬下,数据分析师还吃香吗? 大话NBA | 用数据带你回顾乔丹的职业生涯 可转债打新能赚钱吗?Python数据分析告诉你! 你点的每个“在看”,是对我最大的鼓励 怎么用Python画出好看的词云图? 标签:没有 目标 最大的 哪些 生成 分词 分析师 enc 第一时间 原文地址:https://blog.51cto.com/14915204/2525823
重磅干货,第一时间送达
相信很多人在第一眼看到下面这些图时,都会被其牛逼的视觉效果所吸引,这篇文章就教大家怎么用Python画出这种图。
前期准备
那生成一张词云图的主要步骤有哪些?过程中又需要用到哪些Python库呢?
1.首先需要一份待分析的文本数据,由于文本数据都是一段一段的,所以第一步要将这些句子或者段落划分成词,这个过程称之为分词,需要用到Python中的分词库jieba。
2.分词之后,就需要根据分词结果生成词云,这个过程需要用到wordcloud库
3.最后需要将生成的词云展现出来,用到大家比较熟悉的matplotlib
理清了词云图绘制的主要脉络之后,下面就用代码操作起来。小试牛刀
# 导入相应的库
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 导入文本数据并进行简单的文本处理
# 去掉换行符和空格
text = open("./data/新年歌.txt",encoding=‘utf8‘).read()
text = text.replace(‘\n‘,"").replace("\u3000","")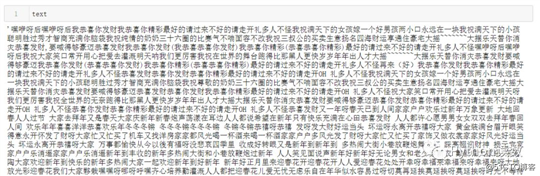
# 分词,返回结果为词的列表
text_cut = jieba.lcut(text)
# 将分好的词用某个符号分割开连成字符串
text_cut = ‘ ‘.join(text_cut)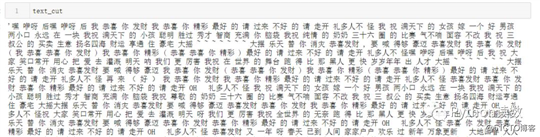
# 导入停词
# 用于去掉文本中类似于‘啊‘、‘你‘,‘我‘之类的词
stop_words = open("F:/NLP/chinese corpus/stopwords/stop_words_zh.txt",encoding="utf8").read().split("\n")
# 使用WordCloud生成词云
word_cloud = WordCloud(font_path="simsun.ttc", # 设置词云字体
background_color="white", # 词云图的背景颜色
stopwords=stop_words) # 去掉的停词
word_cloud.generate(text_cut)
# 运用matplotlib展现结果
plt.subplots(figsize=(12,8))
plt.imshow(word_cloud)
plt.axis("off")
登堂入室

import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
text = open("./data/新年歌.txt",encoding=‘utf8‘).read()
text = text.replace(‘\n‘,"").replace("\u3000","")
text_cut = jieba.lcut(text)
text_cut = ‘ ‘.join(text_cut)
stop_words = open("F:/NLP/chinese corpus/stopwords/stop_words_zh.txt",encoding="utf8").read().split("\n")
# 主要区别
background = Image.open("./data/background.png")
graph = np.array(background)
word_cloud = WordCloud(font_path="simsun.ttc",
background_color="white",
mask=graph, # 指定词云的形状
stopwords=stop_words)
word_cloud.generate(text_cut)
plt.subplots(figsize=(12,8))
plt.imshow(word_cloud)
plt.axis("off")
生成的词云图如下:
最后的最后,祝大家

文章标题:怎么用Python画出好看的词云图?
文章链接:http://soscw.com/index.php/essay/69917.html