Python爬虫——基于xpath爬取58同城房源信息!
2021-03-30 12:25
标签:safari gecko pytho byte fan idt https int pre 获取58同城上所有房源的标题信息 使用抓包工具进行分析 发现所有的房源标题信息,均存在于ul属性class=house-list-wrap下的li标题中 用xpath形式写为://ul[@class=“house-list-wrap”]/li 用xpath形式写为://ul[@class=“house-list-wrap”]/li/div[2]/h2/a/text() Python爬虫——基于xpath爬取58同城房源信息! 标签:safari gecko pytho byte fan idt https int pre 原文地址:https://www.cnblogs.com/A3535/p/13582263.html1、需求
https://bj.58.com/ershoufang/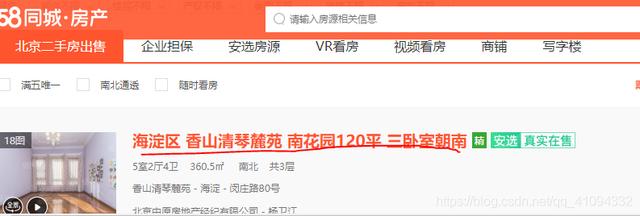
2、分析
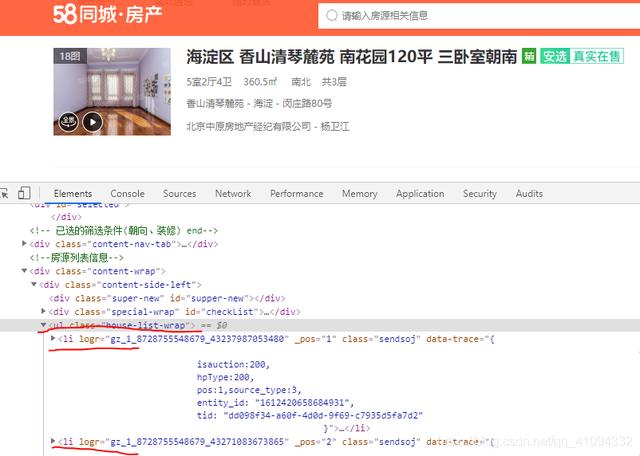
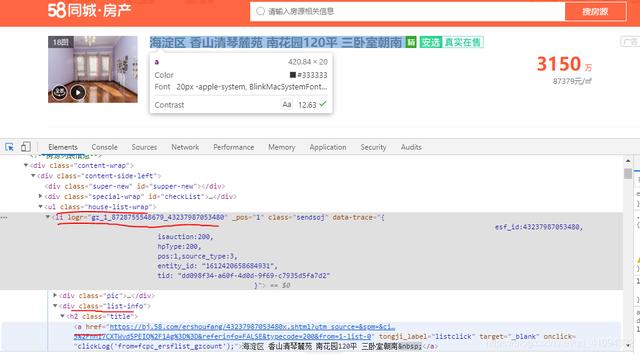
具体的内容存在于li标签下第二个div标签的a标签中。3、代码
from lxml import etree
import requests
if __name__ == "__main__":
url = ‘https://bj.58.com/ershoufang/‘
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36‘
}
# 爬取到页面源码数据
page_text = requests.get(url=url,headers=headers).text
# 数据解析
tree = etree.HTML(page_text)
# 存储li标签对象
li_list = tree.xpath(‘//ul[@class="house-list-wrap"]/li‘)
with open(‘./58.txt‘,‘w‘,encoding=‘utf-8‘) as fp:
for li in li_list:
title = li.xpath(‘./div[2]/h2/a/text()‘)
print(title)
fp.write(title+‘\n‘)
4、实现效果
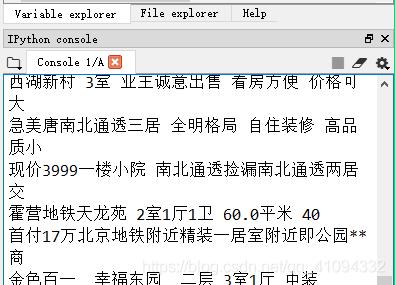
源码或者完整代码加群:1136192749
文章标题:Python爬虫——基于xpath爬取58同城房源信息!
文章链接:http://soscw.com/index.php/essay/69977.html