一篇文章教会你利用Python网络爬虫获取Mikan动漫资源
2021-03-31 09:28
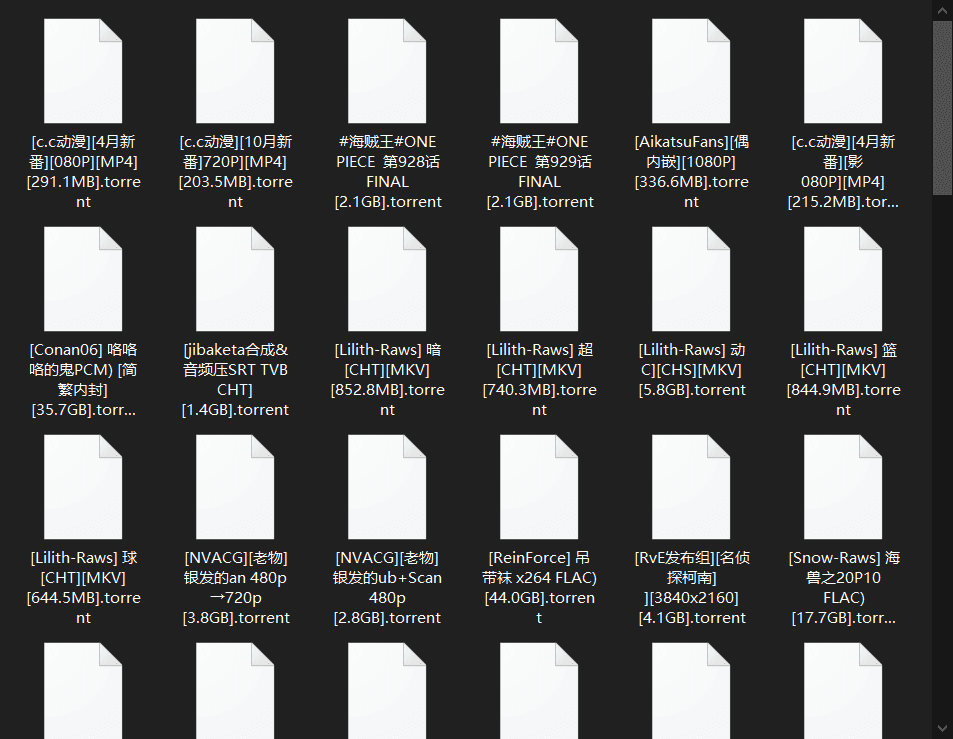
标签:print torrent user 访问 响应 解决 学习 网页 code [蜜柑计划 - Mikan Project] :新一代的动漫下载站。是一个专门为喜欢动漫的小伙伴们打造的动漫视频在线播放网站,为大家第一时间分享最新动漫资源,每日精选最优质的动漫推荐。 【二、项目目标】 ???实现获取动漫种子链接,并下载保存在文档。 【三、涉及的库和网站】 1、网址如下: 2、涉及的库:reques**ts、lxml、fake_useragent** 3、软件:PyCharm 【四、项目分析】 ???首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示: ???点击下一页时,每增加一页Classic/()自增加1,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。 【五、反爬措施】 1、获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。 2、使用 fake_useragent ,产生随机的UserAgent进行访问。 【六、项目实施】 1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。导入需要的库和网址。 2、主方法(main):for循环实现多个网页请求。 3、?随机产生UserAgent。 4、发送请求 ?获取响应, 页面回调,方便下次请求。 5、xpath解析一级页面数据,for循环遍历补全网址,获取二级页面网址。 6、二级页面请求 ,先找到页面父节点,for循环遍历,再用path获取到种子的下载地址。补全种子链接地址。 7、保存在word文档 。 8、调用方法,实现功能。 【七、效果展示】 1、运行程序,在控制台输入起始页,终止页,如下图所示。 2、将下载成功的图片信息显示在控制台,如下图所示。 3、保存.torrent文档。 4、如何打开种子文件?先上传到百度云盘,如下图所示。 5、双击解析下载,如下图所示。 【八、总结】 1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。 2、本文章就python爬取Mikan Project,在下载种子的难点和重点,以及如何防止反爬,做出了相对于的解决方案。 3、介绍了如何去拼接字符串,以及列表如何进行类型的转换。 4、欢迎大家积极尝试,有时候看到别人实现起来很简单,但是到自己动手实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。 5、Mikan Project还提供了星期的专栏。每一天都可以看到好看的动漫。专门为喜欢动漫的小伙伴们打造的动漫视频。 6、需要本文源码的小伙伴,后台回复“动漫资源”四个字,即可获取。 看完本文有收获?请转发分享给更多的人 IT共享之家 入群请在微信后台回复【入群】 一篇文章教会你利用Python网络爬虫获取Mikan动漫资源 标签:print torrent user 访问 响应 解决 学习 网页 code 原文地址:https://blog.51cto.com/13389043/2523794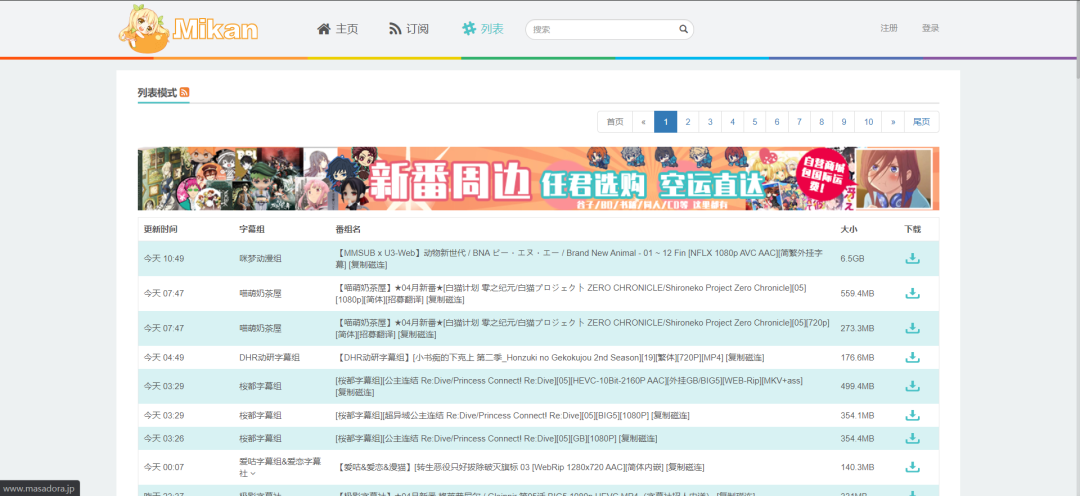
https://mikanani.me/Home/Classic/{}https://mikanani.me/Home/Classic/1
https://mikanani.me/Home/Classic/2
https://mikanani.me/Home/Classic/3import requests
from lxml import etree
from fake_useragent import UserAgent
class Mikan(object):
def __init__(self):
self.url = "https://mikanani.me/Home/Classic/{}"
def main(self):
pass
if __name__ == ‘__main__‘:
Siper = Mikan()
Siper.main()stat = int(input("start :"))
end = int(input(" end:"))
for page in range(stat, end + 1):
url = self.url.format(page)
print(url)for i in range(1, 50):
self.headers = {
‘User-Agent‘: ua.random,
}def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return htmlparse_html = etree.HTML(html)
one = parse_html.xpath(‘//tbody//tr//td[3]/a/@href‘)
for li in one:
yr = "https://mikanani.me" + litow = parse_html2.xpath(‘//body‘)
for i in tow:
four = i.xpath(‘.//p[@class="episode-title"]//text()‘)[0].strip()
fif = i.xpath(‘.//div[@class="leftbar-nav"]/a[1]/@href‘)[0].strip()
# print(four)
t = "https://mikanani.me" + fif
print(t) dirname = "./种子/" + four[:15] + four[-20:] + ‘.torrent‘
# print(dirname)
html3 = requests.get(url=t, headers=self.headers).content
with open(dirname, ‘wb‘) as f:
f.write(html3)
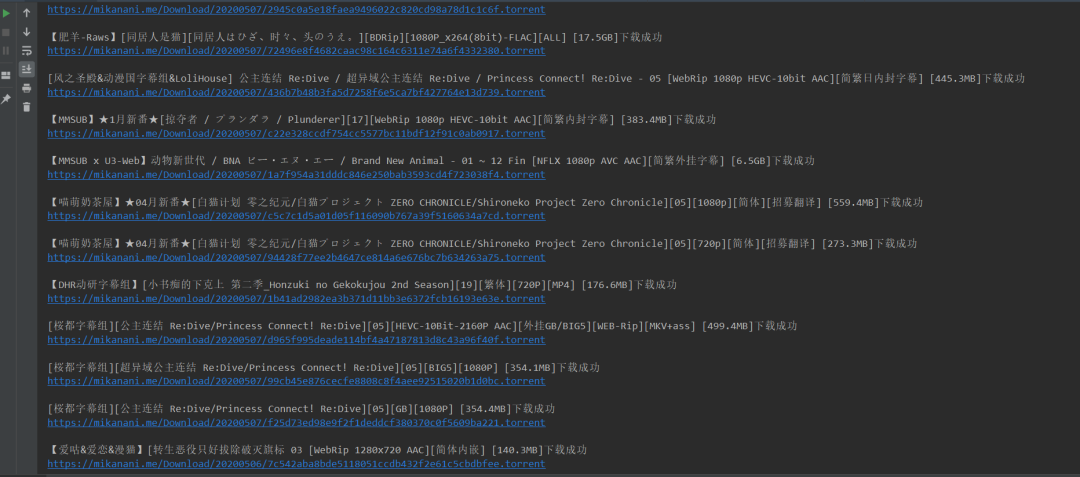
print("\n%s下载成功" % four) html = self.get_page(url)
self.parse_page(html)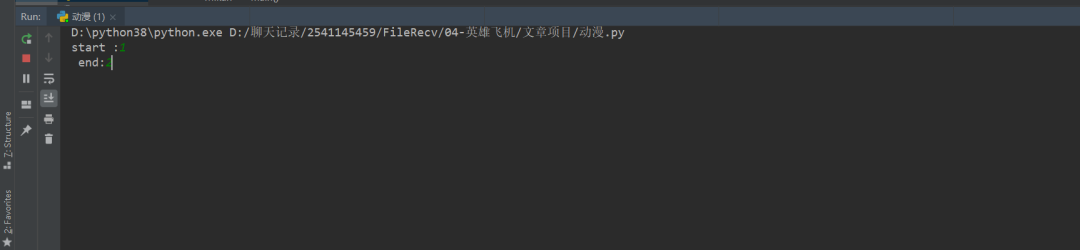

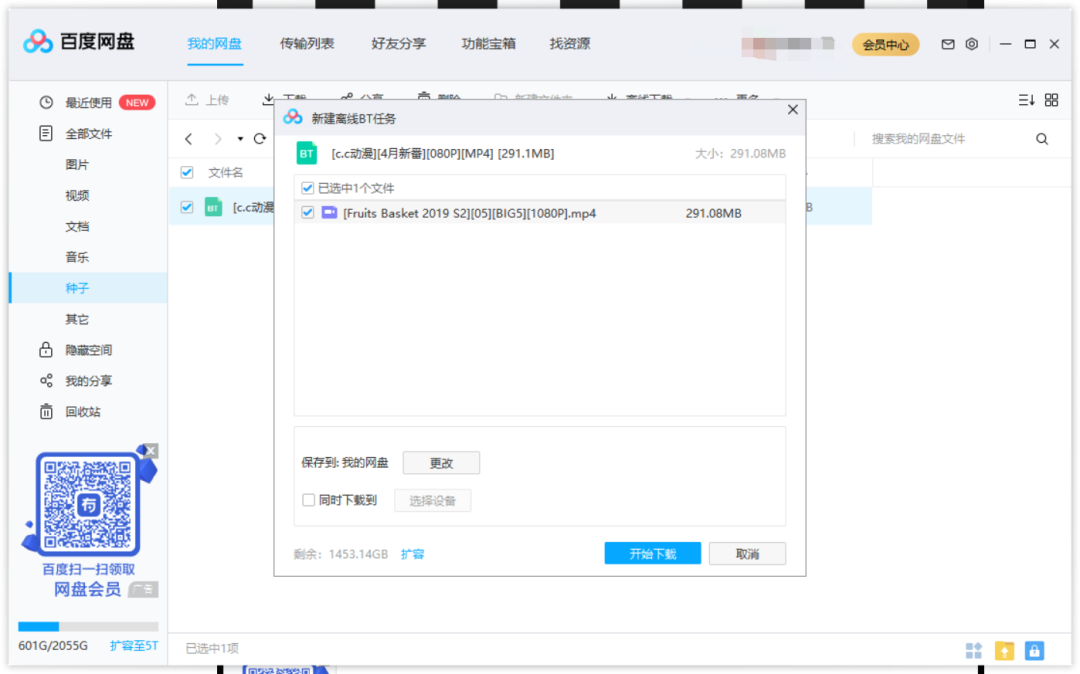

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
文章标题:一篇文章教会你利用Python网络爬虫获取Mikan动漫资源
文章链接:http://soscw.com/index.php/essay/70401.html