图像分割 - LaneNet + H-Net 车道线检测
2021-04-02 14:26
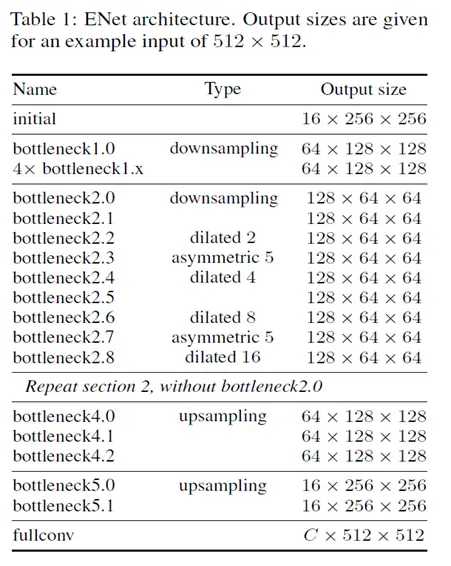
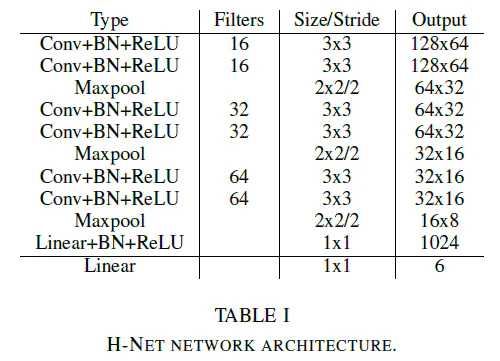
标签:hub 训练 语义 全连接 均值 pdf 参数 变换 bsp 本文是对论文的解读与思考 论文: Towards End-to-End Lane Detection: an Instance Segmentation Approach 该论文提出了一种 端到端 的 实例分割方法,用于车道线检测; 论文包含 LaneNet + H-Net 两个模型网络,其中 LaneNet 是一种将 语义分割 和 像素矢量化 结合起来的多任务模型,语义分割用来分割车道线与背景,像素矢量化 用于把属于同一条车道线的像素 聚类 在一起, H-Net 是个小网络,用于预测 转换矩阵 H,使用 H 对同一条车道线的所有像素点进行重新建模(论文中是使用 y 预测 x) 之前提到大部分 图像分割 的网络都包含 encode 和 decode 两部分,LaneNet 也不例外,不同的是 LaneNet 包含了两个分支,如下图 下面的分支 Segmentation branch 是常规的 语义分割,用于 分割 车道线 和 背景,实现的是 二分类; 上面的分支 Embedding branch 用于 像素的矢量化,把每个 像素 用一个高维向量表示(类似于 word embedding),使得 像素 可以通过 聚类 把 不同车道线分开; 后面那个 X 不必在意,只是结合的意思; LaneNet 是 基于 ENet 的 Encode-Decode 网络结构,ENet 网络如下图 如图所示,ENet 由 5 个 stage 组成, stage 1 2 3 属于 Encode,stage 4 5 属于 Decode; LaneNet 中 语义分割 和 Embedding 两个任务共用 stage 1 2,将 stage 3 和 后面 的 Decode 部分作为各自分支结构; 语义分割 的 输出为 W*H*2,[2 分类],Embedding 的输出为 W*H*Dim,Dim 为自定义的向量长度; 论文中两个分支 权重相同; 语义分割目的是区分 车道线和背景,其中作者主要考虑两点: 1. 在构建 label 时,为了处理遮挡问题,论文对 被车辆遮挡的车道线和虚线进行了还原; 2. 由于 类别 不均衡,作者进行了加权 Pclass 为 每个类别 出现的概率, C 为 常数,是个超参数,(ENet论文中是1.02,使得权重的取值区间为[1,50]) 个人理解:首先,由于 类别分布可能会相差很大, 取 log 缩放了这个差距,加个 常数 C 防止 log 取 负数,然后再取 倒 是把出现多的权重变小,出现少的权重变大; 像素 Embedding 是对 像素进行 矢量化,用于区分 每个像素 属于哪条车道线; 它的思想如下:类似于聚类,同一条车道线(根据 label 可知) 的像素要靠近 矢量化 的中心,不同车道线的像素的 矢量化 中心要远离,即 类内距离尽可能小,类间距离尽可能大; 它的 loss 设计很巧妙,分为两部分 C 代表 车道线的条数,由 label 可知; Nc 代表 每条车道线的 像素点; μc 代表每条车道线的像素矢量 均值,注意是 预测值的 mean,即 网络输出 预测矢量 后,再计算均值,然后 计算 loss; δv 代表 像素 离 μc 的距离,小于 该距离时,要进行 pull,即 拉近到 聚类中心; // 试想一下普通的距离方法,每个样本分布在其聚类中心周围,并不是 和 聚类中心 重合, μca μcb 代表 不同车道线的 像素矢量 均值,也是 预测值的 mean; δd 代表不同车道线 聚类中心 间 的距离; ||x|| 代表 L2 范数; [x]+ 代表 max(0, x); 聚类只 发生在 预测部分; 即 模型完成 分割 和 矢量化 后,对矢量 进行 聚类,区分不同车道线; 为了 方便 聚类,在 Embedding 时 设定 δd > 6*δv; 聚类 方法使用的是 mean shift,不再赘述; LaneNet 的输出是 每条车道线的像素集合,我们还需要把 这些 像素 拟合成一条车道线; 传统做法是将 图片 投影到 鸟瞰图 中,然后用 二阶或者三阶 多项式进行拟合,这种方案 转换矩阵 H 只算一次,但不同地形如 丘陵、山地 的转换是略有不同的; 为了解决这个问题,论文训练了一个 预测 转换矩阵 H 的 神经网络,输入是一张图片,输出是 转换矩阵 H; H 长这样 通过置 0 对转换矩阵进行约束,即水平线在转换下保持水平,即 坐标 y 的变换不受 x 的影响; y‘ = dy + e,与 x 无关; 上述转换矩阵只有 6 个参数,故 H-Net 模型的输出是一个 6 维向量,网络包含 6 个卷积层和 1 一个 全连接; 懒得写了,是个图片 思路如下: H-Net 输出 H 后,与 真实像素 相乘 做转换,得到一堆转换后的点,然后用 最小二乘法 得到 拟合系数 w,注意 至此 H w 都是瞎猜的,是预测的, 然后我们在 y’ 处 计算对应的 x’ ,最后用 H-1 把 x’ 还原回去,得到 x*,然后求 误差; 其实论文并没有讲清楚 到底怎么弄的,困扰了我很久,我的理解是这样的 曲线拟合只发生在 预测 部分; laneNet 为什么没有 类似于 skip connection 的操作? 我的理解是 识别车道线的任务 太过简单了 参考资料: https://www.jianshu.com/p/c6d38d648509 https://www.cnblogs.com/xuanyuyt/p/11523192.html https://github.com/stesha2016/lanenet-enet-hnet 图像分割 - LaneNet + H-Net 车道线检测 标签:hub 训练 语义 全连接 均值 pdf 参数 变换 bsp 原文地址:https://www.cnblogs.com/yanshw/p/12530272.htmlintroduction
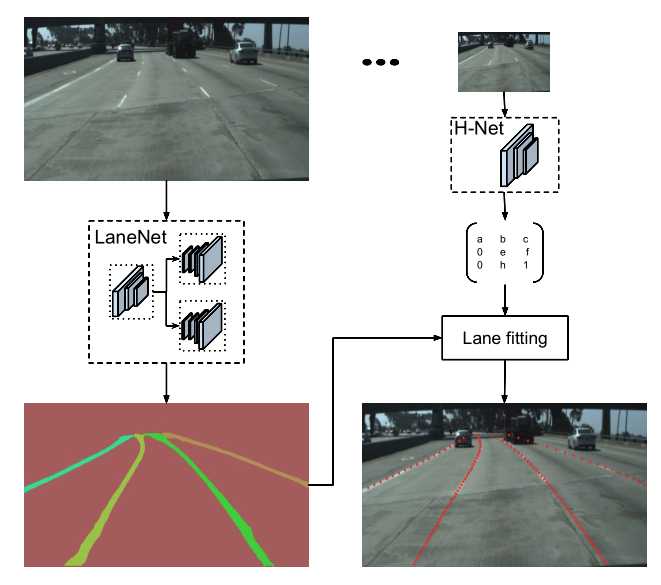
LaneNet
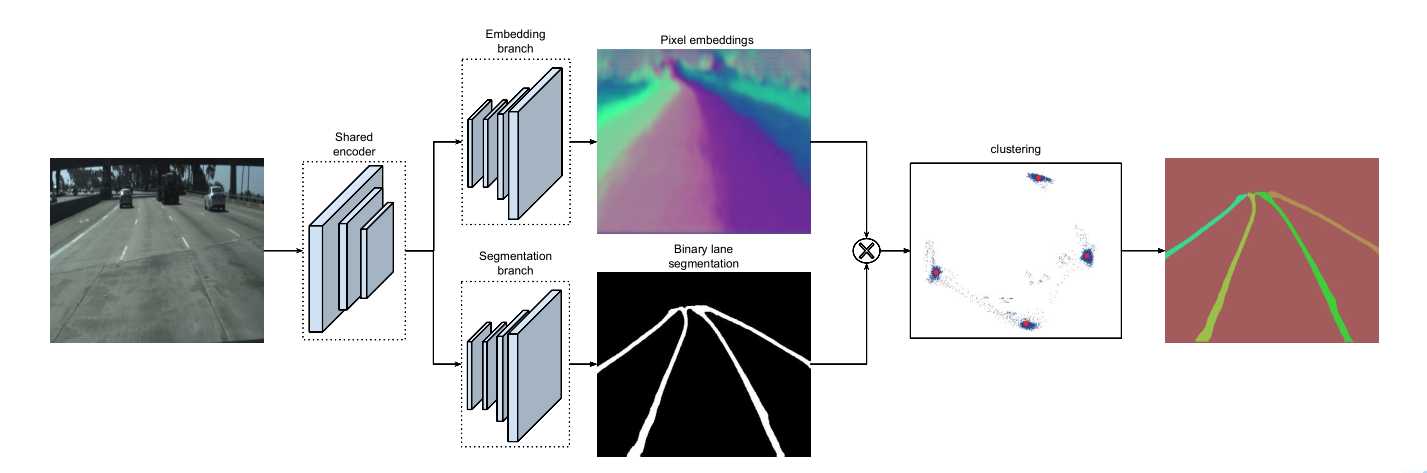
网络结构
Segmentation
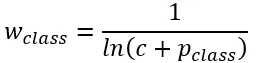
Embedding
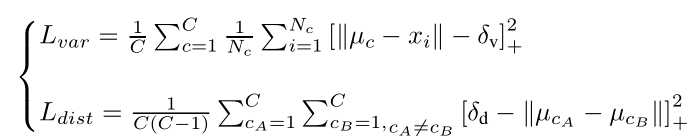
聚类
H-Net
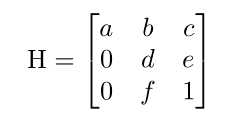

网络结构
loss function

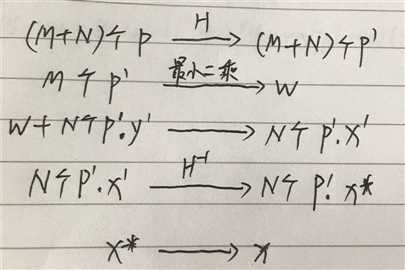
curve fitting
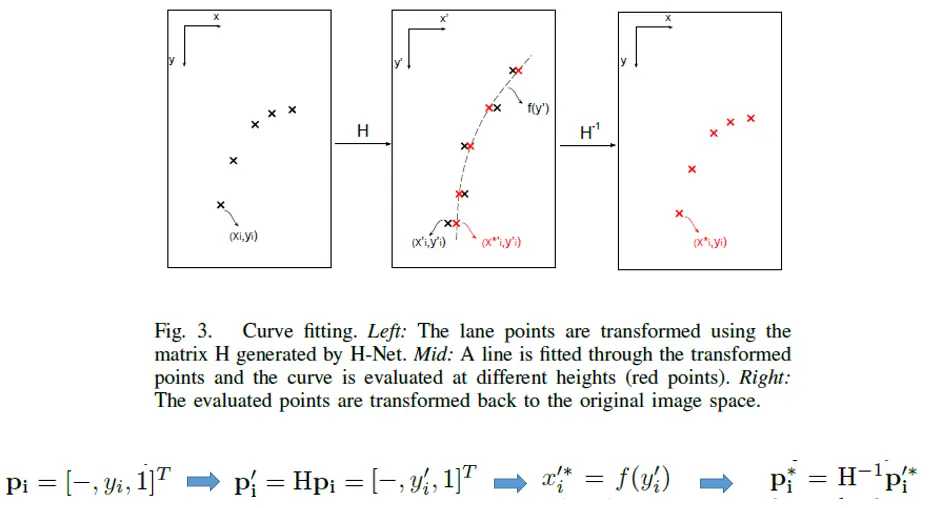
思考
文章标题:图像分割 - LaneNet + H-Net 车道线检测
文章链接:http://soscw.com/index.php/essay/71411.html