retinanet
2021-04-06 14:27
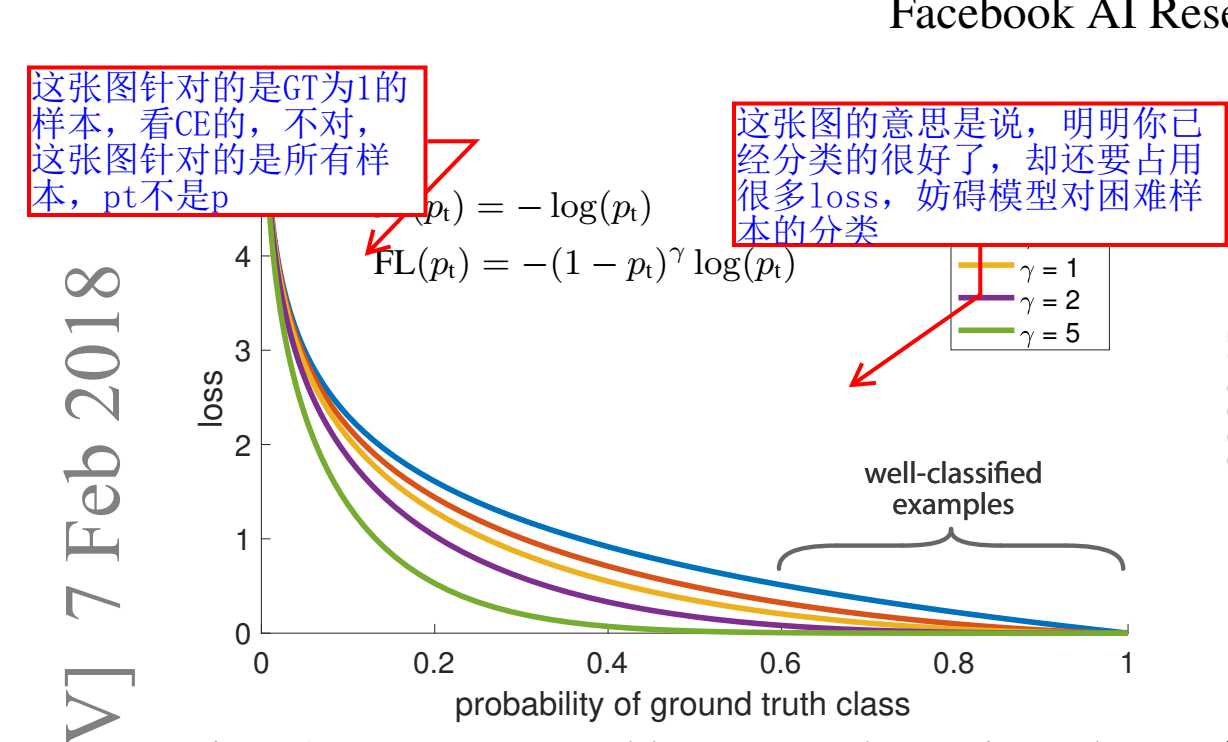
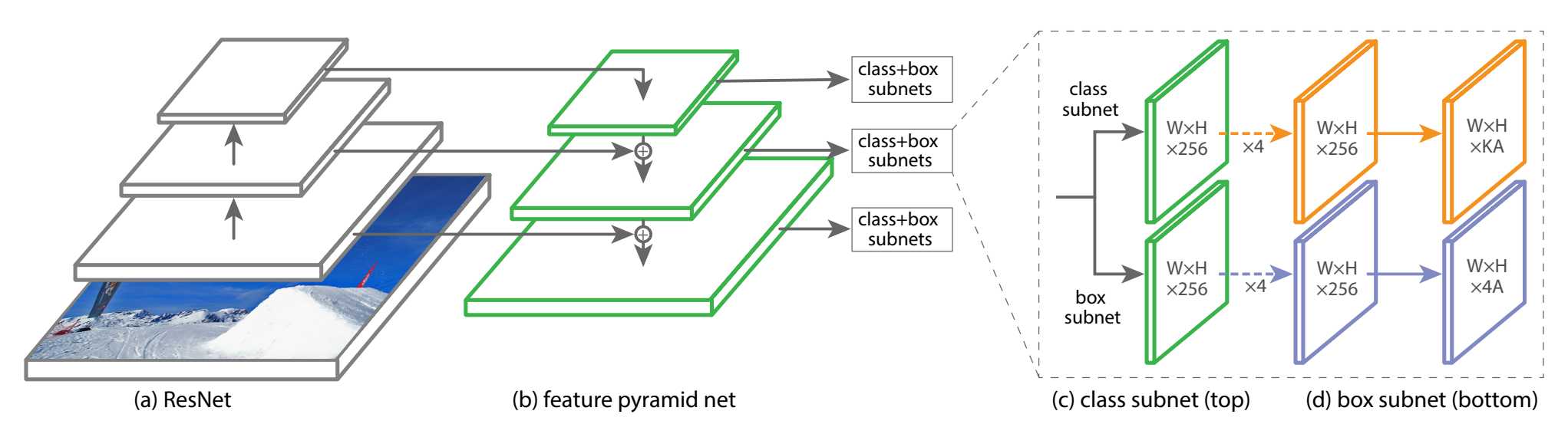
标签:参与 网络优化 覆盖 mic 参数 输出 问题 sub 回归 作为单阶段网络,retinanet兼具速度和精度(精度是没问题,速度我持疑问),是非常耐用的一个检测器,现在很多单阶段检测器也是以retinanet为baseline,进行各种改进,足见retinanet的重要,我想从以下几个方面出发将retinanet解读下,尽己所能。 【出发点】 retinanet的出发点,作为一款单阶段检测器,开个玩笑,它其实是想为yolo,ssd等前辈找回牌面,毕竟在速度上是达到实时了,但是精度上依然被faster rcnn等两阶段检测器吊打,着实没面子,那既然痛点在精度上,本文的重点也在于此,作者认为单阶段的精度差在于单阶段检测器中样本的失衡,负样本比例远远大于正样本,占据样本中多数,影响网络的优化(如何解释会妨碍网络优化,我还解释不清),而两阶段就没有这样的问题么,我觉得不是没有,但问题小很多,因为第一阶段会剔除掉大量负样本,所以在第二阶段训练时候,正负样本比例失衡并不严重,尽管第一阶段也会面临这样的问题。也许可以将focal loss(retinanet采用的采样方案或者说损失形式)用于RPN,按道理来讲会提升的 既然负样本太多,那我们也不是没办法,之前已有相关的处理方法,比如OHEM,专门挑比较难分类的负样本进行分类,其余的负样本不参与训练,效果也是不错的,大方向思路也没问题,就是降低易分类样本的影响,OHEM的思路是让它们的影响为0,直接弃用,而本文的思路是降低它们的权重,提高难分类样本的权重,如果再加上另一种方案,即所有样本原封不动,参与训练,那么这三种方案,OHEM属于激进派,retinanet属于温和派,原封不动属于保守派,最后的实验结果表明 温和派>激进派>保守派 【解决方案】 retinanet的解决方案十分的简洁,简洁到令人发指,就是在原本的分类损失上进行改动,加上权重因子,减小易分类样本的权重,加大难分类样本的权重(相对而言,不是绝对的变大了),至于回归损失,保持不变 首先看原来的分类损失,以二分类为例(多分类基本是一样的) 这就是标准的交叉熵损失,稍微变换一下 有下面公式 对于这个公式,Pt越大,代表越容易分类,也就是越接近target, 于是我们应该在Pt变大时,权重变小, 变小时,权重变大, 怎么做,加一个权重因子即可,我先来一个乞丐版的,在原公式前面乘以1-Pt。就成了 当然了,论文中稍微高大上一些, γ(gamma,不是Y),是一个指数因子,论文里设为2 上面的公式就是focal loss,但还不是最终版,在类别不平衡中有一种做法,是给损失加上常数项正负样本平衡因子,α,这个平衡因子是用来对正负样本的损失进行平衡,并不能区分易分类样本和难分类样本哦,最终版focal loss也加入了这一项,于是变成(下标t与P的下标一个意思,针对两种类别),相比公式4,效果轻微提升 论文中给出了,Focal loss和CE的对比图,CE的loss在最上面,可以看到,越易分类的样本,Focal loss损失越小 上面就是核心,下面我来讲一下实现细节,网络结构,anchor的设置,FPN的设置,等等 网络结构 作者采用的网络与faster rcnn或者FPN一样,也是resnet50,101,然后加上FPN的结构,如下图所示 对于金字塔的每一层,都有两个分支,分类和回归,A是每个预测位置的anchor数量,以该位置为中心,K是要预测的目标类别数,4是与类别无关的坐标回归,也可以设置成与类别相关的,那就是4K个通道输出了,论文中作者说这两种设置效果相同,但类别无关的显然参数更少。 另外需要注意的一点是不同金字塔级别的分类分支参数共享,就是使用同一个卷积组合,回归分支,作者没说是否参数共享 inference:前向推理阶段,即测试阶段,作者对金字塔每层特征图都使用0.05的置信度阈值进行筛选,然后取置信度前1000的候选框(不足1000更好) ,接下来收集所有层的候选框,进行NMS,阈值0.5 train:训练时,与GT的IOU大于0.5为正样本,小于0.4为负样本,否则忽略 anchor:anchor的设置与FPN论文略有不同,FPN中每一层一种尺度,三种比例,而retinanet中,每一层三种尺度,三种比例,在FPN中,5层金字塔,anchor尺度范围是322到5122,而本文为每一层的尺度设置三种,20, 21/3, 22/3.比例依旧是1:1, 1:2,2:1,于是有9种anchor。 以输入为800X800,五层金字塔尺度分别为100X100,50X50,25X25,12X12,6X6,算一下anchor数量,119745, 10几万anchor覆盖在整张图像中,密密麻麻,让你知道什么是密集检测,哈哈,插句话,10几万anchor中绝大多数都是负样本,无用的计算太多,这也是现在anchor free的一个出发点。 网络初始化:这一点本来没什么可说的,大家都一样,但是retinanet做了一点设置 【效果】 论文中给了好多对比试验,也给出了好多map值,简单贴一下,都是coco test-dev数据集的 37.8 resnet101-FPN 800 39.1 resnet101-FPN 800,scale jitter, longer train time 40.8 resNext101-FPN 800 retinanet 标签:参与 网络优化 覆盖 mic 参数 输出 问题 sub 回归 原文地址:https://www.cnblogs.com/ziwh666/p/12494348.html
![]()
![]()
![]()
![]()
![]()