Sequence to Sequence Learning with Neural Networks论文阅读
2021-04-07 14:26
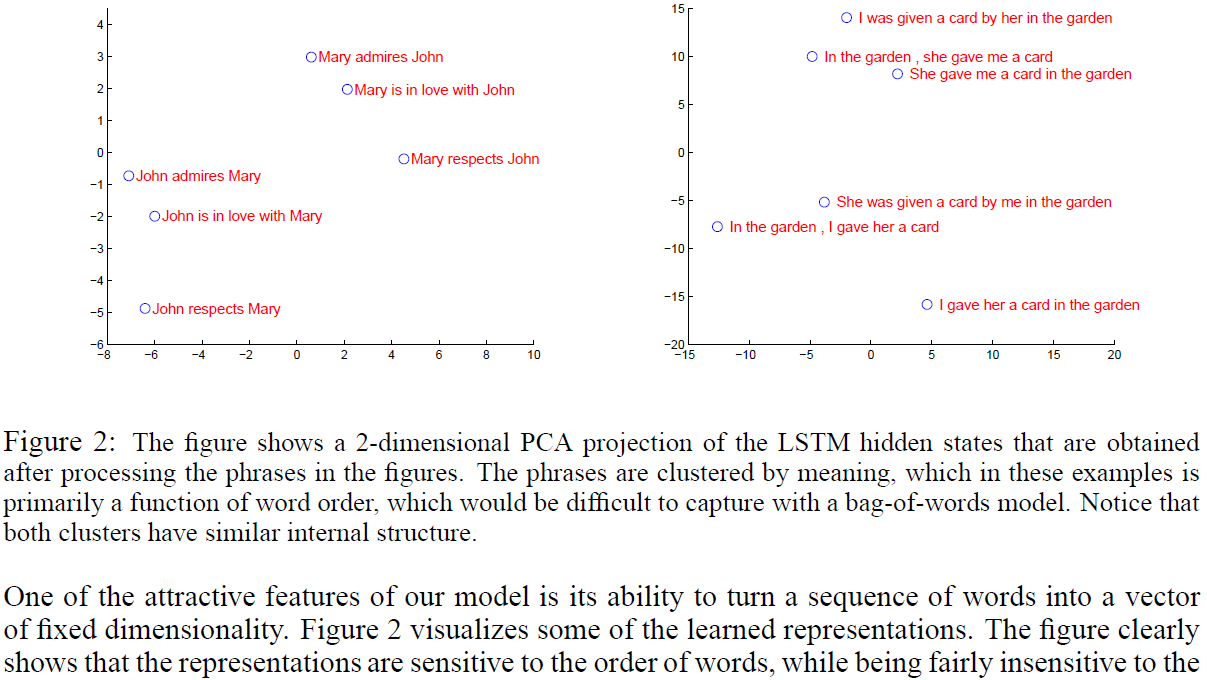
标签:spl 核心 通过 sorted 维度 很多 mat abc rank 论文下载 作者(三位Google大佬)一开始提出DNN的缺点,DNN不能用于将序列映射到序列。此论文以机器翻译为例,核心模型是长短期记忆神经网络(LSTM),首先通过一个多层的LSTM将输入的语言序列(下文简称源序列)转化为特定维度的向量,然后另一个深层LSTM将此向量解码成相应的另一语言序列(下文简称目标序列)。我个人理解是,假设要将中文翻译成法语,那么首先将中文作为输入,编码成英语,然后再将英语解码成法语。这种模型与基于短语的统计机器翻译(Static Machine Translation, SMT)相比,在BLUE(Bilingual Evaluation Understudy)算法的评估下有着更好的性能表现。同时,作者发现,逆转输入序列能显著提升LSTM的性能表现,因为这样做能在源序列和目标序列之间引入许多短期依赖,使得优化更加容易 深度神经网络(Deep Nerual Networks)是一种性能强大的模型,在处理各种难题,如语音识别、图像识别上有着近乎完美的表现。这种模型之所以这么强大,是因为它能在有限的步骤内实现任意并行计算。只要有足够的训练数据集,它就能训练出神经网络的参数,从而DNN能产生很好的效果 虽然DNN有着很强的能力,但只能将源序列和目标序列都编译为固定维度的向量。这是一个致命的问题,因为很多问题都无法提前预知被表示序列的长度,例如语音识别与机器翻译 解决问题的思路就是先用一层LSTM读入源序列,逐步获得大量维度固定的表示向量,然后用另一层LSTM从向量中提取出目标序列。第二层LSTM本质上是一个语言模型。由于输入和输出之间存在相当大的时间延迟,所以使用LSTM对具有长期时间依赖性的数据进行训练是相当好的选择 第二段作者介绍了其他人的一些工作,这里就不多叙述了 从图中我们可以简要了解LSTM模型的解决思路,先读入源序列"ABC",遇到结束符" 上面的内容主要意思就是作者和其它各种模型进行了比较,比别人的效果都要好,有一些效果很接近 令人惊讶的是,LSTM训练很长的句子也没什么问题,因为作者颠倒了训练集和测试集中源序列的单词顺序 LSTM另一个重要特质是它能够学会将不同长度的句子映射在一个维度固定的向量。常规的翻译倾向于逐字逐句翻译,但LSTM倾向于理解句子的含义,因为同样的句子在不同的语境中的含义有所不同。一项定性评估支持了作者的理论,表明其模型知道单词顺序,并且相对于主动和被动语态均保持不变 循环神经网络是一前馈神经网络对于序列的一种自然泛化。即给定一个输入序列\(x_1,...,x_T\),RNN可以用通过以下公式迭代得到输出序列\(y_1,...,y_T\) 通用的序列学习方法最简单的策略是使用一个RNN将源序列映射到固定大小的向量,然后是用另一个RNN将该向量映射为目标序列。虽然它原则上是可行的,但由于向RNN提供了所有相关信息,产生了长期依赖性,因此RNN变得很难训练。不过,总所周知,LSTM可以学习具有长期时间依赖性的问题,因此LSTM在这种情况下可能会成功 LSTM的目标是估计出条件概率\(P(y_1,...,y_{T'}|x_1,...,x_T)\),其中\((x_1,...,x_T)\)是输入序列,\((y_1,...,y_T)\)是相应的输出序列,并且长度\(T\)和\(T'\)允许不相同。LSTM首先获得最后一个隐藏状态给出的固定维度向量\(v\)。然v用一个标准的LSTM-LM公式计算\(y_1,...,y_T\)的概率。此方程的最终隐藏状态是\((x_1,...,x_T)\)表示的\(v\) 但作者的实际模型与以上描述有三个方面不同 作者使用两种方式将它们的方法应用于WMT‘14英语→法语的机器翻译任务中,我们使用它来直接翻译句子,而不是使用SMT(SMT, Statistical Machine Translation) 我们将模型训练在一个由3.48亿个法语单词和3.04亿个英语单词组成的1200万个句子的子集上,这是一个干净的精心挑选的子集。之所以选择此次翻译的任务和训练集,是因为它们作为标记化训练的广范实用性,并且这些数据都是来自STM baseline中的1000个最佳列表 由于典型的神经网络模型需要将每个单词转换为向量表示,所以我们对两种语言都使用了固定的词汇。我们对源语言使用了160000个最频繁出现的单词,对目标语言使用了80000个最频繁出现的单词。每个不在这个词汇表中的单词都被特殊标记为"UNK" 我们实验的核心是在许多句子对上训练一个大而深的LSTM。通过最大化一个对数概率来训练这个网络,其中的概率是在给定源句子S上的正确翻译T 虽然LSTM能够解决具有长期依赖关系的问题,但是我们发现,当源语句被反转(目标语句没有反转)时,LSTM的表现更好 虽然我们对这一现象没有一个完整的解释,但我们认为这是由于对数据集引入了许多短期依赖关系造成的。通常,当我们把源序列与目标序列链接时,原序列中的每个词语在目标序列中的对应单词相差很远。因此,该问题具有"最小时间延迟"的问题。通过颠倒源序列中的单词,源序列中对应单词与目标序列中词语的平均距离不变,但源序列中的最初几个词已经非常接近目标序列中的词了,所以"最小时间延迟"问题就能减小许多。因此,反向传播能够更轻松地在源序列和目标序列中建立联系,并且改善整体的性能表现 这里的"最小时间延迟",我个人深有体会,不是在NLP领域,而是我自己用LSTM做时间序列预测的时候发现的一个问题,预测值总是比真实值看上去要延迟1到3个单位,整体轮廓是如此的相似,可惜就是横坐标对不上 作者起初认为逆转源序列只会对句子的前半部分取得良好的表现,对后半部分的优化会较差。然而实际表现都很好。为什么有这样的奇效呢?其实可以这么理解,当我们将输入句子倒序后,输入句子与输出句子之间的平均距离其实并没有改变,而在倒序前,输入与输出之间的最小距离是很大的,并且每个词与其对应的翻译词的间隔是相同的,而倒序后,前面的词(与其翻译词)之间的间隔变小,后面的词(与其翻译词)间隔变大,但前面间隔小的词所带来的性能提升非常大,以至于能够使得后面的翻译效果不降反增 作者使用了4层的深度LSTMs,每层有1000个单元,1000维的单词嵌入,输入词汇为160000,输出词汇为80000。我们发现深层LSTMs明显优于浅层LSTMs,浅层LSTMs每增加一层,perplexity就减少10%,这可能是因为它们的隐藏状态更大。完整的训练详情如下: 下表是与其他模型在机器翻译上的效果对比,上面两行是其他模型的效果,下面六行是作者模型在不同参数设置时的效果 此外,作者还尝试将自己的模型与传统的STM系统进行结合,效果显著,BLEU最好的达到了37.0,超过Baseline System将近4个点 在长句子上的表现也很好 我们模型其中一个吸引力十足的特点就是有能力将一个序列映射为固定维度的向量,上图就是学习过程的可视化表示。每个短语根据其含义而聚类分布,从中我们可以看出其对单词的顺序非常敏感,而对被动语态替换主动语态则相当不敏感 左图展示了LSTM的表现与句子长度的函数关系,其中x轴代表相应句子整理后的长度(Test Sentences Sorted By their Length)。对于少数35字的句子,效果没有下降,只有在最长的句子中有略微的缩减。右图展示了LSTM的表现与句子中词语的稀有度之间的关系,其中x轴代表整理后句子的平均词语频率(Test Sentences Sorted By Average word Frequency Rank) 这一部分主要是作者讲述了目前其他人的一些工作以及成果,有兴趣自己阅读即可 在本论文中,我们发现一个基于有限词汇,具有深层结构的LSTM的性能表现能够胜过一个基于统计机器翻译的系统,基于LSTM的机器翻译的成功说明了它只要在拥有足够的训练数据的前提下,同样能在解决其他问题上发挥出色 我们对逆转源序列后的性能提升程度感到惊讶。同时我们也推断出,找到一个问题具有最大数量的短期相关性是非常重要的,因这样可以简化问题的解决。我们相信一个标准的RNN在逆转源序列后能够更加容易被训练 这篇文章在当年看来可能非常惊艳,但是我读完这盘文章之后很无感,"不就是两个LSTM拼接吗?"。甚至我觉得作者这篇文章的重点在于逆转源序列进行训练,因为作者在许多地方都提到了,实在是让人印象深刻 Sequence to Sequence Learning with Neural Networks论文阅读 标签:spl 核心 通过 sorted 维度 很多 mat abc rank 原文地址:https://www.cnblogs.com/mathor/p/12485707.html
1 Introduction




2 The model

\[
\begin{align*}
h_t&=\sigma(W^{hx}x_t+W^{hh}h_{t-1})\y_t&=W^{yh}h_t
\end{align*}
\]
只要提前知道输入和输出序列长度相同,RNN就可以轻松地将序列映射到序列。但是,还不清楚如何应用到输入和输出序列长度不同且具有复杂和非单调关系的问题
\[
P(y_1,...,y_T|x_1,...,x_T)=\prod_{t=1}^{T'}P(y_t|v,y_1,...,y_{t-1})
\]
在这个等式中,每个\(P(y_t|v,y_1,...,y_{t-1})\)分布用词汇表中所有单词的softmax表示。同时需要在每个句子的结尾用"
3 Experiments

3.1 Dataset details

3.2 Decoding and Rescoring

\[
\frac{1}{|S|}\sum_{(T,S)\in S}log\ p(T|S)
\]
此处S是训练集,训练完成后,根据LSTM找出最可能的翻译作为结果
\[
\hat{T}=\mathop{argmax}\limits_{T}\ p(T|S)
\]3.3 Reversing the Source Sentences

3.4 Training details

3.5 Parallelization

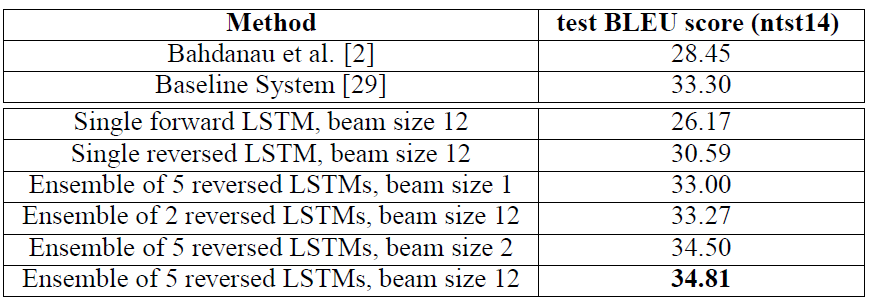
3.6 Experimental Results

3.7 Performance on long sentences
3.8 Model Analysis
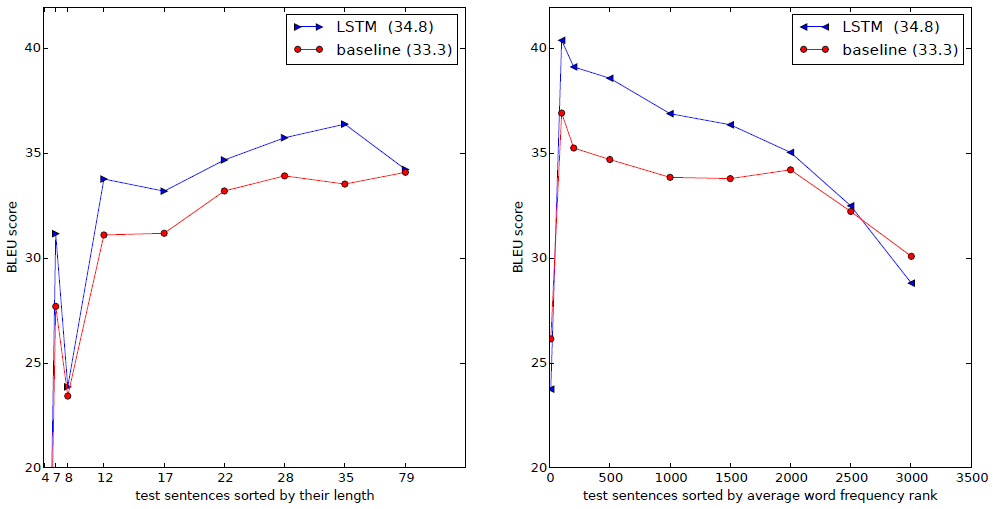
4 Related work

5 Conclusion

个人总结
上一篇:js 单例模式
文章标题:Sequence to Sequence Learning with Neural Networks论文阅读
文章链接:http://soscw.com/index.php/essay/72425.html