用puppeteer爬取网页数据初体验
2021-04-10 03:31
标签:utf8 rip com 队列 sync ror 后端 渲染 名称 业务需求,页面需要显示很多链接列表,像这样的。 我问项目经理要字典表,他笑咪咪地拍着我的肩膀说:“这边有点忙,要不按照这个自己抄一下吧”。 emmm… 我看了一下,数据大概有七八百条,一个一个录入,那不得搞到地老天荒、海枯石烂。 心口一股燥热,差点就要口吐莲花,舌吐芬芳了… 转念一想,做人要儒雅随和,念在平时没少蹭吃蹭喝的份上,咱先弄一下吧。 可是怎么弄呢? 一个一个输入是不可能的,我们需要录入每个组的标题、标题下的名称和链接,这是需要看网页源码,效率太低。 拦截接口也不行,网页是 PHP 写的,后端渲染,前端看不到接口。 那就只有一种方法,爬取网页数据。想到之前了解过的 说干就干。 安装依赖,puppeteer 下载完成后会自动下载 me 大功告成. https://github.com/superman12312/learning/tree/master/NODEJS/puppeteer-demo 用puppeteer爬取网页数据初体验 标签:utf8 rip com 队列 sync ror 后端 渲染 名称 原文地址:https://www.cnblogs.com/lijianming180/p/12433378.html用
puppeteer爬取网页数据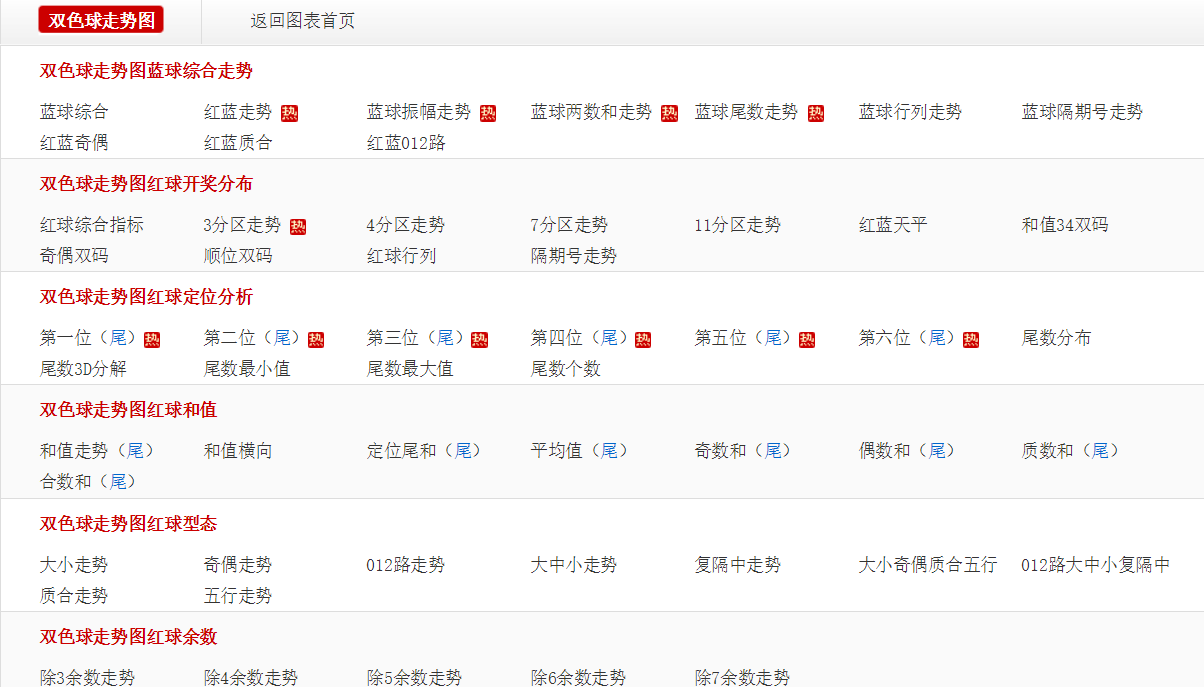
pupeteernodejs 库可以爬取网页数据,要不咱先试一下?准备工作
1
npm install puppeteer
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61const puppeteer = require("puppeteer");
const fs = require("fs");
const path = require("path");
const urlList = [
{ name: "双色球", url: "http://cjzst.36886.net/cjwssq/" },
{ name: "七乐彩", url: "http://cjzst.36886.net/cjwqlc/" },
{ name: "福彩3D", url: "http://cjzst.36886.net/cjw3d/" },
{ name: "大乐透", url: "http://cjzst.36886.net/cjwdlt/" },
{ name: "七星彩", url: "http://cjzst.36886.net/cjw7xc/" },
{ name: "排列三", url: "http 大专栏 用puppeteer爬取网页数据初体验://cjzst.36886.net/cjwpl3/" }
];
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
//封装单个网页爬取链接函数
async function (url, fileName) {
// 打开链接
await page.goto(url);
let result = await page.evaluate(() => {
const items = [...document.querySelectorAll(".zst_list_con>ul")];
return items.map(item => {
// 分组标题
let titleLink = item.querySelector(".zst_list_name>a");
//分组下链接li
let contentLink = [...item.querySelectorAll("li")];
let list = contentLink.map(item => {
// li下a链接
let a_list = [...item.querySelectorAll("a")];
return a_list.map(a => {
return { title: a.innerText, href: a.href };
});
});
// 返回所有查询结果
return { title: titleLink.innerText, href: titleLink.href, list: list };
});
});
// 将爬取的数据保存到本地
fs.writeFile(`./${fileName}.json`, JSON.stringify(result), "utf8", function(
error
) {
if (error) {
console.log(error);
return false;
}
console.log(fileName + "数据写入成功!");
});
// await page.close();
}
// 打开多个网页异步队列
async function openUrlList() {
for (let i = 0; i
await getLinkList(urlList[i].url, urlList[i].name);
}
}
// 执行异步队列
await openUrlList();
//关闭浏览器
await browser.close();
});爬取结果
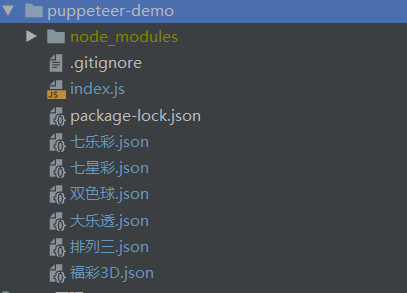
源码地址
文章标题:用puppeteer爬取网页数据初体验
文章链接:http://soscw.com/index.php/essay/73606.html