Java8 Stream流
2021-04-10 05:26
标签:its walk basic 服务器配置 并发处理 character http char 最大值 在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据 ,又或者通过 重新定义 Collections.sorts 的 Comparator 方法 来实现,这两种方式对于大数据量系统来说,效率并不是很理想。 Java8 中添加了一个新的接口类 Stream,他和我们之前接触的字节流概念不太一样,Java8 集合中的 Stream 相当于高级版的 Iterator,他通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。 在 Java 中我们称 Stream 为 流 ,我们经常会用流去对集合进行一些流水线的操作。Stream 就像工厂一样,只需要把集合、命令还有一些参数灌输到流水线中去,就可以加工成得出想要的结果。这样的流水线能大大简洁代码,减少操作。 Stream 流的操作流程一般都是这样的,先将集合转为流,然后经过各种操作,比如过滤、筛选、分组、计算。最后的终端操作,就是转化成我们想要的数据,这个数据的形式一般还是集合,有时也会按照需求输出 count 计数。 1) 使用传统的迭代方式来实现 2)Java8 中的 Stream API 进行实现 - 输出结果: Student{name=‘张倩倩‘, sex=‘女‘, hight=162} Student{name=‘刘翏柳‘, sex=‘女‘, hight=168} Student{name=‘李三炮‘, sex=‘男‘, hight=178} 想使用 Stream 流,首先咱得先创建一个 Stream 流对象。创建 Steam 需要数据源.这些数据源可以是集合、可以是数组、可以使文件、甚至是你可以去自定义等等。 集合 Collection 作为 Stream 的数据源,应该也是我们用的最多的一种数据源了。Collection 里面也提供了一些方法帮助我们把集合 Collection 转换成 Stream 。 调用 Collection.stream() 函数创建一个 Stream 对象。相当于把集合 Collection 里面的数据都导入到了 Stream 里面去了。 调用 Collection.parallelStream() 创建 Stream 对象。 parallelStream() 使用多线程并发处理最后子啊汇总结果,而 stream() 是单线程。所以相对来说 parallelStream() 效率要稍微高点。 数组也可以作为 Stream 的数据源。我们可以通过 Arrays.stream() 方法把一个数组转化成流对象。Arrays.stream() 方法很丰富,有很多个。大家可以根据实际情况使用。 我们也可以把 BufferedReader 里面 lines 方法把 BufferedReader 里面每一行的数据作为数据源生成一个 Stream 对象。 Files 里面多个生成 Stream 对象的方法,都是对 Path(文件) 的操作。 有的是指定 Path 目录下所有的子文件(所有的子文件相当于是一个列表了)作为 Stream 数据源,有的把指定 Path 文件里面的每一行数据作为 Stream 的数据源。 列出指定 Path 下面的所有文件。把这些文件作为 Stream 数据源。 Files.walk() 方法用于遍历子文件(包括文件夹)。参数 maxDepth 用于指定遍历的深度。把子文件(子文件夹)作为 Stream 数据源。 Files.find 方法用于遍历查找(过滤)子文件。参数里面会指定查询(过滤)条件。把过滤出来的子文件作为 Stream 的数据源。 Files.lines 方法是把指定 Path 文件里面的每一行内容作为 Stream 的数据源。 我们也可以自己去创建 Stream 自己提供数据源。Stream 类里面提供 of()、iterate()、generate()、builder() 等一些方法来创建 Stream,Stream 的数据源我们自己提供。 Stream.of() 函数参数就是数据源。 Stream.iterate() 可以用来生成无限流,函数需要两个参数:第一个参数是初始值、第二个参数用于确定怎么根据前一个元素的值生成下一个元素。 Stream.generate() 也是用于生成一个无限流。参数用于获取每个元素。 Stream.build() 通过建造者模式生成一个 Stream 建造器。然后把需要加入 Stream 里面的数据源一个一个通过建造器添加进去。 Stream 其他创建方式我们就不一一举例了。有如下方式。 Stream 流操作就是对 Stream 流的各种处理。Stream 里面已经给提供了很多中间操作(我们一般称之为操作符)。 Stream 提供的流操作符。 Stream 提供了这么多的操作符,而且这些操作符是可以组合起来使用。 Stream 流终端操作是流式处理的最后一步,之前已经对 Stream 做了一系列的处理之后。该拿出结果了。我们可以在终端操作中实现对流的遍历、查找、归约、收集等等一系列的操作。 Stream 流终端操作提供的函数有。 关于 Stream 终端操作部分,我们就着重讲下 collect() 函数的使用。因为其他的终端操作符都很好理解。collect() 稍稍复杂一点。 collect() 的使用主要在于对参数的理解,所有我们这里要专门讲下 collect() 函数的参数 Collector 这个类,以及怎么去构建 Collector 对象。只有在了解了这些之后,咱们才可以熟练的把他们用在各种场景中。 Collector 类目前没别的用处,就是专门用来作为 Stream 的 collect() 方法的参数的。把 Stream 里面的数据转换成我们最终想要的结果上。 Collector 各个方法,以及每个泛型的介绍: 有了上面的介绍,接下来我们自己来 new 一个 Collector 对象,把我们 Steam 流里面的数据转换成 List 。(当然了Collectors类里面有提供这个方法,这里我们自己写一个也是为了方便大家的理解) 我们将对常规的迭代、Stream 串行迭代以及 Stream 并行迭代进行性能测试对比,迭代循环中,我们将对数据进行过滤、分组等操作。分别进行以下几组测试: 结论: 在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。所以在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。 在串行处理操作中,Stream 在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过 Java8 中的 Spliterator 迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。 在并行处理操作中,Stream 对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream 将结合 ForkJoin 框架对集合进行切片处理,ForkJoin 框架将每个切片的处理结果 Join 合并起来。最后就是要注意 Stream 的使用场景。 Java8 Stream流 标签:its walk basic 服务器配置 并发处理 character http char 最大值 原文地址:https://www.cnblogs.com/Dm920/p/13365719.html1. 概述
1-1. Stream理解
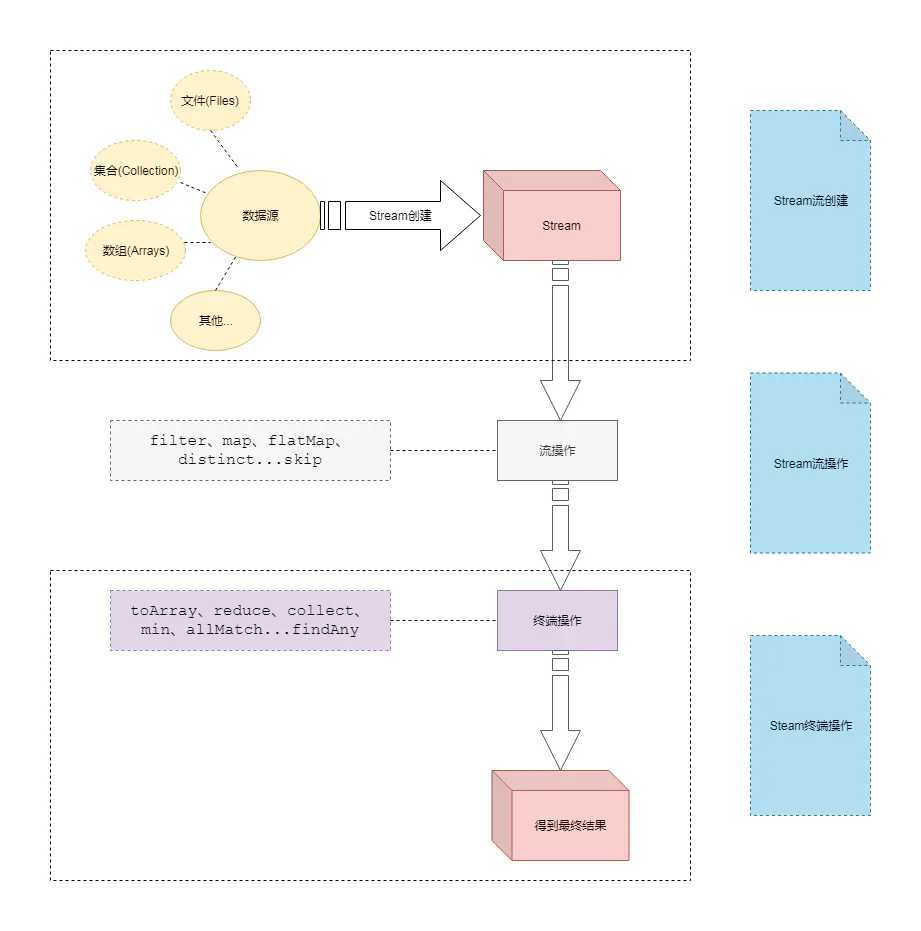
1-2. Stream流程
原集合 —> 流 —> 各种操作(过滤、分组、统计) —> 终端操作
1-3. Stream流简单演示


public class Student {
private String name; // 姓名
private String sex; // 性别
private int hight; // 身高
public Student(String name, String age, int hight) {
this.name = name;
this.sex = age;
this.hight = hight;
}
// Get And Set
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getHight() {
return hight;
}
public void setHight(int hight) {
this.hight = hight;
}
@Override
public String toString() {
return "Student{" +
"name=‘" + name + ‘\‘‘ +
", sex=‘" + sex + ‘\‘‘ +
", hight=" + hight +
‘}‘;
}
}
public class Test {
public static void main(String[] args) {
List
public class Test {
public static void main(String[] args) {
List
2. Stream流创建
2-1. 集合作为Stream数据源
① stream()
List
// 使用List创建一个流对象
Stream② parallelStream()
List
// 使用List创建一个流对象
Stream● parallelStream() 与 stream() 的区别
2-2. 数组作为Stream数据源
int[] intArray = new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 使用数组创建一个流对象
IntStream stream = Arrays.stream(intArray);
// TODO: 对流对象做处理
2-3. BufferedReader作为Stream数据源
File file = new File("/home/src/main/resources/application.yml");
try {
// 把文件里面的内容一行一行的读出来
BufferedReader in = new BufferedReader(new FileReader(file));
// 生成一个Stream对象
Stream
2-4. File作为Stream数据源
① Files.list()
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 找到指定path下的所有的文件
Stream
② Files.walk()
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 第二个参数用于指定遍历几层
Stream
③ Files.find()
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 找到指定path下的所有不是目录的文件
Stream
④ Files.lines()
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 找到指定path下的所有不是目录的文件
Stream
2-5. 自己构建Stream
① Stream.of()
Stream
② Stream.iterate()
// Stream.iterate() 流式迭代器
Stream
③ Stream.generate()
// Stream.generate() 生成无限流
Stream
④ Stream.build()
// Stream.builder() 构造一个 Stream 对象
Stream.Builder
2-6. 其他Stream创建方式
3. Stream流操作 与 终端操作
3-1. Stream流操作(操作符)
Stream流操作符
解释
filter
对流里面的数据做过滤操作
map
对流里面每个元素做转换
mapToInt
把流里面的每个元素转换成int
mapToLong
流里面每个元素转换成long
mapToDouble
流里面每个元素转换成double
flatMap
流里面每个元素转换成Steam对象,最后平铺成一个Stream对象
flatMapToInt
流里面每个元素转换成IntStream对象,最后平铺成一个IntStream对象
flatMapToLong
流里面每个元素转换成LongStream对象,最后平铺成一个LongStream对象
flatMapToDouble
流里面每个元素转换成DoubleStream对象,最后平铺成一个DoubleStream对象
distinct
去重
sorted
对流里面的元素排序
peek
查看流里面的每个元素
limit
返回前n个数
skip
跳过前n个元素
3-2. Stream流终端操作
终端操作符
解释
forEach
遍历
forEachOrdered
如果流里面的元素是有顺序的则按顺序遍历
toArray
转换成数组
reduce
归约 - 根据一定的规则将Stream中的元素进行计算后返回一个唯一的值
collect
收集 - 对处理结果的封装
min
最小值
max
最大值
count
元素的个数
anyMatch
任何一个匹配到了就返回true
allMatch
所有都匹配上了就返回true
noneMatch
没有一个匹配上就返回true
findFirst
返回满足条件的第一个元素
findAny
返回某个元素
3-2-1. collect()
3-2-1-1. Collector
/**
* Collector是专门用来作为Stream的collect方法的参数的
*
* 泛型含义
* T:是流中要收集的对象的泛型
* A:是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
* R:是收集操作得到的对象(通常但不一定是集合)的类型。
*/
public interface Collector
// 自己来组装Collector,返回一个List
@Test
public void collectNew() {
Stream
> supplier() {
return new Supplier
>() {
@Override
public List
, Integer> accumulator() {
return new BiConsumer
, Integer>() {
@Override
public void accept(List
> combiner() {
return new BinaryOperator
>() {
@Override
public List
, List
, List
4. 合理使用 Stream
测试
结论(迭代使用时间)
多核 CPU 服务器配置环境下,对比长度 100 的 int 数组的性能;
常规的迭代 Stream 并行迭代 Stream 串行迭代
多核 CPU 服务器配置环境下,对比长度 1.00E+8 的 int 数组的性能;
Stream 并行迭代 常规的迭代 Stream 串行迭代
多核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能;
Stream 并行迭代 常规的迭代 Stream 串行迭代
单核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能;
常规的迭代 Stream 串行迭代 Stream 并行迭代
5. 总结
上一篇:进程调度&调度算法
下一篇:Java继承