MapReduce编程模型详解(基于Windows平台Eclipse)
2021-04-13 02:27
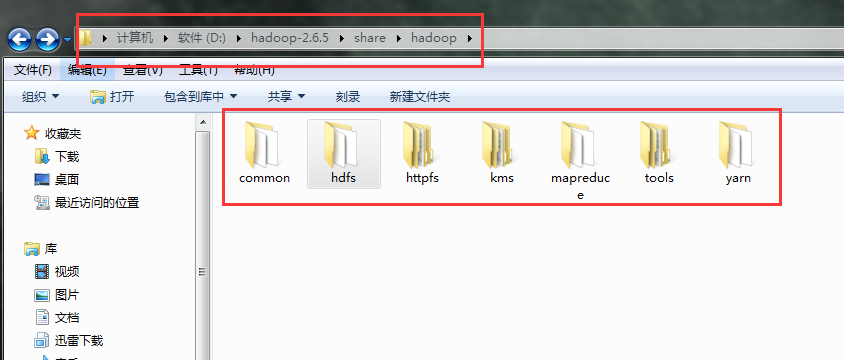
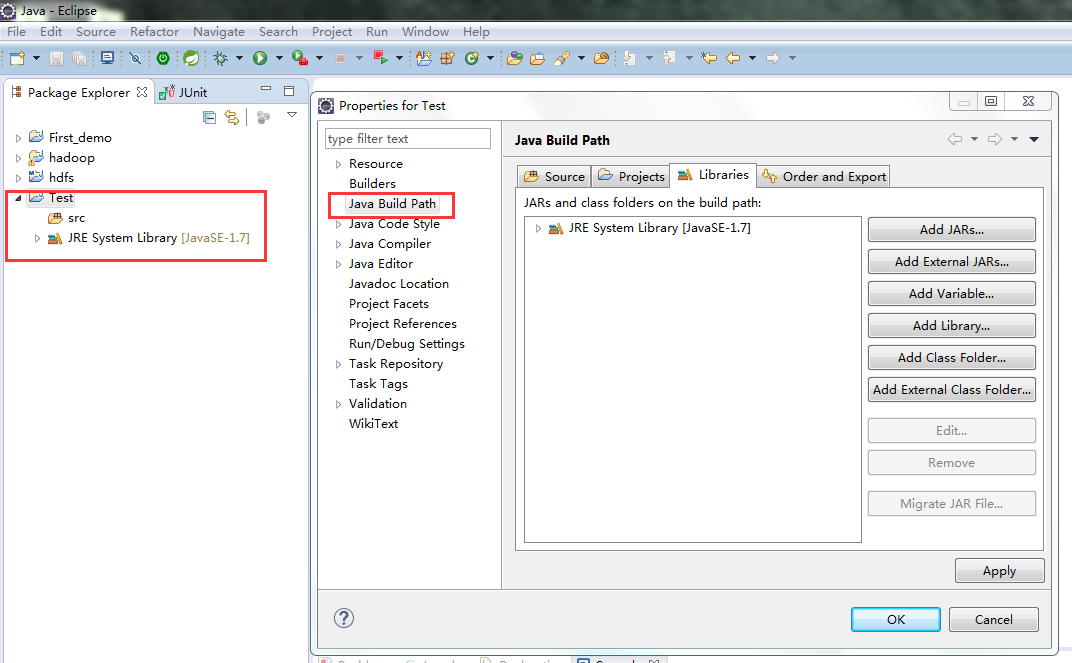
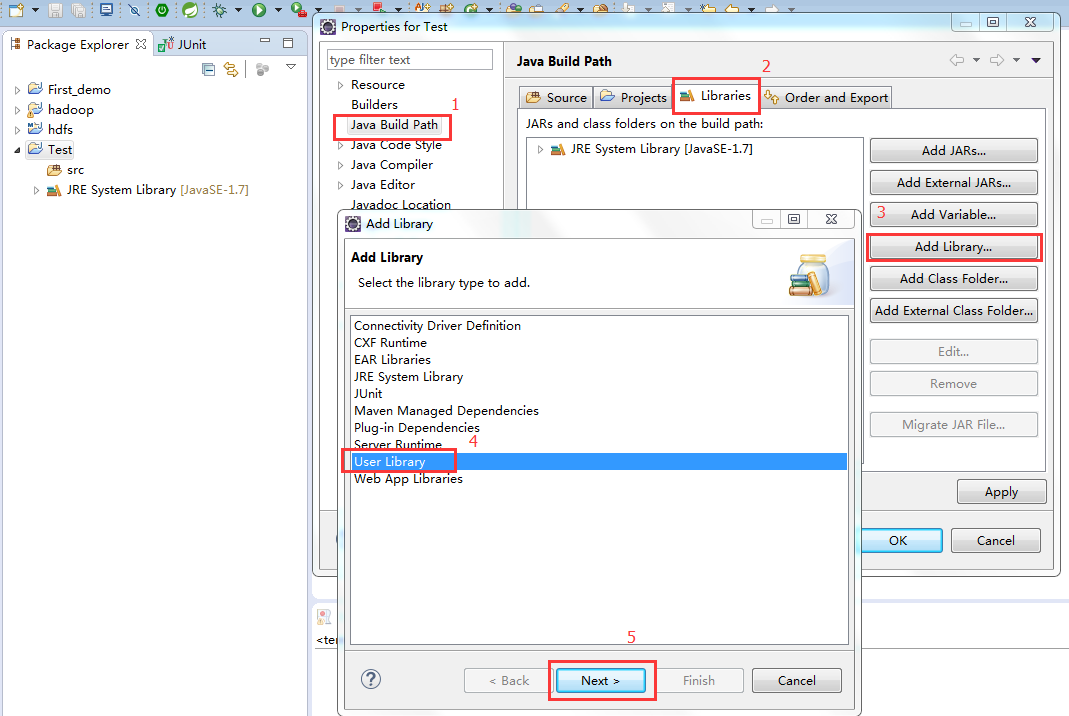
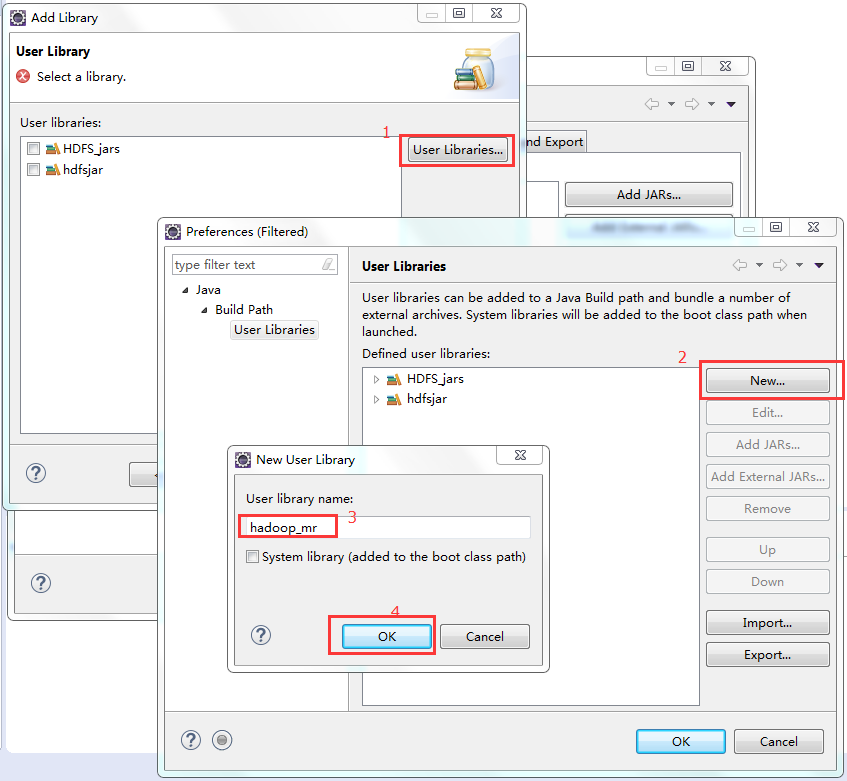
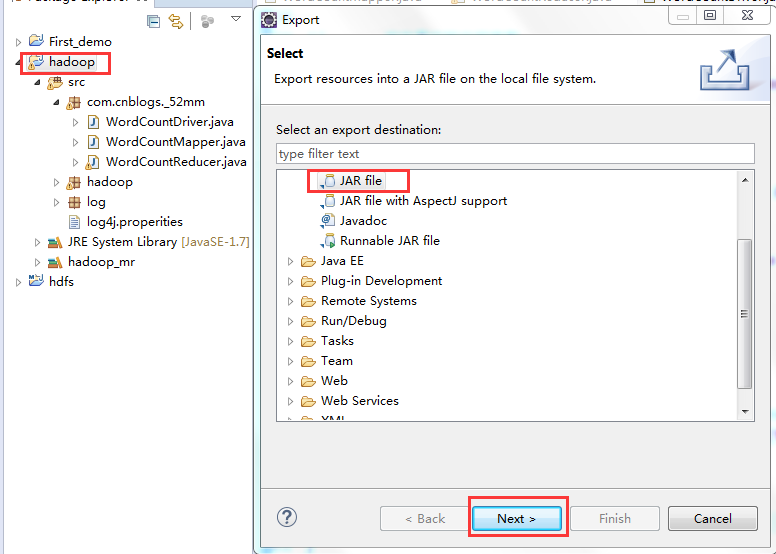
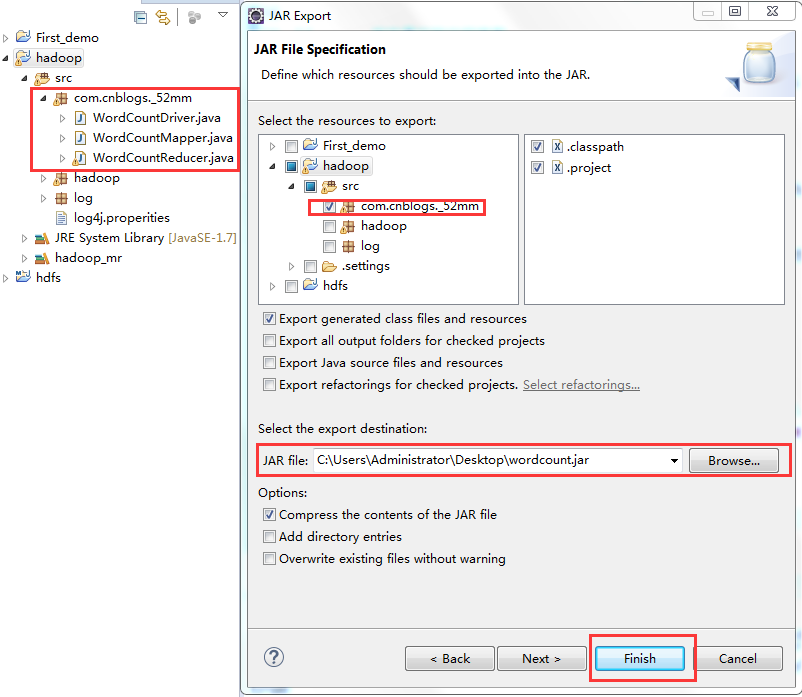
标签:装包 传递 www. orm 完成 rabl sort tin exist 本文基于Windows平台Eclipse,以使用MapReduce编程模型统计文本文件中相同单词的个数来详述了整个编程流程及需要注意的地方。不当之处还请留言指出。 hadoop集群的搭建 1、将官网下载的hadoop安装包解压,并记住下图所示的目录 2、创建java project,右键工程--->build path--->Configure build path 3、进行如下图操作 4、新建MapReduce编程要使用的环境包,如下图操作 5、将下图所示的commom包以及lib文件夹下所有的包导入 6、将下图所示的hdfs包和lib文件夹下所有的包导入 7、将下图所示的包以及lib文件夹下所有的包导入 8、将下图所示的包以及lib文件夹下的所有包导入 9、将新建的好的hadoop_mr库导入 1、打jar包(鼠标右键工程-->Export) 2、上传到hadoop集群上(集群中的任何一台都行),运行 3、也可用yarn的web界面查看作业信息 ps:在这里可以看到作业的详细信息,失败还是成功一目了然 4、查看输出结果 也可查看hdfs的web界面 该错误是由于编写代码时impor了错误的包导致的(我错在Text包导错了),仔细检查一下,改正后重新打jar包上传。 显然,该错误是由于reduce的输出目录必须是不存在才行,不能自己在hdfs上手动创建输出目录。 作者:py小杰 博客地址:http://www.cnblogs.com/52mm/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显开头给出原文链接。 MapReduce编程模型详解(基于Windows平台Eclipse) 标签:装包 传递 www. orm 完成 rabl sort tin exist 原文地址:https://www.cnblogs.com/52mm/p/p12.html前期准备
编程环境搭建
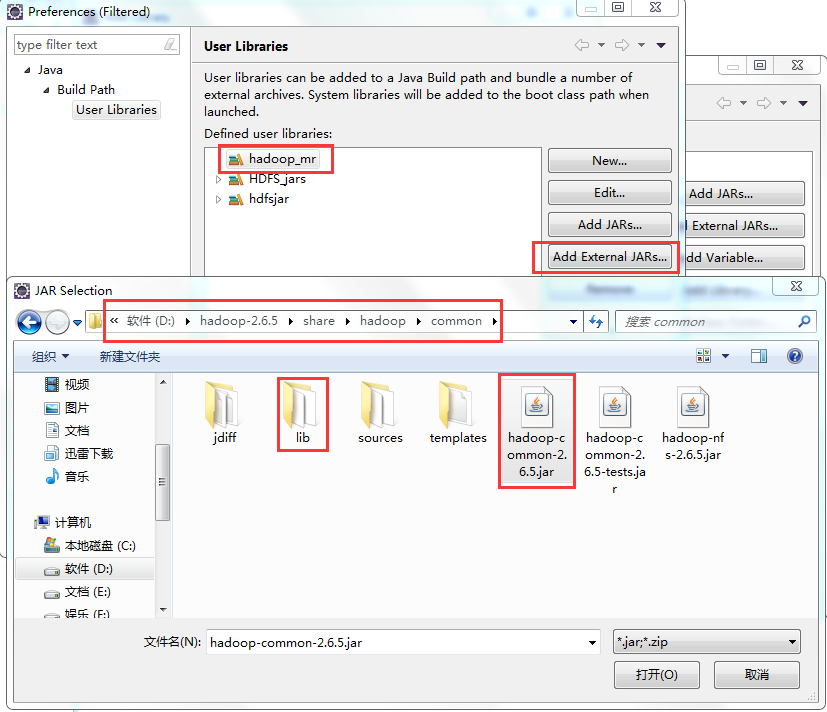
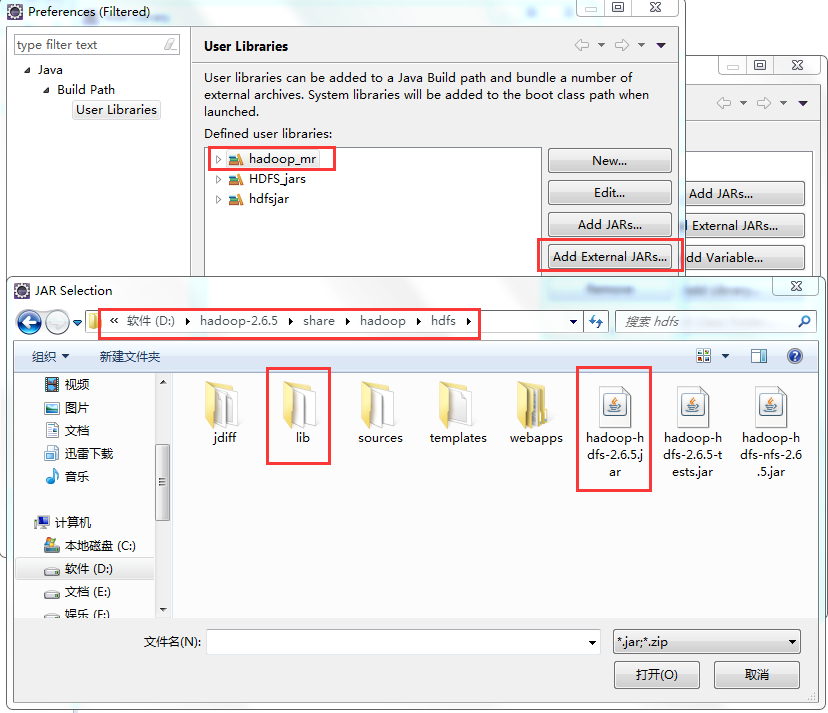
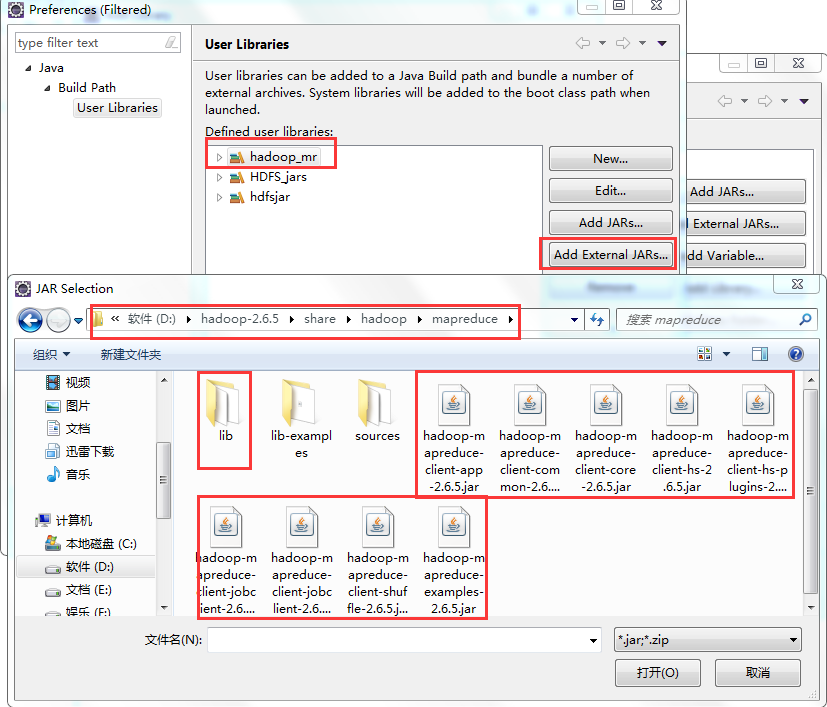
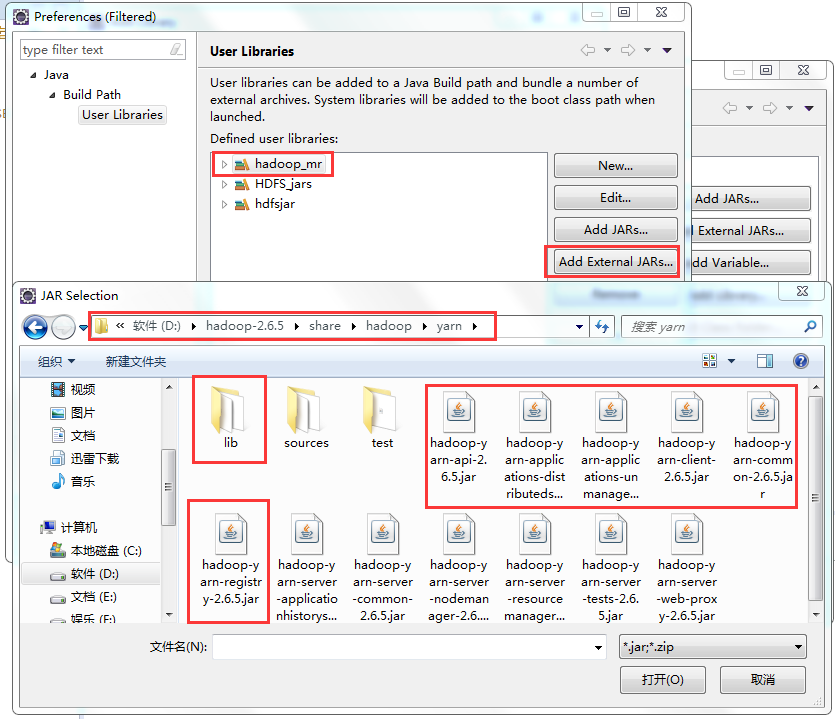
编写map阶段的map函数
package com.cnblogs._52mm;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 第一个参数:默认情况下是mapreduce框架所读文件的起始偏移量,类型为Long,在mr框架中类型为LongWritable
* 第二个参数:默认情况下是框架所读到的内容,类型为String,在mr框架中为Text
* 第三个参数:框架输出数据的key,在该单词统计的编程模型中输出的是单词,类型为String,在mr框架中为Text
* 第四个参数:框架输出数据的value,在此是每个所对应单词的个数,类型为Integer,在mr框架中为IntWritable
* @author Administrator
*
*/
public class WordCountMapper extends Mapper编写reduce阶段的reduce函数
package com.cnblogs._52mm;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* reduce的输入是map的输出
* 第一个和第二个参数分别是map的输出类型
* 第三个参数是reduce程序处理完后的输出值key的类型,单词,为Text类型
* 第四个参数是输出的value的类型,每个单词所对应的总数,为IntWritable类型
* @author Administrator
*
*/
public class WordCountReducer extends Reducer编写驱动类
package com.cnblogs._52mm;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于yarn集群的客户端,封装mapreduce的相关运行参数,指定jar包,提交给yarn
* @author Administrator
*
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 将默认配置文件传给job
Job job = Job.getInstance(conf);
// 告诉yarn jar包在哪
job.setJarByClass(WordCountDriver.class);
//指定job要使用的map和reduce
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 指定map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定最终输出的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job的输入数据所在的目录
// 第一个参数:给哪个job设置
// 第二个参数:输入数据的目录,多个目录用逗号分隔
FileInputFormat.setInputPaths(job, new Path(args[0]));
// job的数据输出在哪个目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将jar包和配置文件提交给yarn
// submit方法提交作业就退出该程序
// job.submit();
// waitForCompletion方法提交作业并等待作业执行
// true表示将作业信息打印出来,该方法会返回一个boolean值,表示是否成功运行
boolean result = job.waitForCompletion(true);
// mr运行成功返回true,输出0表示运行成功,1表示失败
System.exit(result?0:1);
}
}运行MapReduce程序
#wordcounrt.jar是刚刚从eclipse打包上传到linux的jar包
#com.cnblogs._52mm.WordCountDriver是驱动类的全名
#hdfs的/wordcount/input目录下是需要统计单词的文本
#程序输出结果保存在hdfs的/wordcount/output目录下(该目录必须不存在,由hadoop程序自己创建)
hadoop jar wordcount.jar com.cnblogs._52mm.WordCountDriver /wordcount/input /wordcount/output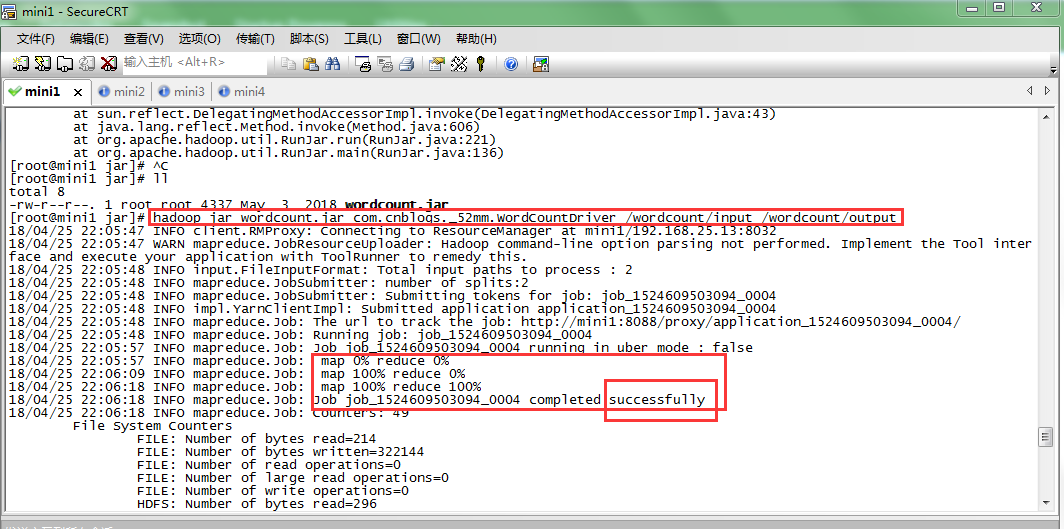
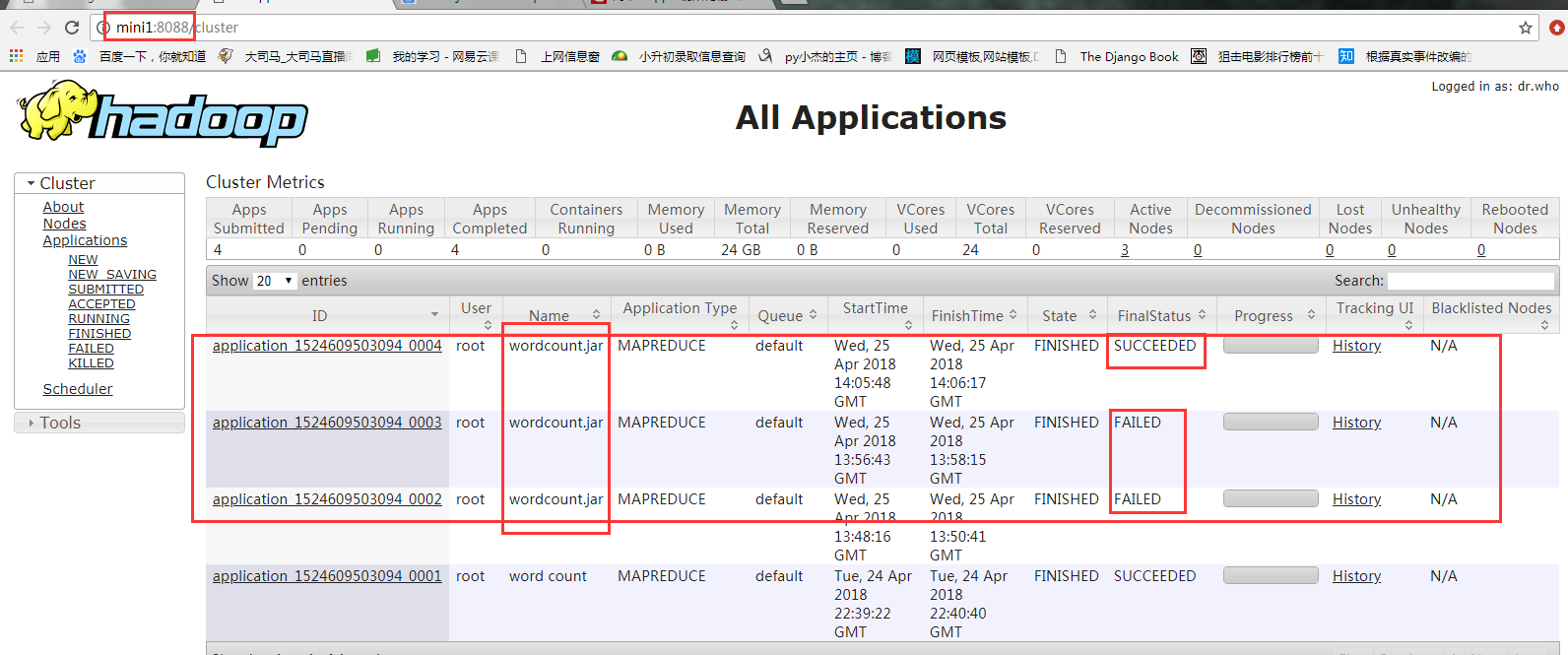
hadoop fs -cat /wordcount/output/part-r-00000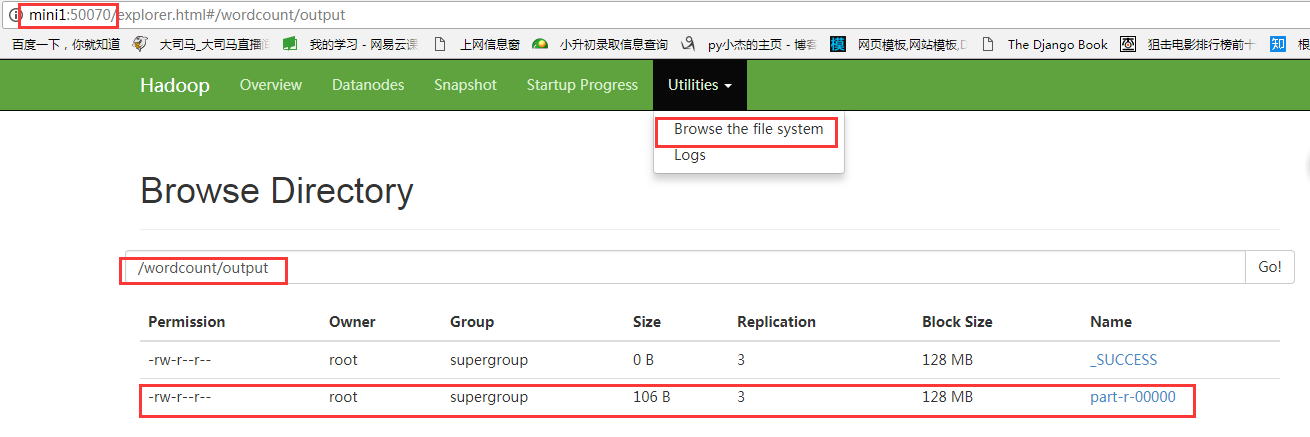
报错解决
Error: java.io.IOException: Unable to initialize any output collector
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:412)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector. Output directory hdfs://mini1:9000/wordcount/output already exists总结
文章标题:MapReduce编程模型详解(基于Windows平台Eclipse)
文章链接:http://soscw.com/index.php/essay/74993.html