IDE将C++源码生成为可执行文件过程
2021-04-14 21:27
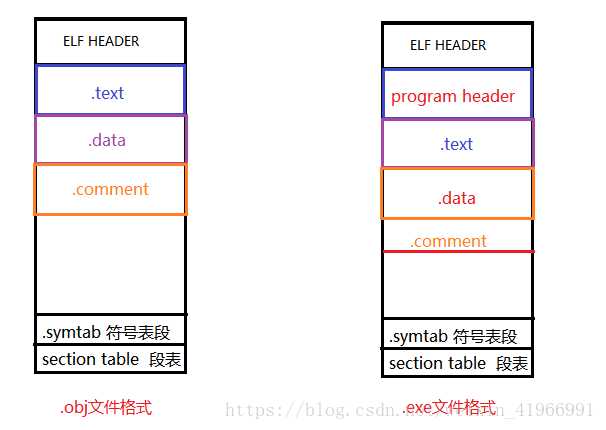
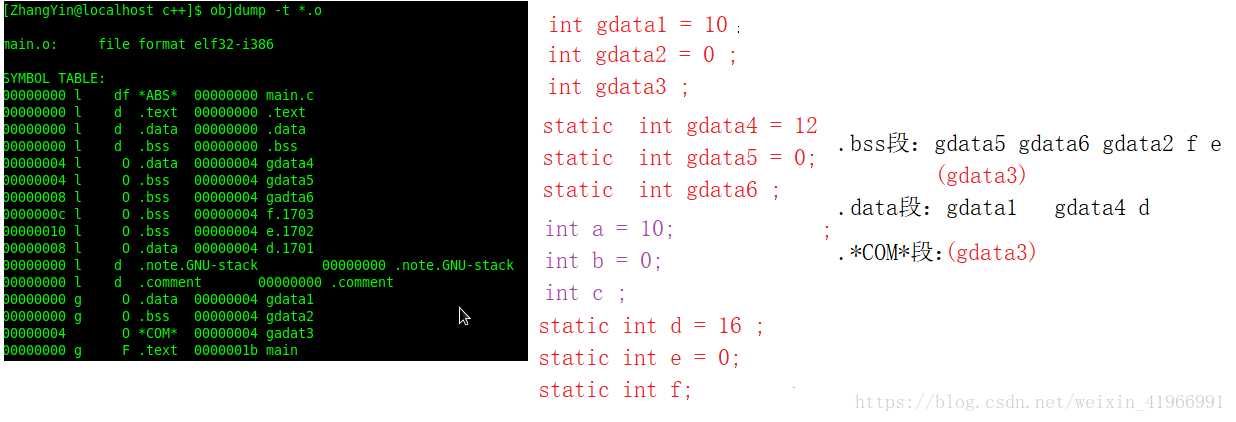
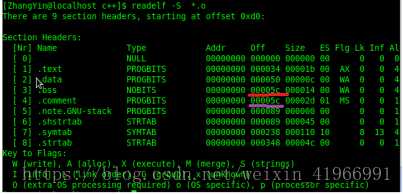
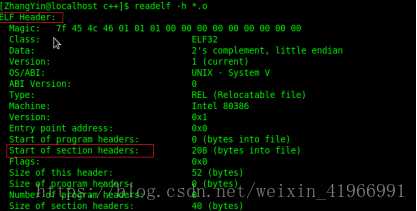
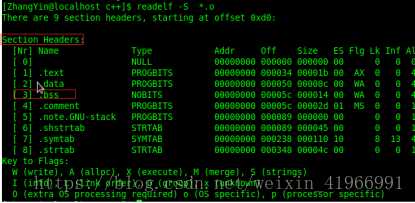
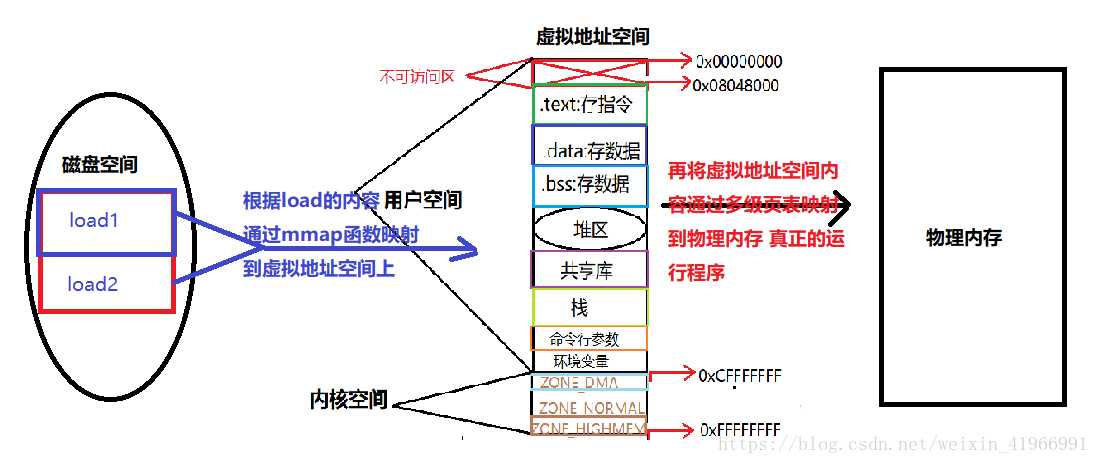
标签:load 强类型 同名 代码 链接库 win 节省空间 疑惑 汇编代码 使用VS2017和Qt5.12.4。(Windows10) 点击生成到生成成功大概有这几个步骤: 源码 -> 预处理 -> 编译和优化 -> 生成目标文件 -> 链接 -> 生成可执行文件 1.源码(编辑器) 自己键盘敲出来的程序代码(或者ctrl + c)。 2.预处理(预处理器) 主要负责以下的几处: 1.宏的替换 2.删除注释 3.处理预处理指令,如#include,#ifdef 4.生成一个.i文件 3.编译和优化() 将预处理阶段生成的*.i文件生成相应的汇编文件 4.生成目标文件(编译器) 将汇编文件翻译为目标机器指令 5.链接(链接器) 项目生成的目标文件和包含的依赖库文件链接,生成可执行文件。 太复杂了,现在还理解不透。。。 插入个链接https://blog.csdn.net/weixin_41966991/article/details/81152490 今天博文主要讨论的问题是:我们编写的程序代码是怎样运行起来的?到底运行的是什么内容?平时我们所说的编译主要包括预编译、编译、汇编三部分,这三部分分别都干什么工作,主要职能有哪些,接下来我们一步步探讨总结。 (一)预编译 (1)由源文件“.cpp/.c”生成“.i”文件,这是在预编译阶段完成的;gcc -E .cpp/.c --->.i (2)主要功能 展开所有的宏定义,消除“#define”; (二)编译---核心 编译过程就是把经过预编译生成的文件进行一系列语法分析、词法分析、语义分析优化后生成相应的汇编代码文件。 (1)由“.i”文件生成“.s”文件,这是在编译阶段完成的;gcc -S .i --->.s (2)主要功能 词法分析:将源代码文件的字符序列划分为一系列的记号,一般词法分析产生的记号有:标识符、关键字、数字、字符串、特殊符号(加号、等号);在识别记号的同时也将标识符放好符号表、将数字、字符放入到文字表等;有一个lex程序可以实现词法扫描,会按照之前定义好的词法规则将输入的字符串分割成记号,所以编译器不需要独立的词法扫描器; 如果存在括号不匹配或者表达式错误,编译器就会报告语法分析阶段的错误;相同的存在一个yacc程序可以根据用户输入的语法规则生成语法树; 语义分析:由语法阶段完成分析的并没有赋予表达式或者其他实际的意义,比如乘法、加法、减法,必须经过语义阶段才能赋予其真正的意义; 优化后生成相应的汇编代码文件 (1)由“.s”文件生成的“.obj”文件;gcc -c .s-->.o; (2)此文件中生成符号表,能够产生符号的有:所有数据都要产生符号、指令只产生一个符号(函数名); (四)链接 链接阶段主要分为两部分: (1)合并所有“.obj”文件的段并调整段偏移和段长度(按照段的属性合并,属性可以是“可读可写”、“只读”、“可读可执行”,合并后将相同属性的组织在一个页面内,比较节省空间),合并符号表,进行符号解析完成后给符号分配地址;其中符号解析的意思是:所有.obj符号表中对符号引用的地方都要找到该符号定义的地方。在编译阶段,有数据的地方都是0地址,有函数的额地方都是下一行指令的偏移量-4(由于指针是4字节);可执行文件以页面对齐。 符号重定位举例:main.c extern int gdata; test.c int gdata = 10; main.o *UND* gdata -------->test.o gdata //符号重定位 在进行符号解析时要注意只对global符号进行处理,对于local符号不做处理; (2)符号的重定位(链接核心):将符号分配的虚拟地址写回原先未分配正确地址的地方 对于数据符号会存准确地址,对于函数符号,相对于存下一行指令的偏移量(从PC寄存器取地址,并且PC中下一行指令的地址) (五)程序的运行 (1)创建虚拟地址空间到物理空间的映射(创建内核地址映射结构体),创建页目录和页表; (2)加载代码段和数据段 (3)把可执行文件的入口地址写到CPU的PC寄存器里 (六)目标文件类型 Linux下的ELF文件主要有以下四种: (1)可重定位文件.obj,这种文件包括数据和指令,可以被链接成为可执行文件(.exe)或者共享目标文件(.so),静态链接库可以归为这一类; (2)可执行文件.exe,这种文件包含了可以直接运行的程序,它的代表就是ELF可执行文件,他们一般都没有扩展名; (3)共享目标文件.so,这种文件包含了数据和指令,可以在以下两种情况下使用:一是链接器使用这种文件与其他可重定位文件和共享目标文件链接,二是动态链接器将几个共享目标文件与可执行文件结合,作为进程映像的一部分使用。 (4)核心转储文件,当进程意外终止时,系统可以将该进程的地址空间的内容及种植的一些信息转储到核心文件中,比如core dump文件。 (七)可重定位文件与可执行文件的结构比较 在编译链接的全过程中,汇编完成后生成“可重定位的二进制文件.obj”,链接阶段完成后生成可执行文件.exe,这两者有何区别呢?可重定位文件为什么不可以运行?接下来将比较这种文件的结构布局,以回答上面的疑惑。 当一个程序运行时,操作系统会给进程分配的虚拟地址空间以达到每个进程都有自己独立的运行空间,但是各个进程空间共享内核空间,在32位下,这个空间大小为4G,在64位下,这个虚拟地址空间为8G;下图为32为下虚拟地址空间的布局: 其中内核空间中的ZONE_DMA 直接内存访问,占16M,用于磁盘与内存的文件数据交换; ZONE_NORMAL :平时使用的正常的内核空间; ZONE_HIGHMEM:高端内存处理。处理高端内存大于1G的数据;(64位没有)由于此空间非常大以至于映射后的虚拟地址空间不足。 (1)可重定位文件(.obj)的组织布局和可执行文件(.exe)组织格式的比较 (1)readelf -h *.o 查看 .o文件的文件头ELF HEADER信息,包括class(一般为32位)、data、program header、一些地址记录、size记录等;改变(函数入口地址0x0+符号0x0,汇编阶段完成后) readelf -S *.o 查看section headers 中的内容 包括段的内容、偏移量、属性等; objdump -d *.o objdump -S *.o 得到汇编后的机器码文件 objdump -t *.o 查看符号表 objdump -h *.o 查看.o文件的各个段(常用的段.data/.text/.bss/.comment) (2)在虚拟地址空间上存在的.bss段主要存储未初始化的或者初始化为0的全局变量或者静态变量,但是在.obj和.exe中并不存在此段,那么上述中的数据存储在文件的哪里呢?答案是存储在了“*.comment*”块中,这是因为存在强弱数据类型所导致的,请看下图中所示的情况: 原则上根据.bss的存储内容可以得知gdata3其空间存储,但是却放在了.comment块中,gdata3是一个弱类型,其原因是由于我们不确定其他文件是否会存在同名强类型或者大于其字节数的弱类型出现,造成外文件的变量引用,因此,先将其存放在*COM*中;强弱类型的区分为:强类型(已经初始化的变量)、弱类型(未初始化的变量)。使用规则是: 在.c文件中,假如我们同一目录下的main.c和test.c文件中两者优先规则: (1)两个文件中都同时定义了int类型的x变量,那么在编译时会提醒有重定义类型; (2)两个文件中强类型和弱类型都存在时,选择强类型; (3)两个文件中弱类型同时出现时,选择字节数大的弱类型; 从上图中看到.obj文件中的段信息中.bss 和.comment占据同一地址,说明.bss段并未占据文件空间,只占据虚拟地址空间;那么我们如何知道虚拟地址空间中.bss段是否存有数据。请看下图所示布局信息: 从上面两幅图中可以看到用readelf -h *.o可以查看文件头ELF HEADER 信息,其中包括section header,而通过readelf -S *.o可以查看到段的所有信息,从而看到.bss段是否存有数据。 (3)从obj 和exe的组织形式比较中发现,exe文件比obj多了一个program header 域,可使用readelf -l 可执行文件名 查看program header域的具体信息,如下图所示: 由于我们运行程序只加载数据和指令,并且我们所有的obj文件和exe文件都是以“页”为对齐方式,同时每个页存储的内容按照属性进行分页存储,所以program header有两个加载页面,只有将数据和指令存储于页中才能真正的给符号分配地址从而运行程序。数据有只读和只写、指令有只读和执行,故而可以根据这个属性确定那些段应该放在哪一个页中,这个属性以及只能加载数据和指令决定了只存在两个load页在磁盘上。到这里为止,我们已经准备好了这个程序可以运行的所有条件。此时可执行文件里的内容按照load的布局被存储在磁盘中,那么如何运行呢?由下面这幅图来说明: 从上图就可以看出一个程序从编译链接到运行的全过程。 欢迎大家留言指出不足。 IDE将C++源码生成为可执行文件过程 标签:load 强类型 同名 代码 链接库 win 节省空间 疑惑 汇编代码 原文地址:https://www.cnblogs.com/linxisuo/p/13268531.html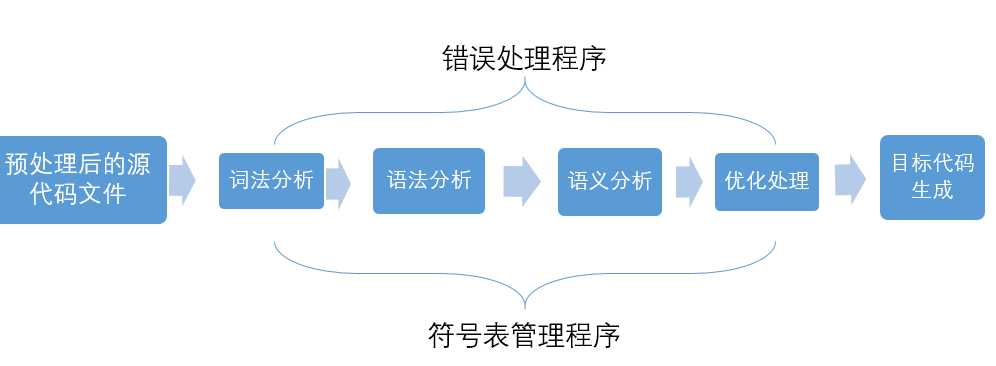
处理所有的预编译指令,比如#if、#ifdef等;
处理#include预编译指令,将包含文件插入到该预编译的位置;
删除所有的注释“/**/”、"//"等;
添加行号和文件名标识,以便于编译时编译器产生调试用的行号信息以及错误提醒;
保留所有的#program编译指令,原因是编译器要使用它们;
(3)缺点:不进行任何安全性及合法性检查
语法分析:语法分析器将对产生的记号进行语法分析,产生语法树----就是以表达式尾节点的树,一步步判断如何执行表达式操作。下图为一个语法树: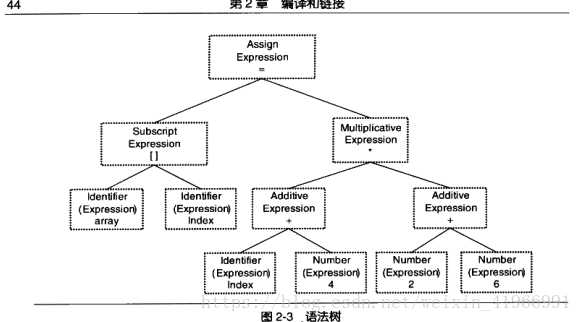
语义分析主要分为静态语义和动态语义两种;静态语义通常包括声明和类型的匹配、类型的转换。比如当一个浮点型的表达式赋值给一个整型的表达式时,其中隐含了一个浮点型到整型转换的过程。只要存在类型不匹配编译器会报错。经过语义分析后的语法树的所有表达式都有了类型。动态语义分析只有在运行阶段才能确定;
汇总所有符号
(三)汇编:生成可重定位的二进制文件;(.obj文件)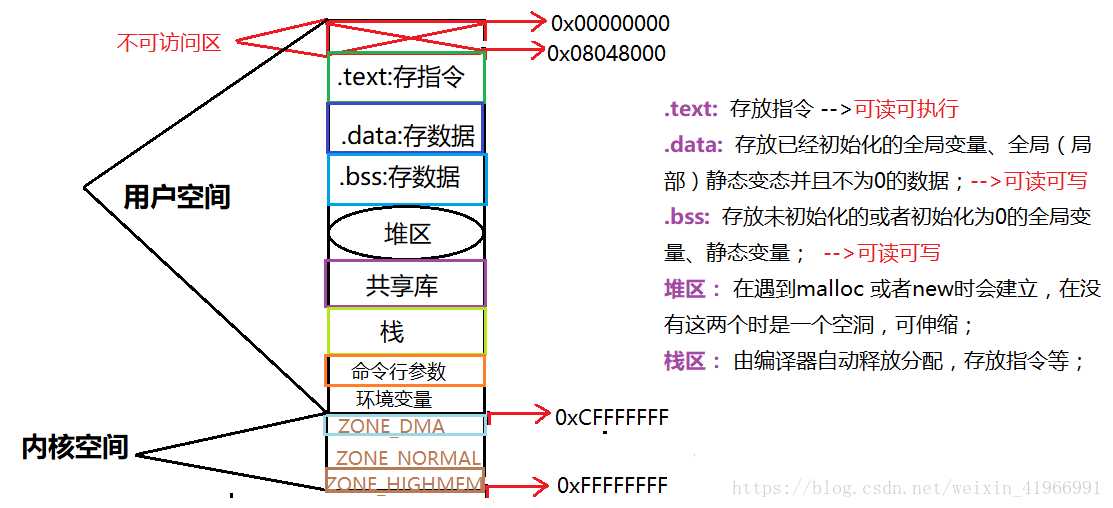
————————————————
版权声明:本文为CSDN博主「zhangyin_blog」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_41966991/java/article/details/81152490
下一篇:python实现事件驱动模型
文章标题:IDE将C++源码生成为可执行文件过程
文章链接:http://soscw.com/index.php/essay/75819.html