Spring5-Reactor函数式编程
2021-04-19 00:27
标签:函数 sum war 总结 project span verify extends spring 反应式编程是一种可以替代命令式编程的编程范式。这种可替代性存在的原因在于反应式编程解决了命令式编程中的一些限制。理解这些限制,有助于你更好地理解反应式编程模型的优点 对比 Java 中的流 Java的流和反应式流Java的流和反应式流之间有很多相似之处。首先,它们的名字中都有流(Stream)这个词。 它们还提供了用于处理数据的函数式API。事实上,正如你稍后将会在介绍Reactor时看到的那样,它们甚至可以共享许多相同的操作。 Java的流通常都是同步的,并且只能处理有限的数据集。从本质上来说,它们只是使用函数来对集合进行迭代的一种方式。 反应式流支持异步处理任意大小的数据集,同样也包括无限数据集。只要数据就绪,它们就能实时地处理数据,并且能够通过回压来避免压垮数据的消费者。 反应式流规范 反应式流规范可以总结为4个接口:Publisher、Subscriber、Subscription和Processor。 Publisher负责生成数据,并将数据发送给Subscription(每个Subscriber对应一个Subscription)。 Publisher接口声明了一个方法subscribe(),Subscriber可以通过该方法向Publisher发起订阅。反应式流规范
public interface PublisherT> {
void subscribe(Subscriber super T> var1);
}
public interface PublisherT> {
void subscribe(Subscriber super T> var1);
}
public interface SubscriberT> {
void onSubscribe(Subscription var1);
void onNext(T var1);
void onError(Throwable var1);
void onComplete();
}
public interface Subscription {
void request(long var1);
void cancel();
}
public interface ProcessorT, R> extends SubscriberT>, PublisherR> {
}
初识Reactor
Reactor项目是反应式流规范的一个实现,提供了一组用于组装反应式流的函数式API。
反应式编程要求我们采取和命令式编程不一样的思维方式。此时我们不会再描述每一步要进行的步骤,反应式编程意味着要构建数据将要流经的管道。当数据流经管道时,可以对它们进行某种形式的修改或者使用。
命令式编程:
String a = "Apple";
String s = a.toUpperCase();
String s1 = "hello" + s + "!";
System.out.println(s1);
反应式编程:
Mono.just("Apple")
.map(String::toUpperCase)
.map(x-> "hello" + x + "!")
.subscribe(System.out::println);
控制台:
helloAPPLE!
14:36:38.685 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
helloAPPLE!
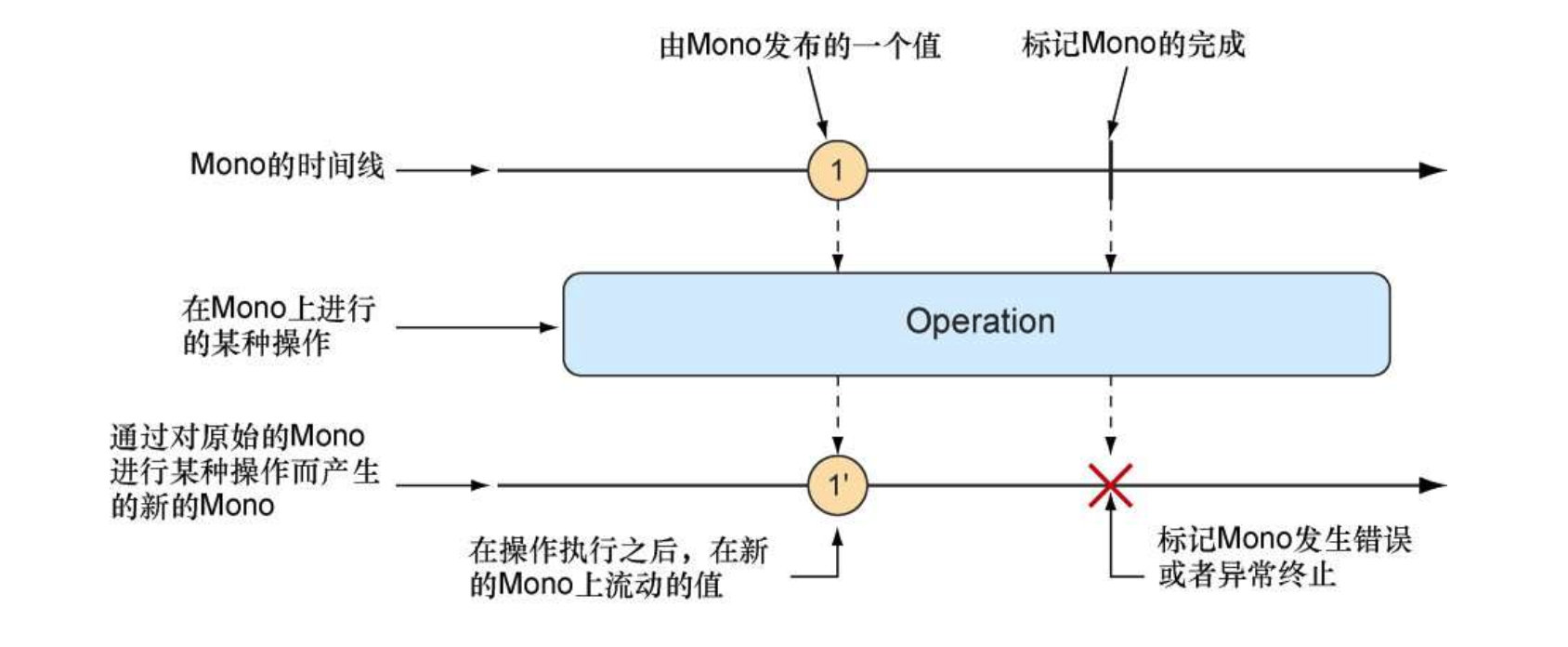
这个例子中的Mono是Reactor的两种核心类型之一,另一个类型是Flux。两者都实现了反应式流的Publisher接口。Flux代表具有零个、一个或者多个(可能是无限个)数据项的管道.
添加Reactor依赖
要开始使用Reactor,请将下面的依赖项添加到项目的构建文件中:
dependency>
groupId>io.projectreactorgroupId>
artifactId>reactor-coreartifactId>
dependency>
dependency>
groupId>io.projectreactorgroupId>
artifactId>reactor-testartifactId>
version>3.2.6.RELEASEversion>
scope>compilescope>
dependency>
使用常见的反应式操作
Flux和Mono是Reactor提供的最基础的构建块,而这两种反应式类型所提供的操作符则是组合使用它们以构建数据流动管线的黏合剂。
Flux和Mono共有500多个操作,这些操作都可以大致归类为:
•创建操作;
•组合操作;
•转换操作;
•逻辑操作。
- 1 创建
FluxString> fruitFlux = Flux.just("Apple","Orange");
fruitFlux.subscribe(System.out::println);
这里传递给subscribe()方法的lambda表达式实际上是一个java.util.Consumer,用来创建反应式流的Subscriber。在调用subscribe()之后,数据会开始流动。在这个例子中,没有中间操作,所以数据从Flux直接流向订阅者
要验证预定义的数据是否流经了fruitFlux,我们可以编写如下所示的测试代码:
StepVerifier.create(fruitFlux)
.expectNext("Apple")
.expectNext("Orange")
.verifyComplete();
在这个例子中,StepVerifier订阅了fruitFlux,然后断言Flux中的每个数据项是否与预期的水果名称相匹配。最后,它验证Flux在发布完“Strawberry”之后,整个fruitFlux正常完成。
还可以从数组 集合 Java Stream来作为Flux的源。
Listlist = Lists.newArrayList();
list.add("Apple");
list.add("Orange");
Flux stringFlux = Flux.fromIterable(list);
例如,要创建一个每秒发布一个值的Flux,你可以使用Flux上的静态interval() 方法,如下所示:
FluxLong> take = Flux.interval(Duration.ofSeconds(1)).take(5);
通过interval()方法创建的Flux会从0开始发布值,并且后续的条目依次递增。此外,因为interval()方法没有指定最大值,所以它可能会永远运行。我们也可以使用take()方法将结果限制为前5个条目
- 2 组合反应式类型
有时候,我们会需要操作两种反应式类型,并以某种方式将它们合并在一起。或者,在其他情况下,我们可能需要将Flux拆分为多种反应式类型
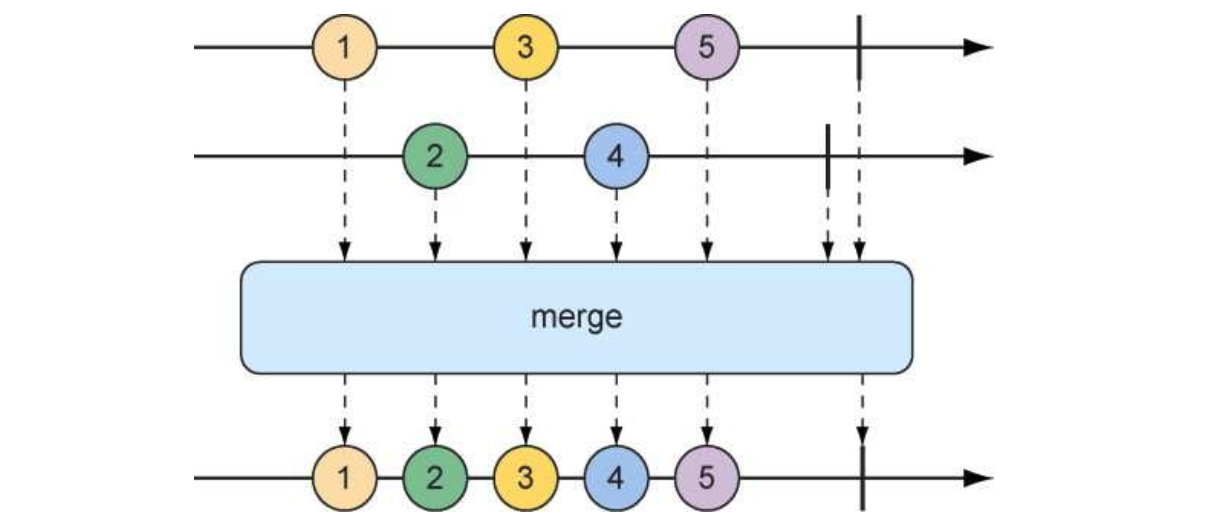
合并:
FluxString> fruitFluxA = Flux.just("Apple","Orange");
FluxString> fruitFluxB = Flux.just("Banana","watermelon");
fruitFluxA.mergeWith(fruitFluxB).subscribe(System.out::println);
com.ckj.superlearn.superlearn.base.ReactorStrategy
16:03:07.343 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
Apple
Orange
Banana
watermelon
Process finished with exit code 0
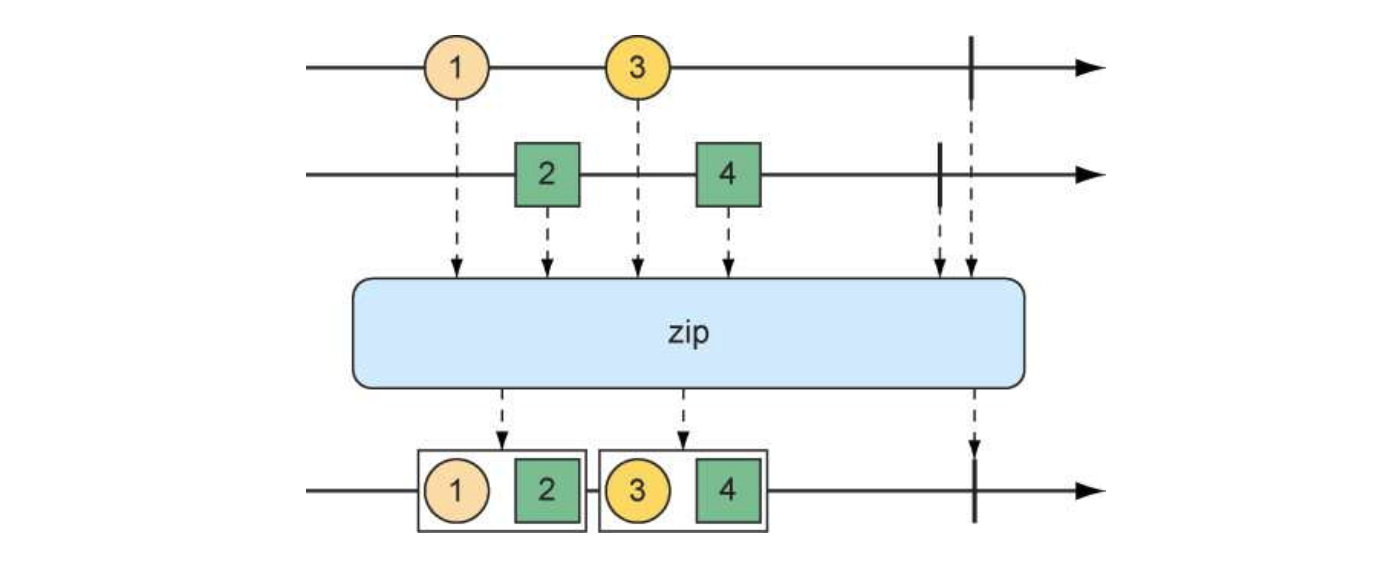
mergeWith()方法不能完美地保证源Flux之间的先后顺序,所以我们可以考虑使用zip()方法
FluxString> fruitFluxA = Flux.just("Apple","Orange").delayElements(Duration.ofMillis(10));
FluxString> fruitFluxB = Flux.just("Banana","watermelon").delayElements(Duration.ofMillis(50));
FluxString> allFlux = fruitFluxA.mergeWith(fruitFluxB);
allFlux.subscribe(x-> System.out.println("allFlux:"+x));
FluxString, String>> zip = Flux.zip(fruitFluxA, fruitFluxB);
zip.subscribe(x-> System.out.println("zip:"+x));
Thread.sleep(1000);
控制台:
/com.ckj.superlearn.superlearn.base.ReactorStrategy
16:49:44.543 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
allFlux:Apple
allFlux:Orange
allFlux:Banana
zip:[Apple,Banana]
allFlux:watermelon
zip:[Orange,watermelon]
Process finished with exit code 0
- 3 转换和过滤反应式流
针对具有多个数据项的Flux,skip操作将创建一个新的Flux,它会首先跳过指定数量的数据项,然后从源Flux中发布剩余的数据项。下面的测试方法展示如何使用skip()方法:
FluxString> fruitFluxA = Flux.just("Apple","Orange","Banana","watermelon").skip(2);
fruitFluxA.subscribe(x->{
System.out.println(x);
});
/com.ckj.superlearn.superlearn.base.ReactorStrategy
17:05:00.141 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
Banana
watermelon
Process finished with exit code 0
与之对应相反的是take(www.keLezaix.com)
FluxString> fruitFluxA = Flux.just("Apple","Orange","Banana","watermelon").take(2);
fruitFluxA.subscribe(x->{
System.out.println(x);
});
com.ckj.superlearn.superlearn.base.ReactorStrategy
17:20:59.483 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
Apple
Orange
Process finished with exit code 0
filter()的过滤效果
FluxString> fruitFluxA = Flux.just("Apple","Orange","Banana","watermelon").take(2);
fruitFluxA.filter(www.yacuangyl.com www.lecaixuanzc.cn lexuancaizc.cn
System.out.println(x);
});
com.ckj.superlearn.superlearn.base.ReactorStrategy
17:24:03.242 [javachenglei.com ] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
Apple
Process finished with exit code 0
如何使用flatMap()方法和subscribeOn()方法
FluxString> fruitFluxA = Flux.just(www.tengyao3zc.cn www.anxinzc5.cn"Apple", "Orange", "Banana", "watermelon", "Apple", "Orange", "Banana",
"watermelon", "Apple", "Orange",www.yuntianyul.com www.jinliyld.cn "Banana", "watermelon", "Apple", "Orange", "Banana", "watermelon");
fruitFluxA.flatMap(Mono::just).map(String::toUpperCase).subscribeOn(Schedulers.parallel());
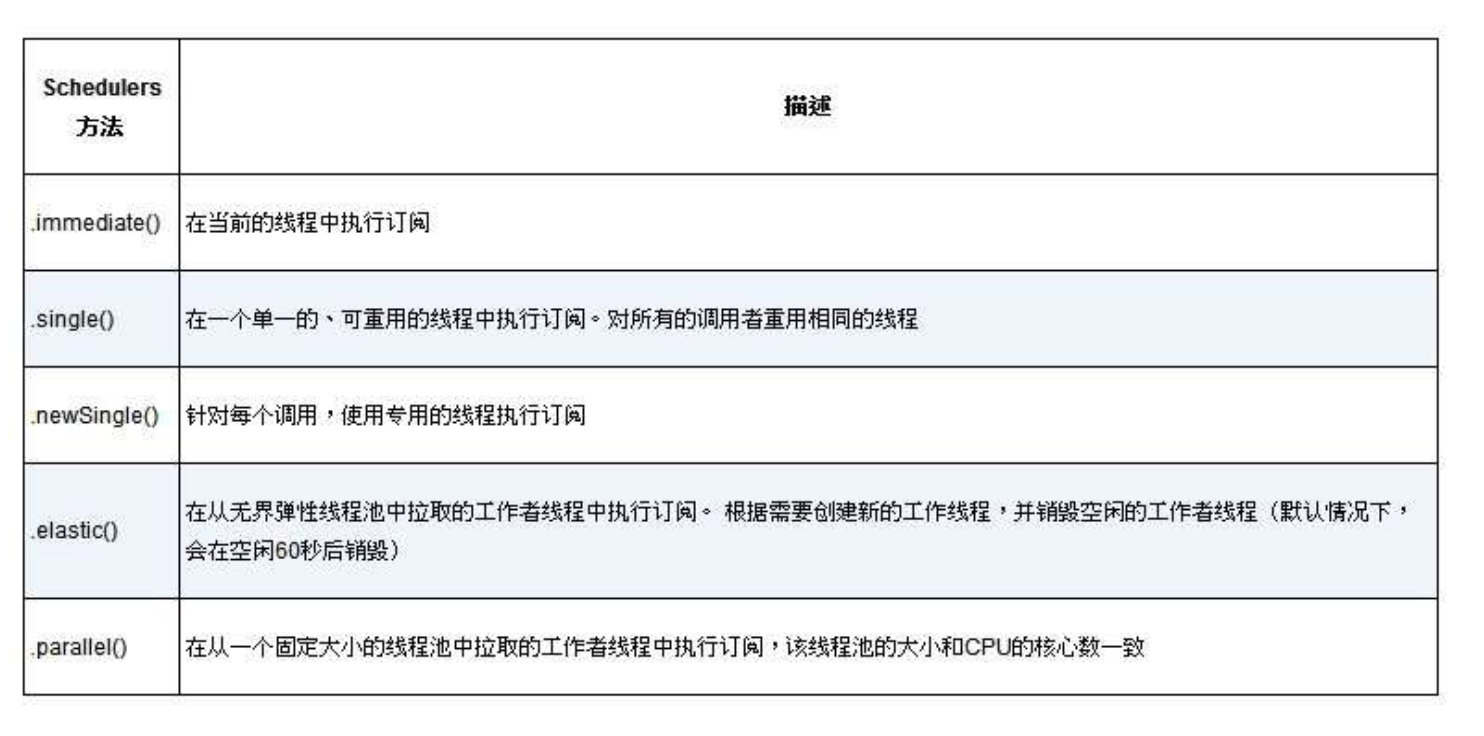
使用flatMap()和subscribeOn()的好处是:我们可以在多个并行线程之间拆分工作,从而增加流的吞吐量。因为工作是并行完成的,无法保证哪项工作首先完成,所以结果Flux中数据项的发布顺序是未知的
原创不易,如果觉得有点用的话,请毫不留情点个赞,转发一下,这将是我持续输出优质文章的最强动力。
Spring5-Reactor函数式编程
标签:函数 sum war 总结 project span verify extends spring
原文地址:https://www.cnblogs.com/woshixiaowang/p/13292482.html
上一篇:Java基础-位运算
文章标题:Spring5-Reactor函数式编程
文章链接:http://soscw.com/index.php/essay/76419.html