论文阅记 MobileNetV2:Inverted Residuals and Linear Bottlenecks
2021-04-19 01:28
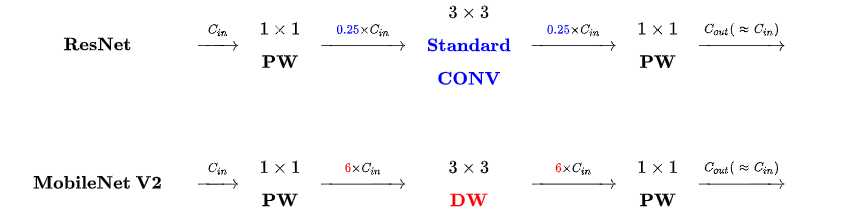
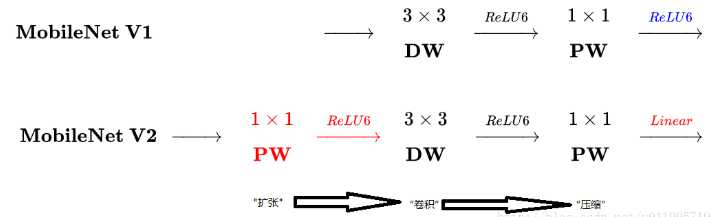
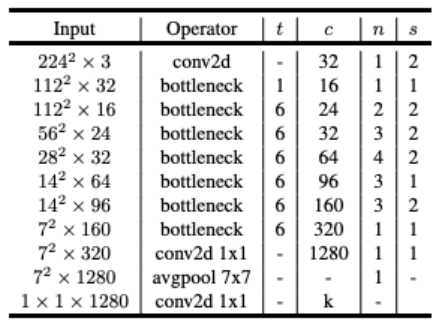
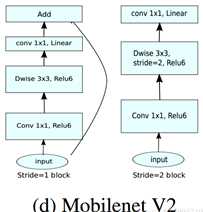
标签:卷积层 strong hub 执行 ISE 数据恢复 stride 一个 还原 论文题目:MobileNet V2:Inverted Residuals and Linear Bottlenecks 文献地址:https://arxiv.org/abs/1801.04381 (非官方)源码地址: (1)Caffe 实现:https://github.com/shicai/MobileNet-Caffe (2)Pytorch实现:https://github.com/tonylins/pytorch-mobilenet-v2 (3)TensorFlow实现:https://github.com/neuleaf/MobileNetV2 MobileNet V1中虽然提出了很有价值的Depthwise Convolution的卷积方式,极大程度上减少了参数量和计算量。但其网络结构却采用非常复古式的直筒结构,网络结构性价比不高。并且由于每一次卷积的维度都很小,卷积后的结果再经过ReLU激活函数,很容易获得0值,丧失有价值的信息。 因此,MobileNet V2 的版本中引入了两个改动:Inverted Residuals and Linear Bottlenecks 一方面,为模型添加了潮流的结构,(潮流的结构使用的是扩张-特征提取-压缩的方式,Inverted Residuals)由于卷积操作采用的DW操作,先对通道数量进行扩张并不会增加多少参数量和计算量。【输入和输出的通道数量均为低维度的张量】 另一方面,去掉了ReLU激活函数,使用线性的结构以防止该层毁灭一些有用的信息,以防止深度卷积训出来的卷积核不少为空的现象。 整理一下: MobileNet v2 依旧使用depthwise separable convolutions操作,但主体结构变为如下右图的形式: 主体结构的block包含了3个卷积层,最后两个卷积层是在MobileNet V1中提到的结构:一个DW (depthwise convolution),一个PW (pointwise convolution) 。然而,此时的1*1的PW操作与MobileNet稍有不同。 In V1 the pointwise convolution either kept the number of channels the same or doubled them. In V2 it does the opposite: it makes the number of channels smaller. 第一个卷积层是一个新增的层,其依旧是1*1卷积的PW操作。其主要目的是扩大通道数量。将通道数量扩大后的feature map 传递给DW进行depthwise convolutions。扩充数量通过扩张因子t决定。【扩张】 也就是说,其内部是一个 扩张-特征提取-压缩的过程。如下图可以看出网络结构详细的变化(扩张因子factor的作用): 从上图可以看出,通过这样的结构,输入和输出都是低维度的张量;在块内进行DW操作的是一个高维度的张量。由于此时的卷积操作是DW的操作,即使是高维度的张量,也不会增加多少参数和计算量。 另一方面, 增添了residual connection 的连接,为MobileNet V1中直筒的结构增添了ResNet作用的结构。 另外,除了projection convolution 层的输出结构没有激活函数ReLU6,其余的各层都会添加BN结构和ReLU6的结构。 Expansion layer充当解压器(如解压缩),它首先将数据恢复到其完整的形式,然后Depthwise layer执行在网络的这个阶段中任何重要的过滤,最后Projection layer压缩数据使其再次变小。 作者为什么要将DW操作的张量维度提升呢?这么做有什么用意呢? 当n = 2,3时(n为通道数量),与Input相比有很大一部分的信息已经丢失了。而当n = 15到30,还是有相当多的地方被保留了下来。也就是说,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。 从上图中可以看出,Inverted Residuals与Residual Net不同在于: 2. Linear Bottleneck: 为了解决MobileNet V1中,由于DW操作只针对一个通道,维度较低,feature map经ReLU激活后极易造成输出的值大多全为0,造成卷积核训练无效。 从上图中可以看出,MobileNet V1 版本和V2版本的区别,即在最终PW的输出后使用Linear代替了ReLU6的激活函数。(ReLU激活函数的非零部分实际上也就是线性激活函数) MobileNet 的网络结构(修改后的网络结构): 结构图源自:https://pytorch.org/hub/pytorch_vision_mobilenet_v2/ 针对stride=1 和stride=2,在block上有稍微不同,主要是为了与shortcut的维度匹配,因此,stride=2时,不采用shortcut。 具体如下图: 论文阅记 MobileNetV2:Inverted Residuals and Linear Bottlenecks 标签:卷积层 strong hub 执行 ISE 数据恢复 stride 一个 还原 原文地址:https://www.cnblogs.com/monologuesmw/p/12272010.htmlMobileNet V1优劣
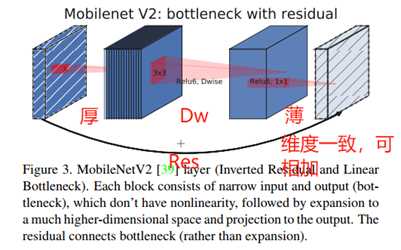
MobileNet V2思想与结构
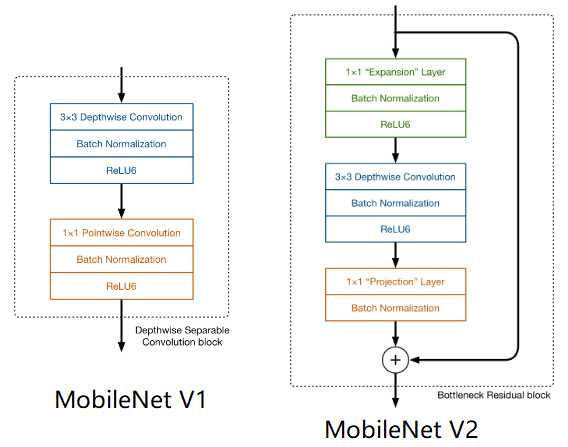
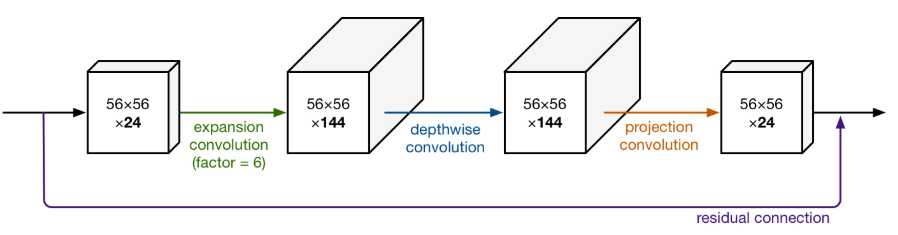
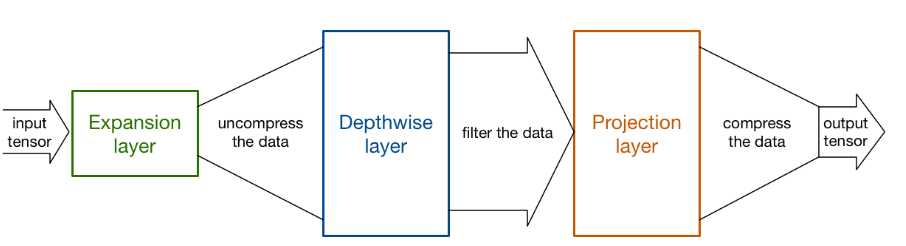


上一篇:AJAX---响应数据格式
文章标题:论文阅记 MobileNetV2:Inverted Residuals and Linear Bottlenecks
文章链接:http://soscw.com/index.php/essay/76448.html