Python实战案例:购物平台爬取商品评论
2021-04-20 12:30
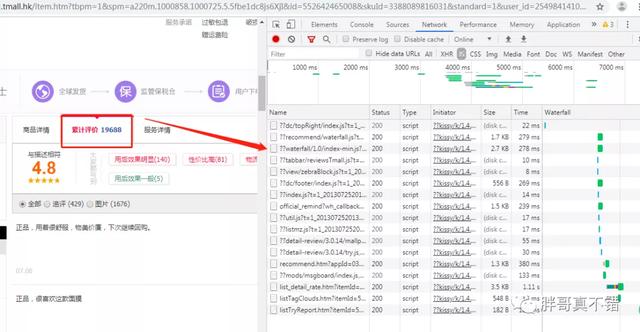
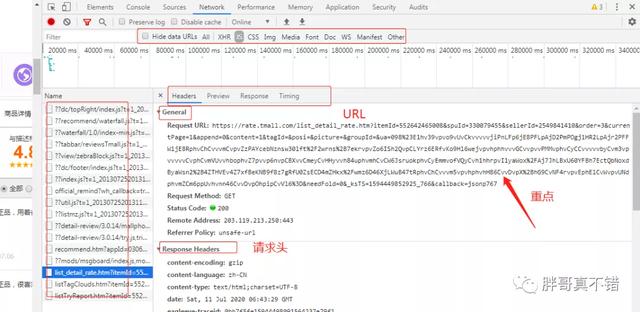
标签:rom safari tail false 相关 tps uid page lfw 前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 由于某种需要,需要爬取天猫国际一些商品的评论信息,然后做一些数据分析和可视化展示,本篇文章,只讲解如何从天猫上爬取评论信息,数据分析不作为本篇文章的重点。 第一步,整体说明一下数据采集的流程: 第二步,找到自己想要爬取的商品: 按F12,进行请求的分析: 点击"累计评价",在右侧,就会刷很多请求的信息,如果初次接触天猫国际爬取数据这块的话,可以多花费一些时间,研究一下这些请求: 找天猫评论链接的话,就是我上面截图中,Name列蓝色的内容,最重要的就是General里面的Request URL,后面我们主要是用这个URL的。另外,还需要COOKIE的,这里就不详细讲解cookies怎么获取了,大量自己玩的时候,直接用我代码里面的cookies就可以的,我是经过测试的,直接替换URL,然后进行爬就可以。 经过对URL分析之后: 第三步,代码说明: 部分关键代码。 这里是为了实现,爬取多页的评论的,最后把所有页的URL放到一个列表里面COMMENT_PAGE_URL。 这里就不多说了,就是循环进行爬取,然后写入到test.txt文本中,用于后续的数据分析。 Python实战案例:购物平台爬取商品评论 标签:rom safari tail false 相关 tps uid page lfw 原文地址:https://www.cnblogs.com/zwhy8/p/13285269.html

#生成链接列表
def Get_Url(num):
urlFront = ‘https://rate.tmall.com/list_detail_rate.htm?itemId=10905215461&spuId=273210686&sellerId=525910381&order=3¤tPage=‘
urlRear = ‘&append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hvHQvRvpQvUpCkvvvvvjiPRLqp0jlbn2q96jD2PmPWsjn2RL5wQjnhn2cysjnhR86CvC8h98KKXvvveSQDj60x0foAKqytvpvhvvCvp86Cvvyv9PPQt9vvHI4rvpvEvUmkIb%2BvvvRCiQhvCvvvpZptvpvhvvCvpUyCvvOCvhE20WAivpvUvvCC8n5y6J0tvpvIvvCvpvvvvvvvvhZLvvvvtQvvBBWvvUhvvvCHhQvvv7QvvhZLvvvCfvyCvhAC03yXjNpfVE%2BffCuYiLUpVE6Fp%2B0xhCeOjLEc6aZtn1mAVAdZaXTAdXQaWg03%2B2e3rABCCahZ%2Bu0OJooy%2Bb8reEyaUExreEKKD5HavphvC9vhphvvvvGCvvpvvPMM3QhvCvmvphmCvpvZzPQvcrfNznswOiaftlSwvnQ%2B7e9%3D&needFold=0&_ksTS=1552466697082_2019&callback=jsonp2020‘
for i in range(0,num):
COMMENT_PAGE_URL.append(urlFront+str(1+i)+urlRear)
#获取评论数据
def GetInfo(num):
#定义需要的字段
nickname = []
auctionSku = []
ratecontent = []
ratedate = []
#循环获取每一页评论
for i in range(num):
#头文件,没有头文件会返回错误的js
headers = {
‘cookie‘:‘cna=qMU/EQh0JGoCAW5QEUJ1/zZm; enc=DUb9Egln3%2Fi4NrDfzfMsGHcMim6HWdN%2Bb4ljtnJs6MOO3H3xZsVcAs0nFao0I2uau%2FbmB031ZJRvrul7DmICSw%3D%3D; lid=%E5%90%91%E6%97%A5%E8%91%B5%E7%9B%9B%E5%BC%80%E7%9A%84%E5%A4%8F%E5%A4%A9941020; otherx=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; hng=CN%7Czh-CN%7CCNY%7C156; x=__ll%3D-1%26_ato%3D0; t=2c579f9538646ca269e2128bced5672a; _m_h5_tk=86d64a702eea3035e5d5a6024012bd40_1551170172203; _m_h5_tk_enc=c10fd504aded0dc94f111b0e77781314; uc1=cookie16=V32FPkk%2FxXMk5UvIbNtImtMfJQ%3D%3D&cookie21=U%2BGCWk%2F7p4mBoUyS4E9C&cookie15=UtASsssmOIJ0bQ%3D%3D&existShop=false&pas=0&cookie14=UoTZ5bI3949Xhg%3D%3D&tag=8&lng=zh_CN; uc3=vt3=F8dByEzZ1MVSremcx%2BQ%3D&id2=UNcPuUTqrGd03w%3D%3D&nk2=F5RAQ19thpZO8A%3D%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D; tracknick=tb51552614; _l_g_=Ug%3D%3D; ck1=""; unb=3778730506; lgc=tb51552614; cookie1=UUBZRT7oNe6%2BVDtyYKPVM4xfPcfYgF87KLfWMNP70Sc%3D; login=true; cookie17=UNcPuUTqrGd03w%3D%3D; cookie2=1843a4afaaa91d93ab0ab37c3b769be9; _nk_=tb51552614; uss=""; csg=b1ecc171; skt=503cb41f4134d19c; _tb_token_=e13935353f76e; x5sec=7b22726174656d616e616765723b32223a22393031623565643538663331616465613937336130636238633935313935363043493362302b4d46454e76646c7243692b34364c54426f4d4d7a63334f44637a4d4455774e6a7378227d; l=bBIHrB-nvFBuM0pFBOCNVQhjb_QOSIRYjuSJco3Wi_5Bp1T1Zv7OlzBs4e96Vj5R_xYB4KzBhYe9-etui; isg=BDY2WCV-dvURoAZdBw3uwj0Oh2yUQwE5YzQQ9qAfIpm149Z9COfKoZwV-_8q0HKp‘,
‘user-agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘,
‘referer‘: ‘https://detail.tmall.com/item.htm?spm=a1z10.5-b-s.w4011-17205939323.51.30156440Aer569&id=41212119204&rn=06f66c024f3726f8520bb678398053d8&abbucket=19&on_comment=1&sku_properties=134942334:3226348‘,
‘accept‘: ‘*/*‘,
‘accept-encoding‘:‘gzip, deflate, br‘,
‘accept-language‘: ‘zh-CN,zh;q=0.9‘
}
#解析JS文件内容
content = requests.get(COMMENT_PAGE_URL[i],headers=headers).text
nk = re.findall(‘"displayUserNick":"(.*?)"‘, content)
nickname.extend(nk)
print(nk)
auctionSku.extend(re.findall(‘"auctionSku":"(.*?)"‘, content))
ratecontent.extend(re.findall(‘"rateContent":"(.*?)"‘, content))
ratedate.extend(re.findall(‘"rateDate":"(.*?)"‘, content))
#将数据写入TEXT文件中
for i in list(range(0, len(nickname))):
text = ‘,‘.join((nickname[i], ratedate[i], auctionSku[i], ratecontent[i])) + ‘\n‘
with open(r"test.txt", ‘a+‘,encoding=‘UTF-8‘) as file:
file.write(text + ‘ ‘)
print(i+1,":写入成功")
下一篇:HTML5,从零开始
文章标题:Python实战案例:购物平台爬取商品评论
文章链接:http://soscw.com/index.php/essay/77139.html