Lucene、Solr、ElasticSearch、hibernate-search四部曲
2021-04-22 04:27
标签:ber json 调用 必须 com http 根据 高效 通过 Lucene、Solr、ElasticSearch、hibernate-search四部曲 标签:ber json 调用 必须 com http 根据 高效 通过 原文地址:https://blog.51cto.com/13479739/2468679
从前年的时候,我都在心里有个想法。我想自己做一套搜索功能。在心里我是这么想的:
1、有个资源信息库,供我查询,这个资源库可能包含各种途径生成的统一格式的数据库。
2、查询时,我先整段匹配资源库找到资源。
3、接下来就是分词了,这里我联想到了一些输入法的细胞词库。也就是说能不能按照细胞词库先匹配我们的搜索内容,然后将分词后的搜索条件进行匹配查询。
4、按照匹配度的高低进行排序。
直到昨天,在工作中刚刚得知Lucene、Solr。
【简介】
Lucene是apache软件基金会(这个咱们前面介绍过)的一个子项目,是一个开源的全文检索引擎工具包,但不是一个完全的全文检索引擎,是一个全文检索引擎的架构,提供完整的查询引擎和索引引擎,部分文本分析引擎。
Solr是一个独立的企业及搜索应用服务器,用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引。也可以通过http get提出查找请求得到XML格式的返回结果。
【Lucene 和solr】
本质区别在于:
1、Lucene是搜索库,不是独立的应用程序,而Solr是。
2、Lucene专注于搜索底层的建设,而Solr专注企业应用。
3、Lucene不负责支撑搜索服务所必须的管理,而Solr负责。
也就是说:Solr是Lucene面向企业搜索的应用扩展。也就是说,像学好Solr先学Lucene。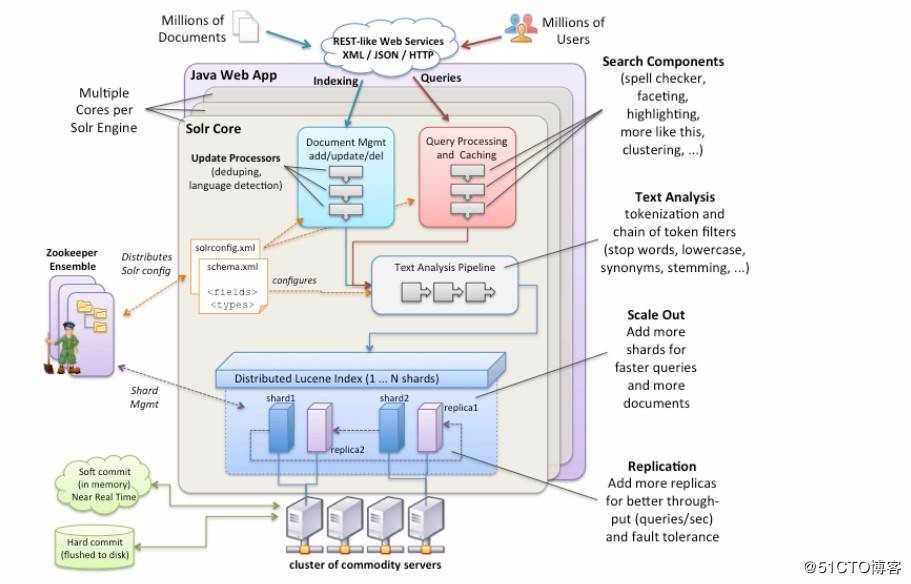
【问:什么是全文搜索引擎?】
答:全文搜索引擎是通过互联网提取的各个网站的信息,(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。
全文搜索引擎可分为两种:
1、拥有自己检索程序,俗称蜘蛛或机器人。这块在电子商务的课程中,会有所学习。在电子商务中,学习它的主要目的在于,如何高效的将产品的关键词描述清楚。好让自检程序抓取。这种搜索会自建数据库,将搜索结果直接从自身数据库中调用。
2、租用其他搜索引擎的数据库,按照自定的格式排列搜索结果。
【ElasticSearch(ES)和solr】
1、Solr利用Zookeeper进行分布式管理
2、ElasticSearch自身带有分布式协调管理功能
3、Solr支持多种格式
4、ElasticSearch只支持json格式
5、Solr功能好一点,elasticSearch搜索时效率高
6、Solr传统,ElasticSearch比较新。
【Hibernate Search】
Hibernate Search是在apache Lucene的基础上建立的主要用于Hibernate的持久化模型的全文检索工具。
像Lucene这样的检索引擎能够给我们的项目在进行检索的时候带来非常高的效率,但是它们在基本对象的检索时会有一些问题,比如不能实现检索内容跟实体的转换,Hibernate Search正是在这样的情况下发展起来的,基于对象的检索引擎,能够很方便的将检索出来的内容转换为具体的实体对象。此外Hibernate Search能够根据需要进行同步或异步的索引更新。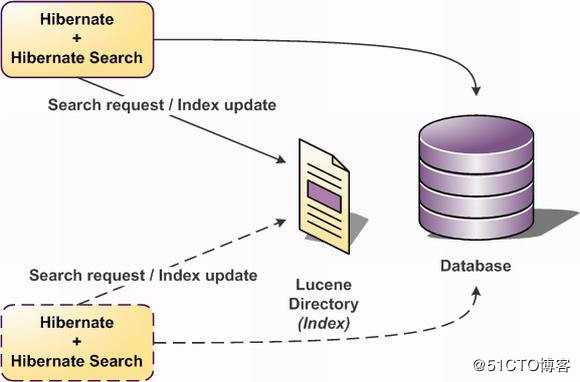
【Lucene】
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索。
Lucene是一套用于全文检索和搜索的开源程式库。
我觉得,就目前而言。应当先了解Lucene。
下一篇:jquery
文章标题:Lucene、Solr、ElasticSearch、hibernate-search四部曲
文章链接:http://soscw.com/index.php/essay/77911.html