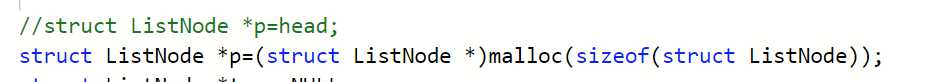83. 删除排序链表中的重复元素
2021-04-22 12:28
标签:变量 分析 == div 地址 存在 ret 修改 return 给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。 示例 1: 输入: 1->1->2 输入: 1->1->2->3->3 我写的错误代码: 报的错: 内存无法打印,可能是存在野指针的问题 修改后正确的代码: 主要问题分析: 头指针是表示当前链表信息的没有实际意义的节点,而首节点是链表中第一个含有实际意义的值 有一个问题就是什么时候需要声明节点,什么时候直接使用还是没搞清楚 把上面直接使用节点变成下面这句话的时候,就会报错,说明*p节点是不需要重新申请就可以直接使用的 这个错误需要搞清楚: 我的理解是这样的,*p是新申请的指针变量,他指向的是链表的头结点,所以无需新分配地址空间。 如果以后看的链表东西多了,目前的结论被推翻了,那就回来再修改一下 83. 删除排序链表中的重复元素 标签:变量 分析 == div 地址 存在 ret 修改 return 原文地址:https://www.cnblogs.com/redzzy/p/13276459.html
输出: 1->2
示例 2:
输出: 1->2->3/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
struct ListNode *p=(struct ListNode *)malloc(sizeof(struct ListNode));
head->next=p;
if(p->val==head->val)
{
head->next=p->next;
free(p);
head=head->next;
}
else{
head=head->next;
}
return head->next;
}

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
if(!head)
return NULL;
struct ListNode *p=head;
struct ListNode *temp=NULL;
while(p!=NULL&&p->next!=NULL)
{
if(p->val==p->next->val)
{
temp=p->next;
p->next=p->next->next;
free(temp);
}
else{
p=p->next;
}
}
return head;
}