C#爬虫系列(二)——食品安全国家标准数据检索平台
2021-04-22 17:37
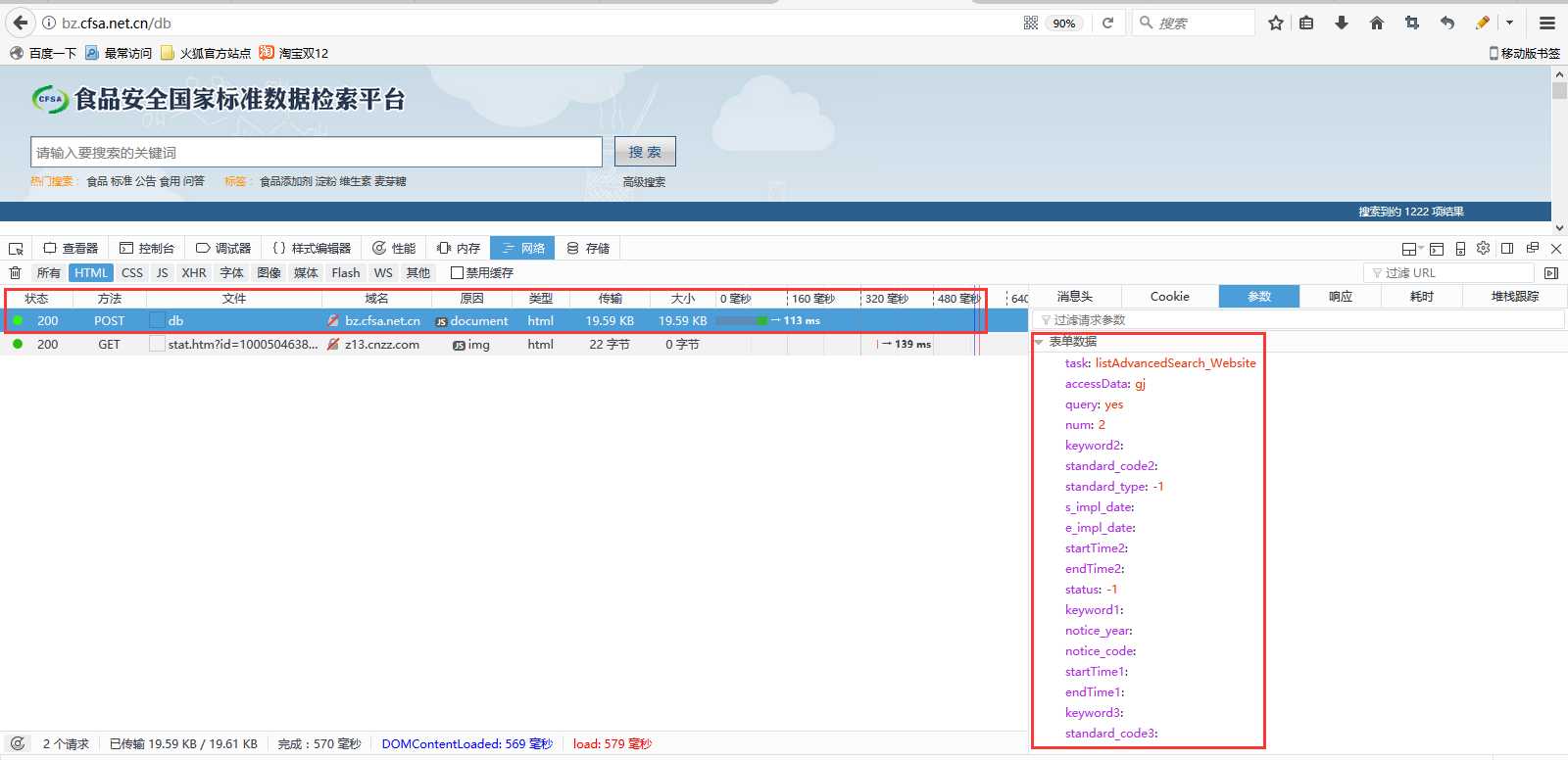
标签:simple writer 返回 def return single rar mes bin 上篇对“国家标准全文公开系统”的国标进行抓取,本篇对食品领域的标准公开系统“食品安全国家标准数据检索平台”进行抓取。 平台地址:http://bz.cfsa.net.cn/db 第一步还是去获取标准列表,通过高级搜索,输入空查询条件,则查询出全部的标准记录。 这时候可以看到,列表页的URL仍然是http://bz.cfsa.net.cn/db。 不同于“国家标准全文公开系统”,“食品安全国家标准数据检索平台”的请求多数是POST,即用户的多数操作是POST不同参数到http://bz.cfsa.net.cn/db,服务根据POST的参数返回相应的页面。 那么要获取标准列表,则要POST特定参数到http://bz.cfsa.net.cn/db。POST哪些参数?可以通过查看源码,分析JS代码了解到。 更简单、准确的方式是,通过浏览器(火狐、谷歌、IE都可)的Web调试工具查看其POST提交的参数,例如查询全部标准的POST数据如下: 点击标准名称超链接,将打开标准详细信息页,页面URL为http://bz.cfsa.net.cn/staticPages/002D3B53-DE13-42C1-B099-C57EC501138A.html。 可见详细信息页通过GET请求获得,需要从列表页中解析到标准的GUID,然后GET相应的页面即可。解析GUID仍然使用正则表达式即可。 当然,该站点也可以通过POST请求获取到标准详细信息页,因为其源代码如下: 标准详细信息的抓取,仍然通过HTML解析组件进行解析。 下载标准PDF文件,点击“下载”链接获取文件。查看其源代码如下: 可知下载PDF文件时,POST请求到该URL:http://bz.cfsa.net.cn/cfsa_aiguo。 文件的GUID值和标准的GUID值不同,但仍然可以从页面中使用正则表达式解析出来。 至此,该站点的标准可以抓取到,相比“国家标准全文公开系统”,该站点标准爬取时,只需要修改GET请求为POST请求即可。 C#爬虫系列(二)——食品安全国家标准数据检索平台 标签:simple writer 返回 def return single rar mes bin 原文地址:http://www.cnblogs.com/mahongbiao/p/8013012.html
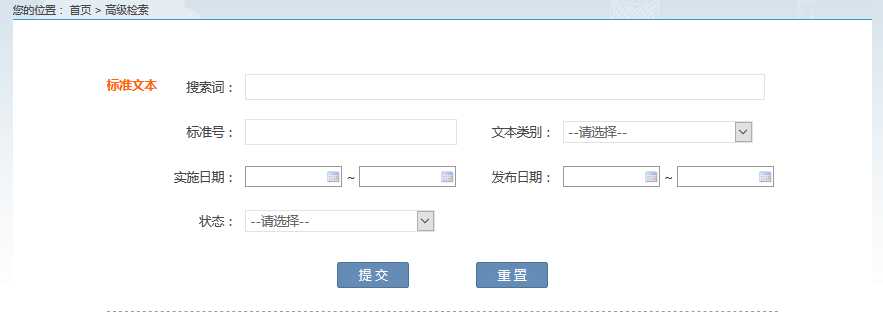
一、标准列表
二、标准详细信息
a href="javascript:void(0);" onclick="goto(‘3B34B8D6-7164-4419-B308-6AF683E8B606‘,‘2‘)">食品安全国家标准 食品微生物学检验培养基和试剂的质量font color=‘red‘>要font>求(GB 4789.28-2013)a>

三、标准文件下载
onclick="load(‘588072C8-F771-4F66-9B33-3BA4AF7C4540‘);

文章标题:C#爬虫系列(二)——食品安全国家标准数据检索平台
文章链接:http://soscw.com/index.php/essay/78179.html