Python数据分析实战之分布分析
2021-04-22 18:28
标签:memory tle 类型 数据有效性 frame 格式 目的 用户 文字 前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 作者:严小样儿 分布分析法,一般是根据分析目的,将数据进行分组,研究各组别分布规律的一种分析方法。数据分组方式有两种:等距或不等距分组。 分布分析在实际的数据分析实践中应用非常广泛,常见的有用户性别分布,用户年龄分布,用户消费分布等等。 本文将进行如下知识点讲解: 1.数据类型的修改 2.新字段生成方法 3.数据有效性校验 4.性别与年龄分布 分布分析 1.导入相关库包 2.数据处理
import pandas as pd
import matplotlib.pyplot as plt
import math>>> df = pd.read_csv(‘UserInfo.csv‘)
>>> df.info()
class ‘pandas.core.frame.DataFrame‘>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 4 columns):
UserId 1000000 non-null int64
CardId 1000000 non-null int64
LoginTime 1000000 non-null object
DeviceType 1000000 non-null object
dtypes: int64(2), object(2)
memory usage: 30.5+ MB
由于接下来我们需要做年龄分布分析,但是从源数据info()方法可知,并无年龄字段,需要自己生成。
# 查看年龄区间,进行分区
>>> df[‘Age‘].max(),df[‘Age‘].min()
# (45, 18)
>>> bins = [0,18,25,30,35,40,100]
>>> labels = [‘18岁及以下‘,‘19岁到25岁‘,‘26岁到30岁‘,‘31岁到35岁‘,‘36岁到40岁‘,‘41岁及以上‘]
>>> df[‘年龄分层‘] = pd.cut(df[‘Age‘],bins, labels = labels)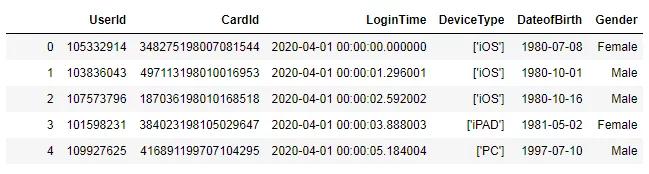
3.计算年龄
由于数据来源于线下,并未进行数据有效性验证,在进行年龄计算前,先针对数据进行识别,验证。
# 提取出生日期:月和日
>>> df[[‘month‘,‘day‘]] = df[‘DateofBirth‘].str.split(‘-‘,expand=True).loc[:,1:2]
# 提取小月,查看是否有31号
>>> df_small_month = df[df[‘month‘].isin([‘02‘,‘04‘,‘06‘,‘09‘,‘11‘])]
# 无效数据,如图所示
>>> df_small_month[df_small_month[‘day‘]==‘31‘]
# 统统删除,均为无效数据
>>> df.drop(df_small_month[df_small_month[‘day‘]==‘31‘].index,inplace=True)
# 同理,校验2月
>>> df_2 = df[df[‘month‘]==‘02‘]
# 2月份的校验大家可以做的仔细点儿,先判断是否润年再进行删减
>>> df_2[df_2[‘day‘].isin([‘29‘,‘30‘,‘31‘])]
# 统统删除
>>> df.drop(df_2[df_2[‘day‘].isin([‘29‘,‘30‘,‘31‘])].index,inplace=True)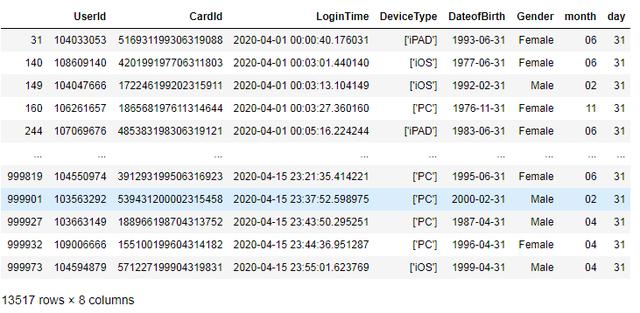
# 计算年龄
# 方法一
>>> df[‘Age‘] = df[‘DateofBirth‘].apply(lambda x : math.floor((pd.datetime.now() - pd.to_datetime(x)).days/365))
# 方法二
>>> df[‘DateofBirth‘].apply(lambda x : pd.datetime.now().year - pd.to_datetime(x).year)4.年龄分布
# 查看年龄区间,进行分区
>>> df[‘Age‘].max(),df[‘Age‘].min()
# (45, 18)
>>> bins = [0,18,25,30,35,40,100]
>>> labels = [‘18岁及以下‘,‘19岁到25岁‘,‘26岁到30岁‘,‘31岁到35岁‘,‘36岁到40岁‘,‘41岁及以上‘]
>>> df[‘年龄分层‘] = pd.cut(df[‘Age‘],bins, labels = labels)由于该数据记录的是用户登录信息,所以必定有重复数据。而Python如此强大,一个nunique()方法就可以进行去重统计了。
# 查看是否有重复值
>>> df.duplicated(‘UserId‘).sum() #47681
# 数据总条目
>>> df.count() #980954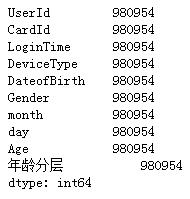
分组后用count()方法虽然也能够计算分布情况,但是仅限于无重复数据的情况。而Python这么无敌,提供了nunique()方法可用于计算含重复值的情况
>> df.groupby(‘年龄分层‘)[‘UserId‘].count()
年龄分层
18岁及以下 25262
19岁到25岁 254502
26岁到30岁 181751
31岁到35岁 181417
36岁到40岁 181589
41岁及以上 156433
Name: UserId, dtype: int64
# 通过求和,可知重复数据也被计算进去
>>> df.groupby(‘年龄分层‘)[‘UserId‘].count().sum()
# 980954
>>> df.groupby(‘年龄分层‘)[‘UserId‘].nunique()
年龄分层
18岁及以下 24014
19岁到25岁 242199
26岁到30岁 172832
31岁到35岁 172608
36岁到40岁 172804
41岁及以上 148816
Name: UserId, dtype: int64
>>> df.groupby(‘年龄分层‘)[‘UserId‘].nunique().sum()
# 933273 = 980954(总)-47681(重复)
# 计算年龄分布
>>> result = df.groupby(‘年龄分层‘)[‘UserId‘].nunique()/df.groupby(‘年龄分层‘)[‘UserId‘].nunique().sum()
>>> result
# 结果
年龄分层
18岁及以下 0.025731
19岁到25岁 0.259516
26岁到30岁 0.185189
31岁到35岁 0.184949
36岁到40岁 0.185159
41岁及以上 0.159456
Name: UserId, dtype: float64
# 格式化一下
>>> result = round(result,4)*100
>>> result.map("{:.2f}%".format)
年龄分层
18岁及以下 2.57%
19岁到25岁 25.95%
26岁到30岁 18.52%
31岁到35岁 18.49%
36岁到40岁 18.52%
41岁及以上 15.95%
Name: UserId, dtype: object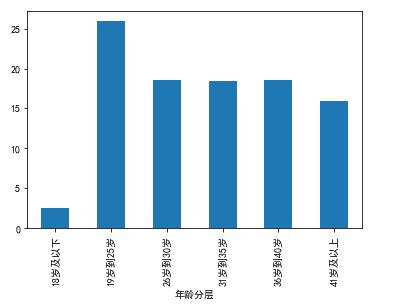
通过以上结果及分布图可以知道,19到25岁年龄段的用户占比最高,为26%。
Python数据分析实战之分布分析
标签:memory tle 类型 数据有效性 frame 格式 目的 用户 文字
原文地址:https://www.cnblogs.com/hhh188764/p/13276338.html