1 flume基础入门
2021-04-25 08:26
标签:生产环境 批量写入 操作 移除 安全 分组 日志采集 str 种类 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。 大数据框架大致分为3类: 数据的采集和传输:flume flume主要应用于数仓 数仓中,HDFS用来存储数据,HIVE用来对数据进行管理和计算(分层计算)。分析出结果然后给关系型数据库然后再做可视化等。 flume在项目中的基本架构: Flume最主要的作用就是:实时读取服务器本地磁盘的数据,将数据写入到HDFS。因此Flume就要部署到日志所在的那台节点上,或者说日志得发送到Flume所在的节点。即日志和Flume必须在一起才行。 flume基础架构如图所示: 如何选择相应的flume呢? Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。 Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。 其中: Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。 hdfs: 最基本最常用的就是hdfs sink, 将数据存储到hdfs上。 Channel 两个主要的作用:解耦和缓冲。 Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。 Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。 File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。 传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。 1 flume基础入门 标签:生产环境 批量写入 操作 移除 安全 分组 日志采集 str 种类 原文地址:https://www.cnblogs.com/zhqin/p/12230301.htmlflume
1.1 Flume定义
数据的存储:HDFS
数据的计算:MapReduce1.2 应用场景
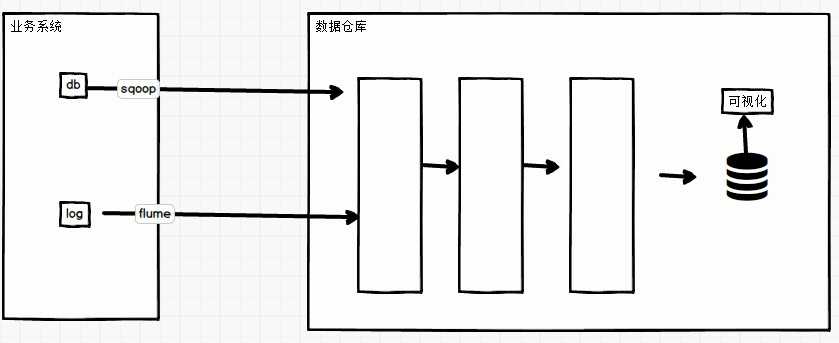
1.3 为什么选用flume
1.4 flume基础架构
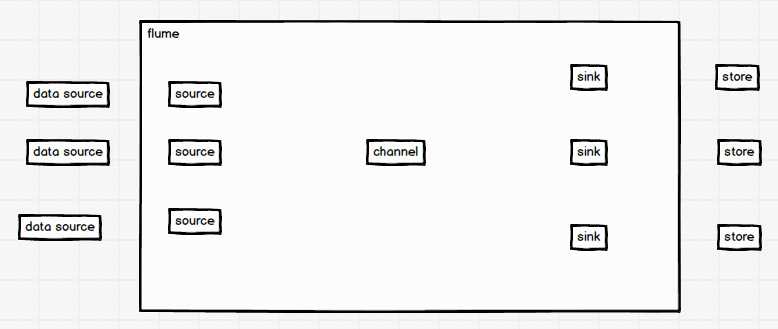
根据data source 和 store 来选择相应的source和sink
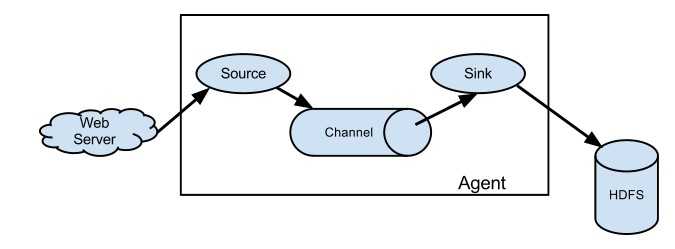
1.5 Flume架构中的组件:
1.5.1 Agent
Agent主要有3个部分组成,Source、Channel、Sink。1.5.2 Source
avro:(序列化框架)flume在搭建的时候可能会搭建多层,即涉及到flume的串联,avro主要用在两个flume之间,前一个flume的avro sink,后一个flume的avro source
exec: 主要用来监控一个文件,后面可以跟shell命令——tail -f 文件名 这样就可以监控这个文件了。生产环境中一般不用exec source。
spooling directory: 监控一个路径下的多个文件,
netcat: 用来监听网络端口,如果外界向机器的1234端口发送数据,通过netcat就可以监听到1234这个端口传进来的数据。1.5.3 Sink
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
logger: 一般用来做测试,将数据以日志的形式打印在控制台。
avro: 同avro source 进行对接,同样是涉及到flume的串联的时候使用。
file: 输出到本地文件。
hbase: 输出到HBase数据库。1.5.4 Channel
Flume自带两种Channel:Memory Channel和File Channel。
优点:速度块,延迟低,吞吐量高
缺点:可能会丢数据
优点:不会丢数据
缺点:速度没有memory channel快,延迟没有memory channel低,吞吐量低1.5.5 Event
Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
下一篇:2 安装部署flume