Python Faker的使用(1):基础使用方法与函数速查
2021-04-25 22:29
在软件需求、开发、测试过程中,有时候需要使用一些测试数据,针对这种情况,我们一般要么使用已有的系统数据,要么需要手动制造一些数据。
由于现在的业务系统数据多种多样,千变万化。在手动制造数据的过程中,可能需要花费大量精力和工作量,此项工作既繁复又容易出错,而且,部分数据的手造工作无法保障:比如UUID类数据、MD5、SHA加密类数据等。
现在好了,有一个Python包能够协助你完成这方面的工作。
1.什么是Faker
Faker是一个Python包,开源的GITHUB项目,主要用来创建伪数据,使用Faker包,无需再手动生成或者手写随机数来生成数据,只需要调用Faker提供的方法,即可完成数据的生成。
项目地址:https://github.com/joke2k/faker
2.安装Faker
方法一:
pip install faker
方法二:
通过上方提供的github地址,来下载编译安装。
3.Faker的使用
3.1、Faker命令
(该段落参考自:MA木易YA 的相关简书文章)
安装好了之后,可以在CMD或者Shell中通过faker命令来调试,具体如下:

参数说明:
faker:是安装在您的环境时,脚本,在发展中可以使用,而不是python -m faker
-h,--help:显示帮助消息 --version:显示程序的版本号 -o FILENAME:重定向输出到指定的文件名 -l {bg_BG,cs_CZ,...,zh_CN,zh_TW}:允许使用本地化的供应商 -r REPEAT:将生成的输出的特定数量的 -s SEP:将生成的每个产生的输出后的指定的分隔 -i {my.custom_provider other.custom_provider}:使用其他自定义供应商名单。请注意,是包含您提供一流的,而不是定制的Provider类本身包的导入路径。 fake:是产生一个输出,该假的名称,如 name,address或text [fake argument ...]:可选参数传递到假(例如,简档假取的逗号分隔的字段名作为第一个参数的可选列表)

3.2、在Python中使用
引用包:
from faker import Faker
初始化:
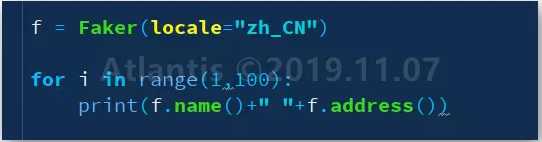
f=Faker(locale=‘zh_CN‘)
关于初始化参数locale:为生成数据的文化选项,默认为en_US,只有使用了相关文化,才能生成相对应的随机信息(比如:名字,地址,邮编,城市,省份等)
可选择的文化信息:
ar_EG - Arabic (Egypt) 阿拉伯语 - 埃及 ar_PS - Arabic (Palestine) 阿拉伯语 - 巴勒斯坦 ar_SA - Arabic (Saudi Arabia) 阿拉伯语 - 沙特阿拉伯 bg_BG - Bulgarian 保加利亚语 - 保加利亚 cs_CZ - Czech 捷克语 - 捷克 de_DE - German 德语 - 德国 dk_DK - Danish 丹麦语 - 丹麦 el_GR - Greek 希腊语 - 希腊 en_AU - English (Australia) 英语 - 澳大利亚 en_CA - English (Canada) 英语 - 加拿大 en_GB - English (Great Britain) 英语 - 英国 en_US - English (United States) 英语 - 美国 es_ES - Spanish (Spain) 西班牙语 - 西班牙 es_MX - Spanish (Mexico) 西班牙语- 墨西哥 et_EE - Estonian 爱沙尼亚语 - 爱沙尼亚 fa_IR - Persian (Iran) 波斯语 - 伊朗 fi_FI - Finnish 芬兰语 - 芬兰 fr_FR - French 法语 - 法国 hi_IN - Hindi 印地语 - 印度 hr_HR - Croatian 克罗地亚语 - 克罗地亚 hu_HU - Hungarian 匈牙利语 - 匈牙利 hy_AM - Armenian 亚美尼亚语 - 亚美尼亚 it_IT - Italian 意大利语 - 意大利 ja_JP - Japanese 日语 - 日本 ko_KR - Korean 朝鲜语 - 韩国 ka_GE - Georgian (Georgia) 格鲁吉亚语 - 格鲁吉亚 lt_LT - Lithuanian 立陶宛语 - 立陶宛 lv_LV - Latvian 拉脱维亚语 - 拉脱维亚 ne_NP - Nepali 尼泊尔语 - 尼泊尔 nl_NL - Dutch (Netherlands) 德语 - 荷兰 no_NO - Norwegian 挪威语 - 挪威 pl_PL - Polish 波兰语 - 波兰 pt_BR - Portuguese (Brazil) 葡萄牙语 - 巴西 pt_PT - Portuguese (Portugal) 葡萄牙语 - 葡萄牙 ru_RU - Russian 俄语 - 俄国 sl_SI - Slovene 斯诺文尼亚语 - 斯诺文尼亚 sv_SE - Swedish 瑞典语 - 瑞典 tr_TR - Turkish 土耳其语 - 土耳其 uk_UA - Ukrainian 乌克兰语 - 乌克兰 zh_CN - Chinese (China) (简体中文) zh_TW - Chinese (Taiwan) (繁体中文)
然后即可使用系统提供的方法:
f.name() #生成姓名
f.address() #生成地址
4.常用方法一览
以下内容以ZH-CN和ZH-TW包为准
4.1.地理信息类
city_suffix():市,县
country():国家
country_code():国家编码
district():区
geo_coordinate():地理坐标
latitude():地理坐标(纬度)
longitude():地理坐标(经度)
postcode():邮编
province():省份 (zh_TW没有此方法)
address():详细地址
street_address():街道地址
street_name():街道名
street_suffix():街、路
4.2、基础信息类
ssn():生成身份证号
bs():随机公司服务名
company():随机公司名(长)
company_prefix():随机公司名(短)
company_suffix():公司性质
credit_card_expire():随机信用卡到期日
credit_card_full():生成完整信用卡信息
credit_card_number():信用卡号
credit_card_provider():信用卡类型
credit_card_security_code():信用卡安全码
job():随机职位
first_name():
first_name_female():女性名
first_name_male():男性名
first_romanized_name():罗马名
last_name():
last_name_female():女姓
last_name_male():男姓
last_romanized_name():
name():随机生成全名
name_female():男性全名
name_male():女性全名
romanized_name():罗马名
msisdn():移动台国际用户识别码,即移动用户的ISDN号码
phone_number():随机生成手机号
phonenumber_prefix():随机生成手机号段
4.3、计算机基础、Internet信息类
4.3.1、个人账户信息类
ascii_company_email():随机ASCII公司邮箱名
ascii_email():随机ASCII邮箱
ascii_free_email():
ascii_safe_email():
company_email():
email():
free_email():
free_email_domain():
safe_email():安全邮箱
4.3.2、网络基础信息类
domain_name():生成域名
domain_word():域词(即,不包含后缀)
ipv4():随机IP4地址
ipv6():随机IP6地址
mac_address():随机MAC地址
tld():网址域名后缀(.com,.net.cn,等等,不包括.)
uri():随机URI地址
uri_extension():网址文件后缀
uri_page():网址文件(不包含后缀)
uri_path():网址文件路径(不包含文件名)
url():随机URL地址
user_name():随机用户名
image_url():随机URL地址
4.3.3、浏览器信息类
chrome():随机生成Chrome的浏览器user_agent信息
firefox():随机生成FireFox的浏览器user_agent信息
internet_explorer():随机生成IE的浏览器user_agent信息
opera():随机生成Opera的浏览器user_agent信息
safari():随机生成Safari的浏览器user_agent信息
linux_platform_token():随机Linux信息
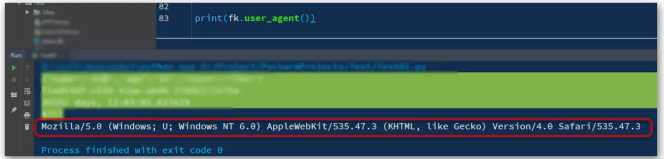
user_agent():随机user_agent信息
4.3.4、文件信息类
file_extension():随机文件扩展名
file_name():随机文件名(包含扩展名,不包含路径)
file_path():随机文件路径(包含文件名,扩展名)
mime_type():随机mime Type
4.4、数字类
numerify():三位随机数字 random_digit():0~9随机数 random_digit_not_null():1~9的随机数 random_int():随机数字,默认0~9999,可以通过设置min,max来设置 random_number():随机数字,参数digits设置生成的数字位数 pyfloat():left_digits=5 #生成的整数位数, right_digits=2 #生成的小数位数, positive=True #是否只有正数 pyint():随机Int数字(参考random_int()参数) pydecimal():随机Decimal数字(参考pyfloat参数)
4.5.文本、加密类
pystr():随机字符串 random_element():随机字母 random_letter():随机字母 paragraph():随机生成一个段落 paragraphs():随机生成多个段落,通过参数nb来控制段落数,返回数组 sentence():随机生成一句话 sentences():随机生成多句话,与段落类似 text():随机生成一篇文章(不要幻想着人工智能了,至今没完全看懂一句话是什么意思) word():随机生成词语 words():随机生成多个词语,用法与段落,句子,类似 binary():随机生成二进制编码 boolean():True/False language_code():随机生成两位语言编码 locale():随机生成语言/国际 信息 md5():随机生成MD5 null_boolean():NULL/True/False password():随机生成密码,可选参数:length:密码长度;special_chars:是否能使用特殊字符;digits:是否包含数字;upper_case:是否包含大写字母;lower_case:是否包含小写字母 sha1():随机SHA1 sha256():随机SHA256 uuid4():随机UUID
4.6.时间信息类
am_pm():AM/PM century():随机世纪 date():随机日期 date_between():随机生成指定范围内日期,参数:start_date,end_date取值:具体日期或者today,-30d,-30y类似 date_between_dates():随机生成指定范围内日期,用法同上 date_object():随机生产从1970-1-1到指定日期的随机日期。 date_this_month(): date_this_year(): date_time():随机生成指定时间(1970年1月1日至今) date_time_ad():生成公元1年到现在的随机时间 date_time_between():用法同dates future_date():未来日期 future_datetime():未来时间 month():随机月份 month_name():随机月份(英文) past_date():随机生成已经过去的日期 past_datetime():随机生成已经过去的时间 time():随机24小时时间 timedelta():随机获取时间差 time_object():随机24小时时间,time对象 time_series():随机TimeSeries对象 timezone():随机时区 unix_time():随机Unix时间 year():随机年份
4.7、集合信息类
profile():随机生成档案信息
simple_profile():随机生成简单档案信息
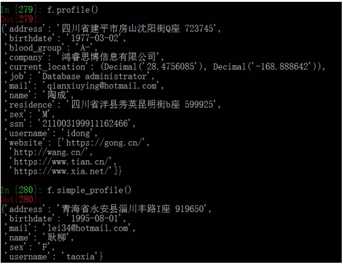
#以下方法皆为随机集合类型 pyiterable() pylist() pyset() pystruct() pytuple() pydict()
4.8、其他类别
currency_code():货币编码
color_name():随机颜色名
hex_color():随机HEX颜色
rgb_color():随机RGB颜色
safe_color_name():随机安全色名
safe_hex_color():随机安全HEX颜色
isbn10():随机ISBN(10位)
isbn13():随机ISBN(13位)
lexify():替换所有问号(“?”)带有随机字母的事件。
5.使用中遇到的问题
元旦前发布的这篇文章,由于工作需要,元旦期间创建伪数据的过程中,发现一个很有意思的问题。不同的文化类之间,方法是偶然有区别的。
比如,在中文(zh_CN)中的方法,district()#获取区 province()#获取省的方法,在有些包里是没有的,这需要根据所使用文化类的国家特制来。
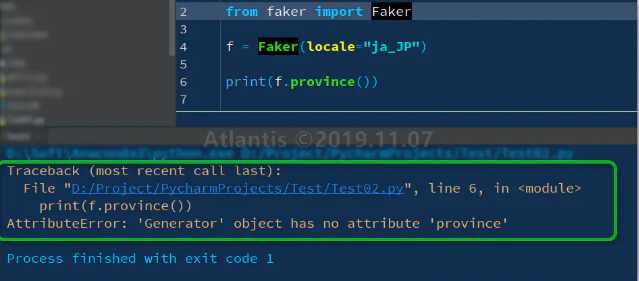
比如,中国的一级行政单位,是省,直辖市,自治区;而日本的一级行政单位,是都、道、府、县。所以,日文包(ja_JP)中,就没有相应的province(),district(),取而代之的是prefecture(),town();在美国,一级行政单位又是洲,所以,在美国英语包(en_US)中,取而代之的是state();
总之,在使用不同Fake类之前,最好对所生成文化的国家、地区信息做初步的了解,建议先浏览其对应的类文件的成员
文章标题:Python Faker的使用(1):基础使用方法与函数速查
文章链接:http://soscw.com/index.php/essay/79553.html