Python | 面试必问,线程与进程的区别,Python中如何创建多线程?
2021-04-26 01:29
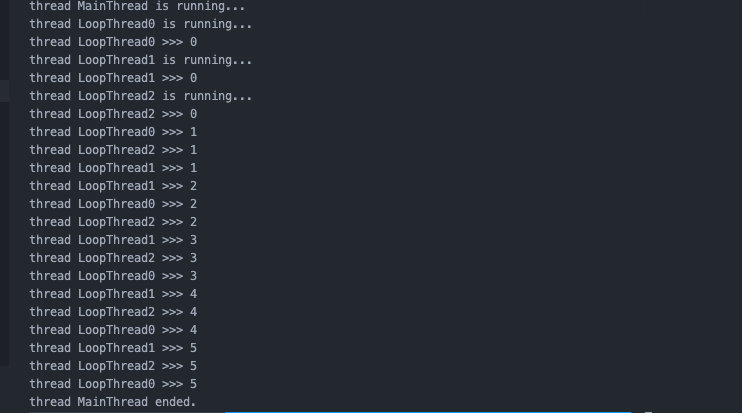
今天是Python专题第20篇文章,我们来聊聊Python当中的多线程。 其实关于元类还有很多种用法,比如说如何在元类当中设置参数啦,以及一些规约的用法等等。只不过这些用法比较小众,使用频率非常低,所以我们不过多阐述了,可以在用到的时候再去详细了解。我想只要大家理解了元类的原理以及使用方法,再去学习那些具体的用法应该会很容易。所以我们今天开始了一个新的话题——多线程和并发。 为了照顾小白,我们来简单聊聊进程和线程这两个概念。这两个概念属于操作系统,我们经常听说,但是可能很少有人会细究它们的含义。对于工程师而言,两者的定义和区别还是很有必要了解清楚的。 首先说进程,进程可以看成是CPU执行的具体的任务。在操作系统当中,由于CPU的运行速度非常快,要比计算机当中的其他设备要快得多。比如内存、磁盘等等,所以如果CPU一次只执行一个任务,那么会导致CPU大量时间在等待这些设备,这样操作效率很低。为了提升计算机的运行效率,把机器的技能尽可能压榨出来,CPU是轮询工作的。也就是说它一次只执行一个任务,执行一小段碎片时间之后立即切换,去执行其他任务。 所以在早期的单核机器的时候,看起来电脑也是并发工作的。我们可以一边听歌一边上网,也不会觉得卡顿。但实际上,这是CPU轮询的结果。在这个例子当中,听歌的软件和上网的软件对于CPU而言都是独立的进程。我们可以把进程简单地理解成运行的应用,比如在安卓手机里面,一个app启动的时候就会对应系统中的一个进程。当然这种说法不完全准确,一个应用也是可以启动多个进程的。 进程是对应CPU而言的,线程则更多针对的是程序。即使是CPU在执行当前进程的时候,程序运行的任务其实也是有分工的。举个例子,比如听歌软件当中,我们需要显示歌词的字幕,需要播放声音,需要监听用户的行为,比如是否发生了切歌、调节音量等等。所以,我们需要进一步拆分CPU的工作,让它在执行当前进程的时候,继续通过轮询的方式来同时做多件事情。 进程中的任务就是线程,所以从这点上来说,进程和线程是包含关系。一个进程当中可以包含多个线程,对于CPU而言,不能直接执行线程,一个线程一定属于一个进程。所以我们知道,CPU进程切换切换的是执行的应用程序或者是软件,而进程内部的线程切换,切换的是软件当中具体的执行任务。 关于进程和线程有一个经典的模型可以说明它们之间的关系,假设CPU是一家工厂,工厂当中有多个车间。不同的车间对应不同的生产任务,有的车间生产汽车轮胎,有的车间生产汽车骨架。但是工厂的电力是有限的,同时只能满足一个厂房的使用。 为了让大家的进度协调,所以工厂个需要轮流提供各个车间的供电。这里的车间对应的就是进程。 一个车间虽然只生产一种产品,但是其中的工序却不止一个。一个车间可能会有好几条流水线,具体的生产任务其实是流水线完成的,每一条流水线对应一个具体执行的任务。但是同样的,车间同一时刻也只能执行一条流水线,所以我们需要车间在这些流水线之间切换供电,让各个流水线生产进度统一。 这里车间里的流水线自然对应的就是线程的概念,这个模型很好地诠释了CPU、进程和线程之间的关系。实际的原理也的确如此,不过CPU中的情况要比现实中的车间复杂得多。因为对于进程和CPU来说,它们面临的局面都是实时变化的。车间当中的流水线是x个,下一刻可能就成了y个。 了解完了线程和进程的概念之后,对于理解电脑的配置也有帮助。比如我们买电脑,经常会碰到一个术语,就是这个电脑的CPU是某某核某某线程的。比如我当年买的第一台笔记本是4核8线程的,这其实是在说这台电脑的CPU有4个计算核心,但是使用了超线程技术,使得可以把一个物理核心模拟成两个逻辑核心。相当于我们可以用4个核心同时执行8个线程,相当于8个核心同时执行,但其实有4个核心是模拟出来的虚拟核心。 有一个问题是为什么是4核8线程而不是4核8进程呢?因为CPU并不会直接执行进程,而是执行的是进程当中的某一个线程。就好像车间并不能直接生产零件,只有流水线才能生产零件。车间负责的更多是资源的调配,所以教科书里有一句非常经典的话来诠释:进程是资源分配的最小单元,线程是CPU调度的最小单元。 Python当中为我们提供了完善的threading库,通过它,我们可以非常方便地创建线程来执行多线程。 首先,我们引入threading中的Thread,这是一个线程的类,我们可以通过创建一个线程的实例来执行多线程。 简单解释一下它的用法,我们传入了三个参数,分别是target,name和args,从名字上我们就可以猜测出它们的含义。首先是target,它传入的是一个方法,也就是我们希望多线程执行的方法。name是我们为这个新创建的线程起的名字,这个参数可以省略,如果省略的话,系统会为它起一个系统名。当我们执行Python的时候启动的线程名叫MainThread,通过线程的名字我们可以做区分。args是会传递给target这个函数的参数。 我们来举个经典的例子: 我们创建了一个非常简单的loop函数,用来执行一个循环来打印数字,我们每次打印一个数字之后这个线程会睡眠5秒钟,所以我们看到的结果应该是每过5秒钟屏幕上多出一行数字。 我们在Jupyter里执行一下: 表面上看这个结果没毛病,但是其实有一个问题,什么问题呢?输出的顺序不太对,为什么我们在打印了第一个数字0之后,主线程就结束了呢?另外一个问题是,既然主线程已经结束了,为什么Python进程没有结束, 还在向外打印结果呢? 因为线程之间是独立的,对于主线程而言,它在执行了t.start()之后,并不会停留,而是会一直往下执行一直到结束。如果我们不希望主线程在这个时候结束,而是阻塞等待子线程运行结束之后再继续运行,我们可以在代码当中加上t.join()这一行来实现这点。 join操作可以让主线程在join处挂起等待,直到子线程执行结束之后,再继续往下执行。我们加上了join之后的运行结果是这样的: 这个就是我们预期的样子了,等待子线程执行结束之后再继续。 我们再来看第二个问题,为什么主线程结束的时候,子线程还在继续运行,Python进程没有退出呢?这是因为默认情况下我们创建的都是用户级线程,对于进程而言,会等待所有用户级线程执行结束之后才退出。这里就有了一个问题,那假如我们创建了一个线程尝试从一个接口当中获取数据,由于接口一直没有返回,当前进程岂不是会永远等待下去? 这显然是不合理的,所以为了解决这个问题,我们可以把创建出来的线程设置成守护线程。 守护线程即daemon线程,它的英文直译其实是后台驻留程序,所以我们也可以理解成后台线程,这样更方便理解。daemon线程和用户线程级别不同,进程不会主动等待daemon线程的执行,当所有用户级线程执行结束之后即会退出。进程退出时会kill掉所有守护线程。 我们传入daemon=True参数来将创建出来的线程设置成后台线程: 这样我们再执行看到的结果就是这样了: 这里有一点需要注意,如果你在jupyter当中运行是看不到这样的结果的。因为jupyter自身是一个进程,对于jupyter当中的cell而言,它一直是有用户级线程存活的,所以进程不会退出。所以想要看到这样的效果,只能通过命令行执行Python文件。 如果我们想要等待这个子线程结束,就必须通过join方法。另外,为了预防子线程锁死一直无法退出的情况, 我们还可以在joih当中设置timeout,即最长等待时间,当等待时间到达之后,将不再等待。 比如我在join当中设置的timeout等于5时,屏幕上就只会输出5个数字。 另外,如果没有设置成后台线程的话,设置timeout虽然也有用,但是进程仍然会等待所有子线程结束。所以屏幕上的输出结果会是这样的: 虽然主线程继续往下执行并且结束了,但是子线程仍然一直运行,直到子线程也运行结束。 关于join设置timeout这里有一个坑,如果我们只有一个线程要等待还好,如果有多个线程,我们用一个循环将它们设置等待的话。那么主线程一共会等待N * timeout的时间,这里的N是线程的数量。因为每个线程计算是否超时的开始时间是上一个线程超时结束的时间,它会等待所有线程都超时,才会一起终止它们。 比如我这样创建3个线程: 最后屏幕上输出的结果是这样的: 所有线程都存活了6秒,不得不说,这个设计有点坑,和我们预想的完全不一样。 在今天的文章当中,我们一起简单了解了操作系统当中线程和进程的概念,以及Python当中如何创建一个线程,以及关于创建线程之后的相关使用。今天介绍的只是最基础的使用和概念,关于线程还有很多高端的用法,我们将在后续的文章当中和大家分享。 多线程在许多语言当中都是至关重要的,许多场景下必定会使用到多线程。比如web后端,比如爬虫,再比如游戏开发以及其他所有需要涉及开发ui界面的领域。因为凡是涉及到ui,必然会需要一个线程单独渲染页面,另外的线程负责准备数据和执行逻辑。因此,多线程是专业程序员绕不开的一个话题,也是一定要掌握的内容之一。 今天的文章就到这里,如果喜欢本文,可以的话,请点个关注,给我一点鼓励,也方便获取更多文章。 本文使用 mdnice 排版
进程和线程


启动线程
from threading import Thread
t = Thread(target=func, name=‘therad‘, args=(x, y))
t.start()
import time, threading
# 新线程执行的代码:
def loop(n):
print(‘thread %s is running...‘ % threading.current_thread().name)
for i in range(n):
print(‘thread %s >>> %s‘ % (threading.current_thread().name, i))
time.sleep(5)
print(‘thread %s ended.‘ % threading.current_thread().name)
print(‘thread %s is running...‘ % threading.current_thread().name)
t = threading.Thread(target=loop, name=‘LoopThread‘, args=(10, ))
t.start()
print(‘thread %s ended.‘ % threading.current_thread().name)
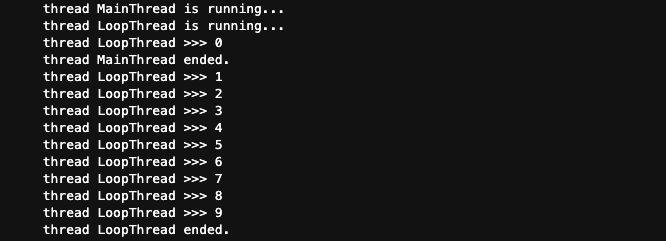
t.start()
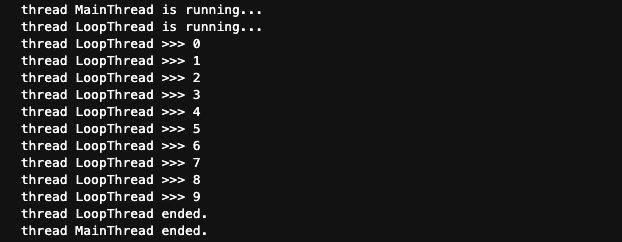
t.join()
print(‘thread %s ended.‘ % threading.current_thread().name)
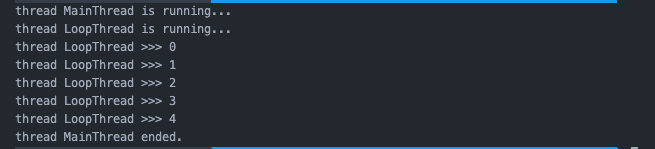
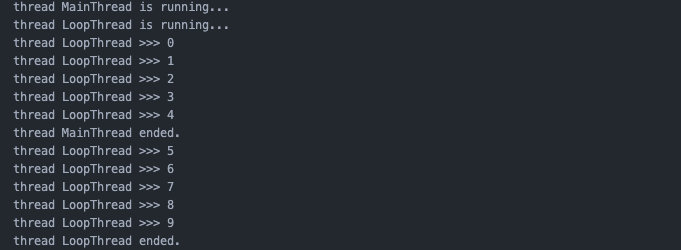
守护线程
t = threading.Thread(target=loop, name=‘LoopThread‘, args=(10, ), daemon=True)

ths = []
for i in range(3):
t = threading.Thread(target=loop, name=‘LoopThread‘ + str(i), args=(10, ), daemon=True)
ths.append(t)
for t in ths:
t.start()
for t in ths:
t.join(2)
总结
文章标题:Python | 面试必问,线程与进程的区别,Python中如何创建多线程?
文章链接:http://soscw.com/index.php/essay/79612.html