Java容器
2021-04-30 13:30
标签:写入 迭代器 java 长度 的区别 int ble loading 数组 Java容器 标签:写入 迭代器 java 长度 的区别 int ble loading 数组 原文地址:https://www.cnblogs.com/yzhengy/p/13226886.htmlJava容器
容器主要包括Collection和Map两种,Collection存储着对象的集合,而Map存储着键值对(两个对象)的映射表。
Java中常用的线程安全的集合类有Vector、Hashtable、ConcurrentHashMap、Stack
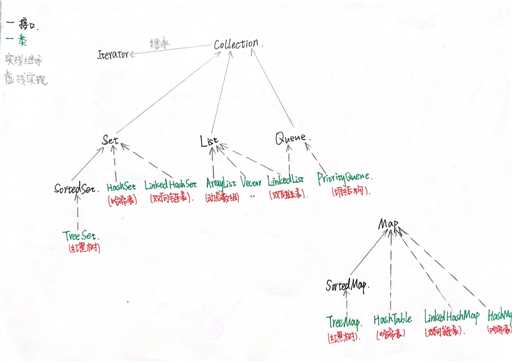
Set
--TreeSet(有序):基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如HashSet,HashSet查找的时间复杂度为O(1),TreeSet则为O(logN)。
--HashSet(无序):基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用Iterator 遍历HashSet得到的结果是不确定的。
--LinkedHashSet:具有HashSet的查找效率,且内部使用双向链表维护元素的插入顺序。
List
--ArrayList:基于动态数组实现,支持随机访问。(扩容1.5倍)
--Vector:和 ArrayList 类似,但它是线程安全的。底层用Synchronize实现线程安全。(扩容2倍)
--LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
Queue
--LinkedList:可以用它来实现双向队列。
--PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
--TreeMap(有序):基于红黑树实现。
--HashMap(无序):由数组+链表+红黑树实现。
--HashTable:和HashMap类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入HashTable并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用ConcurrentHashMap来支持线程安全,并且ConcurrentHashMap的效率会更高,因为ConcurrentHashMap引入了分段锁。
--LinkedHashMap:继承自HashMap,底层仍是由数组和链表或红黑树组成。使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
List、Set、Map的区别
--List:存储的元素是有序的、可重复的。
--Set:存储的元素是无序的、不可重复的。
--Map:使用键值对(kye-value)存储,Key是无序、不可重复的,value是无序、可重复的,每个键最多映射到一个值。
迭代器
Iterator对象称为迭代器(设计模式的一种),迭代器可以对集合进行遍历,但每一个集合内部的数据结构可能是不尽相同的,所以每一个集合存和取都很可能是不一样的,虽然我们可以人为地在每一个类中定义 hasNext() 和 next() 方法,但这样做会让整个集合体系过于臃肿。于是就有了迭代器。
迭代器是将这样的方法抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做就规定了整个集合体系的遍历方式都是 hasNext()和next()方法,使用者不用管怎么实现的,会用即可。
迭代器的定义为:提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节。
Iterator主要是用来遍历集合用的,它的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException异常。
线程不安全的集合
我们常用的Arraylist,LinkedList,Hashmap,HashSet,TreeSet,LinkedHashSet,TreeMap,PriorityQueue都不是线程安全的。解决办法很简单,可以使用线程安全的集合来代替。
如果你要使用线程安全的集合的话, java.util.concurrent 包中提供了很多并发容器供你使用:
--ConcurrentHashMap: 可以看作是线程安全的HashMap。
--CopyOnWriteArrayList:可以看作是线程安全的ArrayList,在读多写少的场合性能非常好,远远好于Vector.
--ConcurrentLinkedQueue:高效的并发队列,使用链表实现。可以看做一个线程安全的 LinkedList,这是一个非阻塞队列。
--BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
--ConcurrentSkipListMap :跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
ArrayList源码
--ArrayList 是基于数组实现的,所以支持快速随机访问。
--数组的默认大小为 10。
--添加元素时使用ensureCapacityInternal()方法来保证容量足够,如果不够时,需要使用grow()方法进行扩容,新
容量的大小为oldCapacity+(oldCapacity >> 1) ,也就是旧容量的1.5倍。
--删除元素需要调用System.arraycopy()将index+1后面的元素都复制到index位置上,该操作的时间复杂度为 O(N)。
--Fail-Fast:modCount用来记录ArrayList结构发生变化的次数。在进行序列化或者迭代等操作时,需要比较操作前后 modCount是否改变,如果改变了需要抛出ConcurrentModificationException。
CopyOnWriteArrayList
读写分离,但会导致内存占用和数据不一致
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失。
写操作结束之后需要把原始数组指向新的复制数组。
HashMap
1、HashMap自Java1.8起,采用数组+链表+红黑树的数据结构
Java1.8以前,采用数组+链表的结构
2、HashMap初始容量为什么是2的n次幂 以及 扩容为什么是2倍的形式
HashMap计算添加元素的位置时,使用的位运算,这是特别高效的运算;另外,HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成链表的结构,使得查询效率降低!
hash = hashCode();
取模运算:hash % 16 = {0 - 15};
位运算:h & (length - 1);
如果要想位运算约等于取模运算,那length必须是2的n次幂。
3、Java7的链表插入,采用头插法。(头插法会造成死锁)
Java8的链表插入,采用尾插法。
4、HashMap的加载因子为什么是0.75
加载因子过高的话,例如1,则查询的时间复杂度增加。
而加载因子过低的话,例如0.5,空间利用率也会降低。
所以为了均衡时间和空间,采用0.75f
5、链表的长度为8时,就马上转红黑树吗
当数组长度小于64时,优先扩容,当大于等于64时,才会转红黑树。
链表转红黑树,阈值等于8,但是链表的实际长度是9。
6、什么是哈希冲突,如何解决?
哈希函数处理后,存在不同的数据对应相同的哈希值,产生哈希冲突。
解决方法:开放地址法、链地址法、再哈希法、建立一个公共溢出区。
7、HashMap底层为什么使用红黑树不用AVL树?
--红黑树牺牲了一些查找性能 但其本身并不是完全平衡的二叉树。因此插入删除操作效率略高于AVL树
--AVL树用于自平衡的计算牺牲了插入删除性能,但是因为最多只有一层的高度差,查询效率会高一些。
--在CurrentHashMap中是加锁了的,实际上是读写锁,如果写冲突就会等待,如果插入时间过长必然等待时间更长,而红黑树相对AVL树他的插入更快!
ConcurrentHashMap
--ConcurrentHashMap和HashMap实现上类似,最主要的差别是ConcurrentHashMap采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是Segment的个数)。
Segment继承自ReentrantLock。
--默认的并发级别为 16,也就是说默认创建 16 个 Segment。
--每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
--JDK1.7使用分段锁机制来实现并发更新操作,核心类为Segment,它继承自重入锁ReentrantLock,并发度与Segment数量相等。JDK1.8使用了CAS操作来支持更高的并发度,在CAS操作失败时使用内置锁synchronized。并且JDK 1.8的实现也在链表过长时会转换为红黑树。
上一篇:python--运算符,字符编码