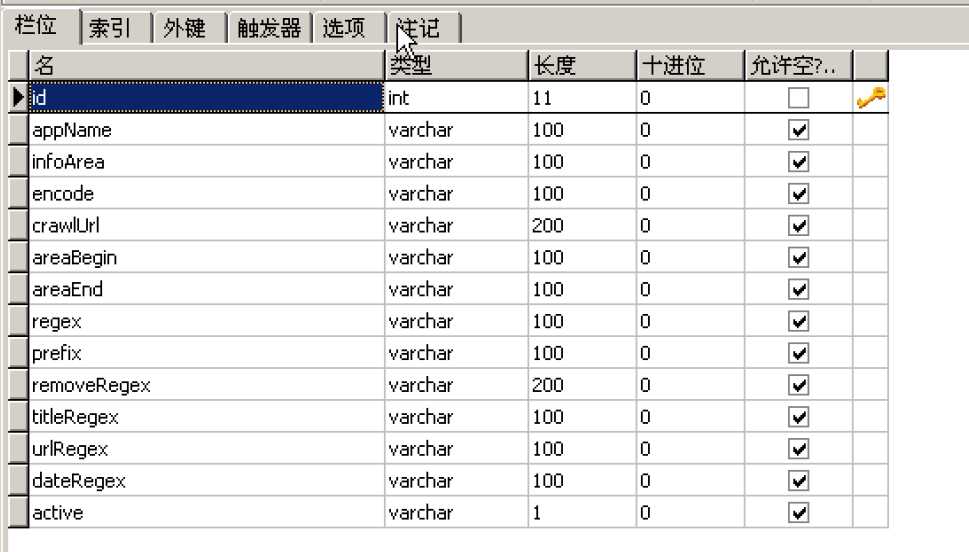
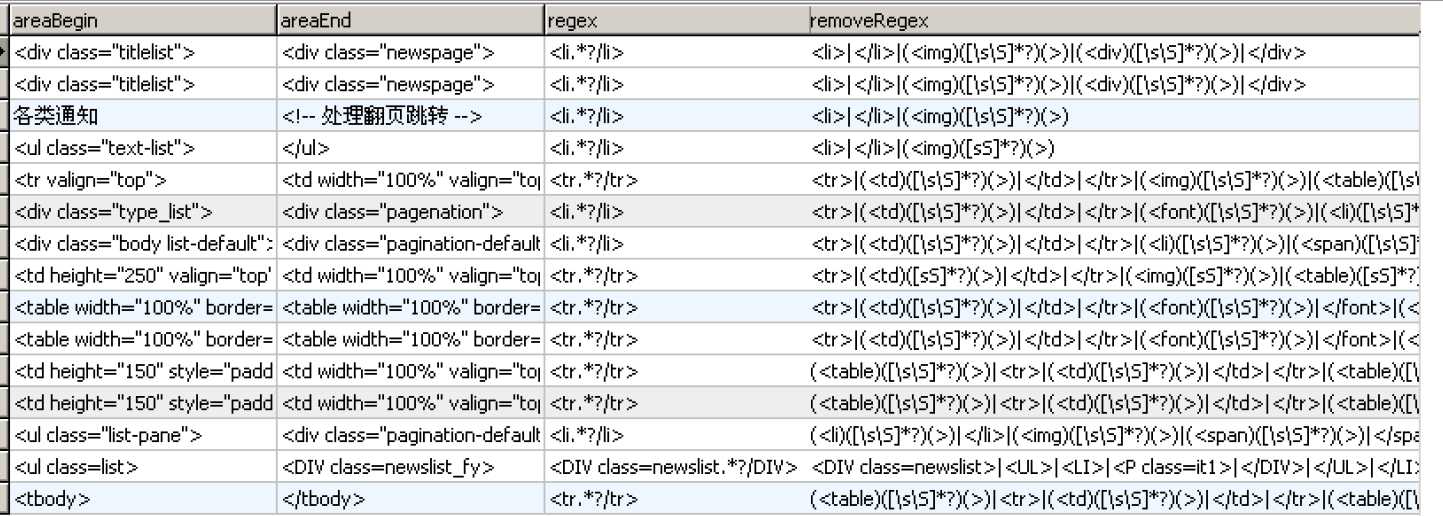
private static void doCrawl(RuleBean rb) {
String urlContent = getUrlContent(rb.getCrawlUrl(),rb.getEncode());
if("error".equalsIgnoreCase(urlContent)){
return;
}
String contentArea = getContentArea(urlContent, rb.getAreaBegin(),
rb.getAreaEnd());
Pattern pt = Pattern.compile(rb.getRegex());
Matcher mt = pt.matcher(contentArea);
TitleAndUrlBean tuBean;
while (mt.find()) {
tuBean = new TitleAndUrlBean();
tuBean.setAppName(rb.getAppName());
tuBean.setInfoArea(rb.getInfoArea());
String rowContent = mt.group();
rowContent = rowContent.replaceAll(rb.getRemoveRegex(), "");
// 获取标题
Matcher title = Pattern.compile(rb.getTitleRegex()).matcher(
rowContent);
while (title.find()) {
String s = title.group().replaceAll("||>||\\[.*?\\]|","");
if(s ==null || s.trim().length()
s = "error";
}
tuBean.setTitle(s);
}
// 获取网址
Matcher myurl = Pattern.compile(rb.getUrlRegex()).matcher(
rowContent);
while (myurl.find()) {
String u = myurl.group().replaceAll(
"href=|\"|>|target=|_blank|title", "");
u = u.replaceAll("\‘|\\\\", "");
if(u!=null && (u.indexOf("http://")==-1)){
tuBean.setUrl(rb.getPrefix() + u);
}else{
tuBean.setUrl(u);
}
}
if(tuBean.getUrl() ==null){
tuBean.setUrl("error");
}
// 获取时间
Matcher d = Pattern.compile(rb.getDateRegex()).matcher(rowContent);
while (d.find()) {
tuBean.setDeliveryDate(d.group());
}
boolean r = TitleAndUrlDAO.Add(tuBean);
if (r){
log.info("crawl add " + tuBean.getAppName() + "_"
+ tuBean.getInfoArea()+"_"+tuBean.getTitle());
if(tuBean.getAppName().contains("jww")){
Cache cTeach = CacheManager.getCacheInfo("index_teach");
if(cTeach!=null){
teachList = (List) cTeach.getValue();
}
teachList.add(tuBean);
if(teachList.size()>5){
teachList.remove(0);
}
cTeach.setValue(teachList);
cTeach.setTimeOut(-1);
CacheManager.putCache("index_teach", cTeach);
}
}
}
System.out.println("end crawl "+rb.getCrawlUrl());
}
(2) dwr返回内容的抽取
在当时dwr是比较流行的技术,为了抽取dwr的内容,着实花了一番功夫。
首先通过httpClient获取内容
public static void startCrawl() throws Exception{
DefaultHttpClient httpclient = new DefaultHttpClient();
HttpResponse response = null;
HttpEntity entity = null;
httpclient.getParams().setParameter(ClientPNames.COOKIE_POLICY,
CookiePolicy.BROWSER_COMPATIBILITY);
HttpPost httpost = new HttpPost(
"http://XXXXXXXXXX/Tzgg.getMhggllList.dwr");
List nvps = new ArrayList();
nvps.add(new BasicNameValuePair("callCount", "1"));
nvps.add(new BasicNameValuePair("page", "/oa/tzggbmh.do"));
nvps.add(new BasicNameValuePair("c0-scriptName", "Tzgg"));
nvps.add(new BasicNameValuePair("c0-methodName", "getMhggllList"));
nvps.add(new BasicNameValuePair("c0-id", "0"));
nvps.add(new BasicNameValuePair("c0-e1", "string:0"));
nvps.add(new BasicNameValuePair("c0-e2", "string:0"));
nvps.add(new BasicNameValuePair("c0-e4", "string:%20%20"));
nvps.add(new BasicNameValuePair("c0-e5", "string:rsTable"));
nvps.add(new BasicNameValuePair(
"c0-param0",
"Array:[reference:c0-e1,reference:c0-e2,reference:c0-e3,reference:c0-e4,reference:c0-e5]"));
nvps.add(new BasicNameValuePair("c0-e6", "number:20"));
nvps.add(new BasicNameValuePair("c0-e7", "number:1"));
nvps.add(new BasicNameValuePair("c0-param1",
"Object_Object:{pageSize:reference:c0-e6, currentPage:reference:c0-e7}"));
nvps.add(new BasicNameValuePair("batchId", "0"));
int infoArea = 1;
while(infoArea
nvps.add(new BasicNameValuePair("c0-e3", "string:0"+infoArea));
httpost.setEntity(new UrlEncodedFormEntity(nvps));
response = httpclient.execute(httpost);
entity = response.getEntity();
try {
String responseString = null;
if (response.getEntity() != null) {
responseString = EntityUtils.toString(response.getEntity());
if(1 == infoArea){
extractData(responseString,"事务通知");
infoArea = 3;
}else if(infoArea == 3){
extractData(responseString,"公告公示");
infoArea = 100;
}
}
} finally {
}
}
httpclient.getConnectionManager().shutdown();
}
然后通过正则表达式抽取
private static void extractData(String content,String infoArea) throws Exception{
TitleAndUrlDAO tuDao = new TitleAndUrlDAO();
TitleAndUrlBean tuBean;
Pattern pt = Pattern.compile("llcs.*?a>");
Matcher mt = pt.matcher(content);
Cache c = new Cache();
while (mt.find()) {
tuBean = new TitleAndUrlBean();
tuBean.setAppName("info_xb");
tuBean.setInfoArea(infoArea);
String s2 = mt.group();
// 获取标题
Matcher title = Pattern.compile("title.*?>").matcher(s2);
while (title.find()) {
String s = title.group().replaceAll("title=|>", "");
tuBean.setTitle(unicodeToString(s));
}
// 获取网址
// Matcher myurl = Pattern.compile("href=.*?>").matcher(mt.group());
Matcher myurl = Pattern.compile("ID=.*?;").matcher(s2);
while (myurl.find()) {
String prefix = "http://XXXXXXXXX/tzggbmh.do?theAction=view¶meter.id=";
tuBean.setUrl(prefix + myurl.group().replaceAll("ID=|;|\"", ""));
}
// 获取时间
Matcher d = Pattern.compile("[0-9]{4}-[0-9]{2}-[0-9]{1,2}")
.matcher(s2);
while (d.find()) {
tuBean.setDeliveryDate(d.group());
}
boolean r = tuDao.Add(tuBean);
if (r){
log.info("crawl add " + tuBean.getAppName() + "_"
+ tuBean.getInfoArea()+"_"+tuBean.getTitle());
Cache cNotice = CacheManager.getCacheInfo("index_notice");
if(cNotice!=null){
xb_noticeList = (List) cNotice.getValue();
}
xb_noticeList.add(tuBean);
if(xb_noticeList.size()>5){
xb_noticeList.remove(0);
}
c.setValue(xb_noticeList);
c.setTimeOut(-1);
CacheManager.putCache("index_notice", c);
}
}
}