request-html 简单爬虫与案列
2021-05-01 17:27
标签:with click final 推荐 fir question 元素 exp tab
https://www.cnblogs.com/ruhai/p/11318499.html
requests-html模块
官方网站
Github网址
请求数据
from requests_html import HTMLSession
session = HTMLSession()
requests-html发出的请求是由session发出来的
发送Get请求
url = ‘https://baidu.com‘
res= session.get(url = url)发送post请求
url = ‘https://baidu.com‘
res= session.post(url = url)
也可以使用request方法,指定GET,或者是POST参数来指定,这个使用方法就和使用requests中的session方法类封装的
url = ‘http://ww.baidu.com‘
res = session.request(method = ‘GET‘,url = url)
print(res.html.html)get方法和post还有request的方法和requests的模块中的方法一致,至于为什么,因为这两个模块是一个人写的
自定义HTML对象
from requests_html import HTML
doc = """"""
html = HTML(html=doc)
print(html.links)
{‘https://httpbin.org‘}
HTML对象属性
url = ‘https://www.zhihu.com/signin?next=%2F‘
res = session.get(url = url)在ipython中检查res类型
In [15]: res
Out[15]: 200]> In [16]: type(res)
Out[16]: requests_html.HTMLResponseIn [17]: res.html
Out[17]: ‘https://www.zhihu.com/signin?next=%2F‘>
In [18]: type(res.html)
Out[18]: requests_html.HTML可以看到requests_html.HTML 和requests_html.HTMLResponse 模块自己实现的类
In [19]: dir(res.html)
Out[20]:
[‘absolute_links‘, ‘add_next_symbol‘, ‘arender‘, ‘base_url‘, ‘default_encoding‘, ‘element‘, ‘encoding‘, ‘find‘, ‘full_text‘, ‘html‘, ‘links‘, ‘lxml‘, ‘next‘, ‘next_symbol‘, ‘page‘, ‘pq‘, ‘raw_html‘, ‘render‘, ‘search‘, ‘search_all‘, ‘session‘, ‘skip_anchors‘, ‘text‘, ‘url‘, ‘xpath]除去掉模块内部封装的属性和方法之外有这么多的方法和属性,下面我们一步一步类进行介绍。
html对象属性
absolute_links
输入页面中的绝对路径,如果页内连接是相对路径也会被自动转换为绝对路径
url = ‘https://www.zhihu.com/signin?next=%2F‘
res = session.get(url = url)
这里我们请求知乎首页,可以底部检查网址,
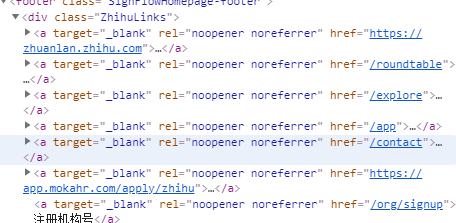
In:res.html.absolute_links
Out:
{
‘https://www.zhihu.com/app‘,
‘https://www.zhihu.com/contact‘,
‘https://www.zhihu.com/explore‘,
‘https://www.zhihu.com/jubao‘,
‘https://www.zhihu.com/org/signup‘,
‘https://www.zhihu.com/question/waiting‘,
}相对路径被转换为绝对路径
links
原样连接,页面中是绝对路径的输出就是绝对路径,是相对路径输出就是相对路径
In : res.html.links
Out:
{
‘/app‘,
‘/contact‘,
‘/explore‘,
‘/jubao‘,
‘https://www.zhihu.com/org/signup‘,
‘https://www.zhihu.com/term/privacy‘,
‘https://www.zhihu.com/terms‘,
‘}base_url
? 基础连接
html
返回响应页面的html代码
raw_html
返回页面的二进制流
text
输入响应中所有的文字,结果如下,
In [21]: res.html.text
Out[21]: ‘知乎 - 有问题,上知乎\n.u-safeAreaInset-top { height: constant(safe-area-inset-top) !important; height: env(safe-
area-inset-top) !important; } .u-safeAreaInset-bottom { height: constant(safe-area-inset-bottom) !important; height: env(safe-area-inset-bottom) !important; }\nif (window.requestAnimationFrame) { window.requestAnimationFrame(function() { window.FIRST_ANIMATION_FRAME = Date.now(); }); }\n首页\n发现\n等你来答\n登录加入知乎\n有问题,上知乎\n免密码登录\n密码登录\n获取短
信验证码\n接收语音验证码\n注册/登录\n未注册手机验证后自动登录\n注册即代表同意《知乎协议》《隐私保护指引》\n注册机构号\n社交
帐号登录\n微信\nQQ\nQQ\n微博\n下载知乎 App\n知乎专栏圆桌发现移动应用联系我们来知乎工作注册机构号\n? 2019 知乎京 ICP 证 1107
45 号京公网安备 11010802010035 号出版物经营许可证\n侵权举报网上有害信息举报专区儿童色情信息举报专区违法和不良信息举报:010-
82716601\nencoding
字符编码
可以通过以下方法设置字符编码
res.html.encoding = ‘gbk‘html对象方法
find
参数:
:param selector: css 选择器
:param clean: 是否去除页面中的scpript>和style>标签,默认False
:param containing:如果指定有值,只返回包含所给文本的Element对象,默认False
:param first: 是否返回第一个对象,默认False
:param _encoding: 字符编码返回结果
[Element,Element……]
当First为True的时候,只返回第一个Elementxpath
:param selector: xpath 选择器
其他和find方法一致search
res.html.search(xxx{}yyy)[0] // 只搜索一次
res.html.search(xxx{name}yyy{pwd}zzz)[name] // 只搜索一次
search_all
查找所有符合template对象,返回结果是result对象组成的list
Element对象
‘absolute_links‘, ‘attrs‘, ‘base_url‘, ‘default_encoding‘, ‘element‘, ‘encoding‘, ‘find‘, ‘full_text‘, ‘html‘, ‘lineno‘, ‘links‘, ‘lxml‘, ‘pq‘, ‘raw_html‘, ‘search‘, ‘search_all‘, ‘session‘, ‘skip_anchors‘, ‘tag‘, ‘text‘, ‘url‘, ‘xpath‘text
去掉\r\n之后的文本
full_text
没有去掉\r\n之后的文本值
attrs
返回以字典的形式Element对象的属性和属性名,
render方法
我们先理一下关系requests和的作者是同一个人,pyppeteer是nodejs中puppeteer的非官方实现
requests-html调用的pyppeteer与浏览器进行交互,
puppeteer的中文文档 点这里传送
pyppeteer的文档 博文参考
调用render 方法启动pyppeteer
使用之前要先下载chromium 下载地址
你懂的,天朝网络环境很复杂,如果要用pyppeteer自己绑定的chromium,半天都下载不下来,所以我们要手动安装,然后在程序里面指定executablePath
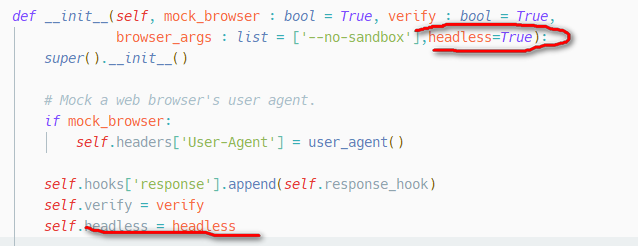
对于requests-html源代码在714行中加入
executablePath=’path/to/the/chromium‘ from requests_html import HTMLSession
url = ‘https://httpbin.org/get‘
session = HTMLSession()
res = session.get(url = url)
res.html.render()
print(res.html.html)
可以看到如上图中我用红色的圈出来的地方,标示的是无头浏览器HeadlessChrome,这个是明显不是正常的人类用户,会被反扒网站所识别
url = ‘https://httpbin.org/get‘
session = HTMLSession(
browser.args = [
‘--no-sand‘,
‘--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"‘
])
res = session.get(url = url)
res.html.render()
print(res.html.html)在正常使用的浏览器的控制台中键入navigator.userAgent就可以看到浏览器的请求头把他复制到--user-agent之后,注意千万不能有空格,--nosand 是以最高权限运行
启动参数
kwargs = {
‘headless‘: False,
‘devtools‘: False, // 打开开发者工具
‘ignoreDefaultArgs‘: // 忽略默认配置
‘userDataDir‘ :‘./userdata‘, //设置用户目录,保存cookie
‘args‘: [
‘--disable-extensions‘,
‘--window-size={width},{height}‘,
‘--hide-scrollbars‘,
‘--disable-bundled-ppapi-flash‘,
‘--mute-audio‘, //页面静音
‘--no-sandbox‘,
‘--disable-setuid-sandbox‘,
‘--disable-gpu‘,
‘--enable-automation‘,
],
‘dumpio‘: True,
}请求网站可以看到我们进行设置的UA头生效了
render 方法的参数
- retries 重试次数,默认为8,
- script,JS 脚本,可选参数,默认为None,
str类型,如果有值,返回JS执行脚本的返回值 - wait 加载页面前等待的秒数,防止超时,默认0.2秒,可选参数,浮点型
- scrolldown,页面滚动次数,整数,默认为0,
- sleep, 首次渲染之后暂停的秒数,接收整数,可选类型,默认为0
- reload 默认为
True,如果为False,如果为False,就会从内存中加载内容 - keep_page,默认为
False,如果为True,就可以通过r.html.page和页面进行交互
"""Reloads the response in Chromium, and replaces HTML content
with an updated version, with JavaScript executed.
:param retries: The number of times to retry loading the page in Chromium.
:param script: JavaScript to execute upon page load (optional).
:param wait: The number of seconds to wait before loading the page, preventing timeouts (optional).
:param scrolldown: Integer, if provided, of how many times to page down.
:param sleep: Integer, if provided, of how many long to sleep after initial render.
:param reload: If ``False``, content will not be loaded from the browser, but will be provided from memory.
:param keep_page: If ``True`` will allow you to interact with the browser page through ``r.html.page``.如果sleep和scrolldown一起用,表示翻一夜,停几秒
JS注入实例1
script = """
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""from requests_html import HTMLSession
url = ‘https://httpbin.org/get‘
session = HTMLSession(
browser_args=[
‘--no-sand‘,
‘--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"‘
]
)
res = session.get(url = url)
r = res.html.render(script=script)
print(r)输出结果为
{‘width‘: 800, ‘height‘: 600, ‘deviceScaleFactor‘: 1}JS 注入实例2 更改navigator.webdriver
‘‘‘() =>{
Object.defineProperties(navigator,{
webdriver:{
get: () => undefined
}
})
}‘‘‘scrolldown
这个我们先改一下源码

与浏览器进行交互
page.screenshot([options])
- options ` 可选配置
- path `` 截图保存路径。截图图片类型将从文件扩展名推断出来。如果是相对路径,则从当前路径解析。如果没有指定路径,图片将不会保存到硬盘。
- type `` 指定截图类型, 可以是 jpeg 或者 png。默认 ‘png‘.
- quality `` 图片质量, 可选值 0-100. png 类型不适用。
- fullPage 如果设置为true,则对完整的页面(需要滚动的部分也包含在内)。默认是false
- clip ` 指定裁剪区域。需要配置:
- x `` 裁剪区域相对于左上角(0, 0)的x坐标
- y `` 裁剪区域相对于左上角(0, 0)的y坐标
- width `` 裁剪的宽度
- height `` 裁剪的高度
- omitBackground 隐藏默认的白色背景,背景透明。默认不透明
- encoding `` 图像的编码可以是 base64 或 binary。 默认为“二进制”。
截图实例
import asyncio
from requests_html import HTMLSession
url = ‘https://httpbin.org/get‘
session = HTMLSession(
browser_args=[
‘--no-sand‘,
‘--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"‘
]
)
res = session.get(url = url)
script = """
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""
try:
res.html.render(script=script,sleep = 1,keep_page = True)
async def main():
await res.html.page.screenshot({‘path‘:‘1.png‘}) # 传入参数用字典path 代表路径 值为你要存放的路径
asyncio.get_event_loop().run_until_complete(main())
finally:
session.close()# 指定截图位置,截图从哪个坐标开始
screenshot({‘path‘:‘1.png‘,‘clip‘:‘{‘x‘:200,‘y‘:‘300‘,‘weith‘:400,‘height‘:‘600‘}‘})
page.evaluate(pageFunction[, ...args])
- pageFunction
要在页面实例上下文中执行的方法
js1 = ‘‘‘() =>{
Object.defineProperties(navigator,{
webdriver:{
get: () => undefined
}
})
}‘‘‘
js4 = ‘‘‘() =>{Object.defineProperty(navigator, ‘languages‘, {get: () => [‘en-US‘, ‘en‘]});
}‘‘‘
await page.evaluate(js1) ## 更改webdriver
await page.evaluate(js4) ##更改语言
page.setViewport()
设置页面大小
page.setViewport({‘width‘: 1366, ‘height‘: 768})page.cookies()
如果不指定任何 url,此方法返回当前页面域名的 cookie。 如果指定了 url,只返回指定的 url 下的 cookie。
page.type(selector, text[, options])
- selector `` 要输入内容的元素选择器。如果有多个匹配的元素,输入到第一个匹配的元素。
- text `` 要输入的内容
- options `
- delay `` 每个字符输入的延迟,单位是毫秒。默认是 0。 page.click(selector[, options])
- selector `string>` 要点击的元素的选择器。 如果有多个匹配的元素, 点击第一个。
- options `object>`
- button `string>` left, right, 或者 middle, 默认是 left。
- clickCount `number>` 默认是 1. 查看 UIEvent.detail。
- delay `number>` mousedown 和 mouseup 之间停留的时间,单位是毫秒。默认是0page.focus(selector)
- selector
page.hover(selector)
- selector
page.waitFor(selectorOrFunctionOrTimeout[, options[, ...args]])
- selectorOrFunctionOrTimeout string|number|function> 选择器, 方法 或者 超时时间
- options `object>` 可选的等待参数
...args ...Serializable|JSHandle> 传给 pageFunction 的参数- 如果
selectorOrFunctionOrTimeout是string, 那么认为是 css 选择器或者一个xpath, 根据是不是‘//‘开头, 这时候此方法是 page.waitForSelector 或 page.waitForXPath的简写 - 如果
selectorOrFunctionOrTimeout是function, 那么认为是一个predicate,这时候此方法是page.waitForFunction()的简写 - 如果
selectorOrFunctionOrTimeout是number, 那么认为是超时时间,单位是毫秒,返回的是Promise对象,在指定时间后resolve - 否则会报错
page.emulate
模拟手机
await page.emulate(iPhone);键盘事件
详细的键盘键名语法
语法:
res.html.page.keyboard.XXX
keyboard.down(key[, options])
- key
- options
- text
keyboard.up(key)
- key
keyboard.press(key[, options])
- key
- options
- text
keyboard.type(text, options)
- text
-
options
- delaypage.keyboardtype(‘喜欢你啊‘,{‘delay’:100})鼠标事件
r.html.page.mouse.XXX
mouse.click(x, y, [options])
- x
- y
- options
- button
- clickCount
- delay
mouse.down([options])
- options
- button
- clickCount
mouse.up([options])
- options
- button
- clickCount
项目代码
puppeteer项目参考 传送门
模拟登陆Gmail
import asyncio
import time
from pyppeteer import launch
async def gmailLogin(username, password, url):
#‘headless‘: False如果想要浏览器隐藏更改False为True
# 127.0.0.1:1080为代理ip和端口,这个根据自己的本地代理进行更改,如果是vps里或者全局模式可以删除掉‘--proxy-server=127.0.0.1:1080‘
browser = await launch({‘headless‘: False, ‘args‘: [‘--no-sandbox‘, ‘--proxy-server=127.0.0.1:1080‘]})
page = await browser.newPage()
await page.setUserAgent(
‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36‘)
await page.goto(url)
# 输入Gmail
await page.type(‘#identifierId‘, username)
# 点击下一步
await page.click(‘#identifierNext > content‘)
page.mouse # 模拟真实点击
time.sleep(10)
# 输入password
await page.type(‘#password input‘, password)
# 点击下一步
await page.click(‘#passwordNext > content > span‘)
page.mouse # 模拟真实点击
time.sleep(10)
# 点击安全检测页面的DONE
# await page.click(‘div > content > span‘)#如果本机之前登录过,并且page.setUserAgent设置为之前登录成功的浏览器user-agent了,
# 就不会出现安全检测页面,这里如果有需要的自己根据需求进行更改,但是还是推荐先用常用浏览器登录成功后再用python程序进行登录。
# 登录成功截图
await page.screenshot({‘path‘: ‘./gmail-login.png‘, ‘quality‘: 100, ‘fullPage‘: True})
#打开谷歌全家桶跳转,以Youtube为例
await page.goto(‘https://www.youtube.com‘)
time.sleep(10)
if __name__ == ‘__main__‘:
username = ‘你的gmail包含@gmail.com‘
password = r‘你的gmail密码‘
url = ‘https://gmail.com‘
loop = asyncio.get_event_loop()
loop.run_until_complete(gmailLogin(username, password, url))
# 代码由三分醉编写,网址www.sanfenzui.com,参考如下文章:
# https://blog.csdn.net/Chen_chong__/article/details/82950968实现淘宝登陆
puppeteer模拟手机
scrpay使用pyppetter
import asyncio
from requests_html import HTMLSession
url = ‘http://www.xiaohuar.com/hua/‘
session = HTMLSession( browser_args=[
‘--no-sand‘,
‘--disable-infobars‘
‘--user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36‘
],headless=False)
res = session.request(url=url,method=‘GET‘)
script = """
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""
try:
res.html.render(keep_page = True)
async def main():
await res.html.page.waitFor(1000)
await res.html.page.setViewport({‘width‘: 1366, ‘height‘: 768})
url_list = await res.html.page.xpath(‘//div[@class="img"]/a‘)
for url in url_list:
url_link = await (await url.getProperty(‘href‘)).jsonValue()
print(url_link)
asyncio.get_event_loop().run_until_complete(main())
except Exception as e:
print(e)
finally:
session.close()
import asyncio
from requests_html import HTMLSession
url = ‘https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F&sms=5‘
session = HTMLSession( browser_args=[
‘--no-sand‘,
‘--disable-infobars‘
‘--user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36‘
],headless=False)
res = session.request(url=url,method=‘GET‘)
script = """
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""
try:
res.html.render(keep_page = True)
async def main():
await res.html.page.waitFor(1000)
await res.html.page.click(‘ [id = "TANGRAM__PSP_3__footerULoginBtn"]‘)
await res.html.page.type(‘ [id="TANGRAM__PSP_3__userName"]‘,‘maonanbei‘)
await res.html.page.type(‘ [id="TANGRAM__PSP_3__password"]‘,‘goudouxi‘)
await res.html.page.screenshot({‘path‘: ‘login.png‘})
await res.html.page.waitFor(100000000)
asyncio.get_event_loop().run_until_complete(main())
except Exception as e:
print(e)
finally:
session.close()request-html 简单爬虫与案列
标签:with click final 推荐 fir question 元素 exp tab
原文地址:https://www.cnblogs.com/abdm-989/p/12143485.html
下一篇:JS-对象常用方法整理
文章标题:request-html 简单爬虫与案列
文章链接:http://soscw.com/index.php/essay/80957.html