使用Selenium对网页元素进行定位的诸种方法
2021-05-01 23:27
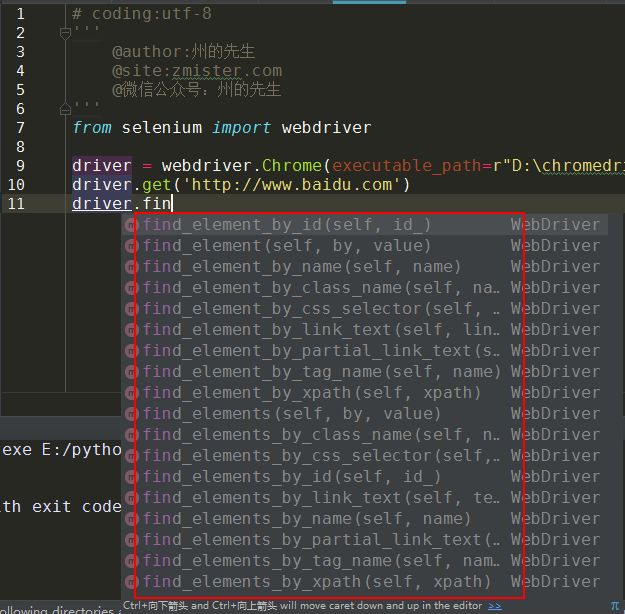
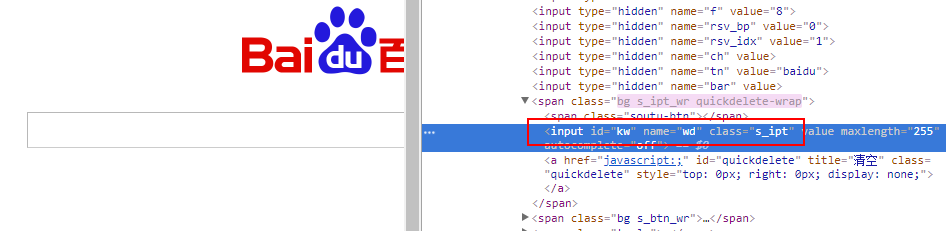
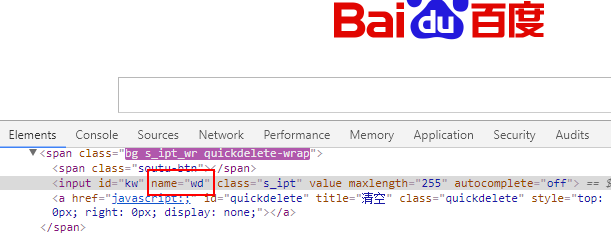
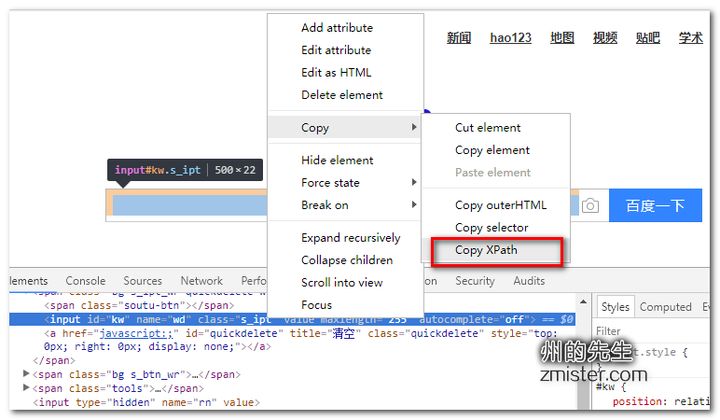
标签:python3 class sch 简单方法 公众号 因此 html nts external 使用Selenium进行自动化操作,首先要做的就是通过webdriver的get()方法打开一个URL链接。 在打开链接,完成页面加载之后,就可以通过Selenium提供的接口,在页面上进行各种操作了,下面我们来了解一下如何在查找元素。 在上一篇的示例中,我们就演示了如何通过find_element_by_id()方法,根据元素的id值来定位页面元素。 除了根据元素的id值来查找元素外,Selenium还提供了很多查找元素的方法: 从上图中可以看到,Selenium提供了近二十个find_element族的方法来供我们在页面中查找元素,其中包括id、name、类名、css选择器、链接文本、标签名、xpath等。 定位单个匹配元素的方法有: 定位多个匹配元素的方法有: 我们可以根据不同页面的不同情况来查找定位到我们所需要的页面元素。 如果你知道元素的id属性值,那么可以使用find_element_by_id()方法来定位元素,其将返回id属性值与该位置匹配的第一个元素。 百度首页的搜索框结构如下图: ele返回的是一个对应的element元素: 如果没有元素匹配传入的id值,将会抛出一个NoSuchElementException异常: 运行代码,因为没有匹配的id值,所以抛出了异常: 如果你知道元素的name属性值,那么可以使用find_element_by_name()方法获取第一个匹配name属性值的元素: ele返回匹配到的element元素: 如果定位一个没有的name属性值,那么也会抛出NoSuchElementException异常: XPath是用于在XML文档中查找节点的一种语言。由于HTML可以是XML(XHTML)的实现,因此我们可以利用这种强大的语言在网页中进行元素的定位。XPath扩展并支持了通过id或name属性定位的简单方法,并提供了各种新的操作,例如在页面上查找第三个复选框等。 使用Xpath的一个原因是,有时候页面上我们需要定位的元素并没有id属性和name属性,这时候就可以用Xpath以绝对路径的方式进行元素定位,或者是通过id或name属性值定位到父元素再取到子元素。 对于Xpath的知识,在此不做介绍,有需要的同学看看专门介绍Xpath的网站或教程,比如: 在此我们简单介绍一下如何快速地通过浏览器获取到页面元素的Xpath路径。在浏览器中打开网页调试控制台,在需要定位的元素上,单击鼠标右键,会出现一个选项栏,在“copy”中选择“Copy XPath”即可: 这样,我们通过XPath路径也能够定位到百度首页搜索框: 当我们想通过元素的标签名称来定位一个元素时,可以使用find_element_by_tag_name()这个方法,其将返回具有给定标签名称的第一个元素: 在这里,我们直接通过input的元素标签名来进行定位,因为百度首页上第一个input为搜索框,所以我们也能够定位到: 如果匹配不到,同样会抛出NoSuchElementException异常。 如果我们想通过元素的class属性值来定位,那么可以使用find_element_by_class_name()方法。其将返回匹配的第一个元素,如果没有匹配的元素,同样会抛出NoSuchElementException异常: 在这里,我们通过class类名定位了百度首页的搜索按钮。 CSS选择器是一种通过元素的CSS属性值来定位元素的语法,我们可以使用find_element_by_css_selector()方法通过css选择器定位元素: CSS选择器的绝对语法我们可以通过浏览器调试控制台中的“Copy”获取到: 除了上述的元素定位方式,我们还可以通过a标签上的文字进行元素定位,使用的是find_element_by_link_text()方法。 在百度首页的最顶部,是有一排链接的,如下图: 如果我们需要定位到“地图”那个链接元素上,就可以这样操作: 这样就成功的地位到了元素: 同样的,如果匹配不到,也会抛出NoSuchElementException异常: 匹配不到链接文字为“州的先生”的元素: 在本篇,我们介绍了在使用Selenium打开一个页面之后,如何通过id属性、name属性、class属性、Xpath路径、CSS选择器、标签名等方式对元素进行查找和地位。成功定位页面元素是对页面进行复杂操作的一个重要前提,下一篇我们将会介绍在页面中进行各种操作。 使用Selenium对网页元素进行定位的诸种方法 标签:python3 class sch 简单方法 公众号 因此 html nts external 原文地址:https://www.cnblogs.com/jiachangwei/p/12142845.html3.1 查找和定位网页元素
3.2 通过id属性进行定位
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_id(‘haha‘)
print(ele)
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_id(‘haha‘)
print(ele)
3.3通过name属性进行定位
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_name(‘wd‘)
print(ele)C:\Python35\python.exe E:/pythonproject/selenium_env/code/2.py
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_name(‘zmister‘)
print(ele)
3.4 通过Xpath进行元素定位
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_xpath(‘//*[@id="kw"]‘)
print(ele)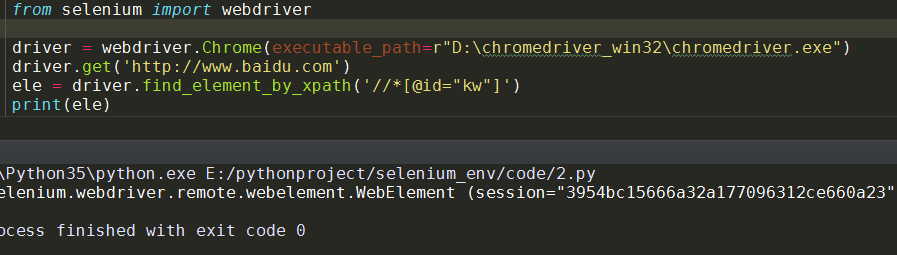
3.5 通过标签名来定位元素
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_tag_name(‘input‘)
print(ele)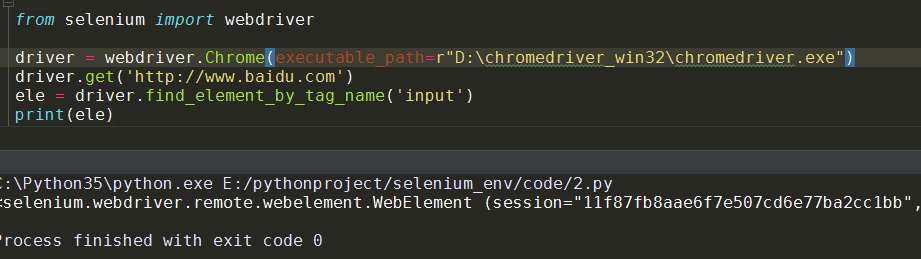
3.6 通过class类名来定位元素
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_class_name(‘s_btn‘)
print(ele)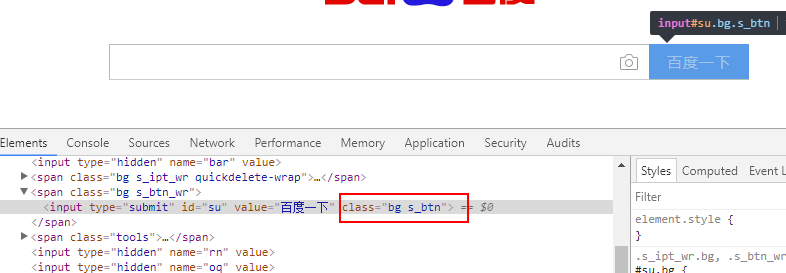
3.7 通过CSS选择器进行定位元素
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_css_selector(‘input.s_btn‘)
print(ele)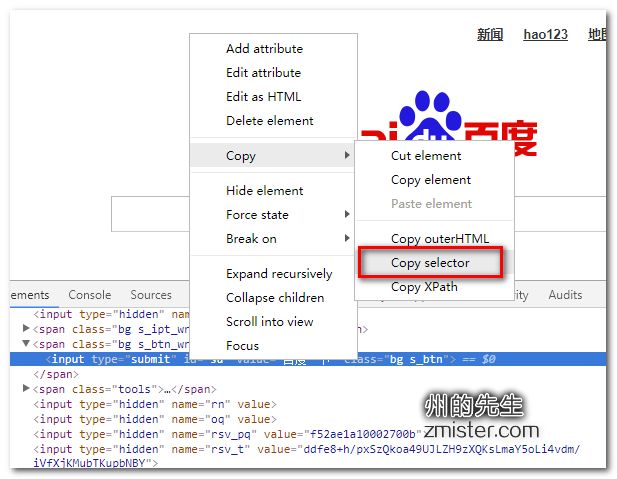
3.8 通过链接标签文字定位元素

# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_link_text(‘地图‘)
print(ele)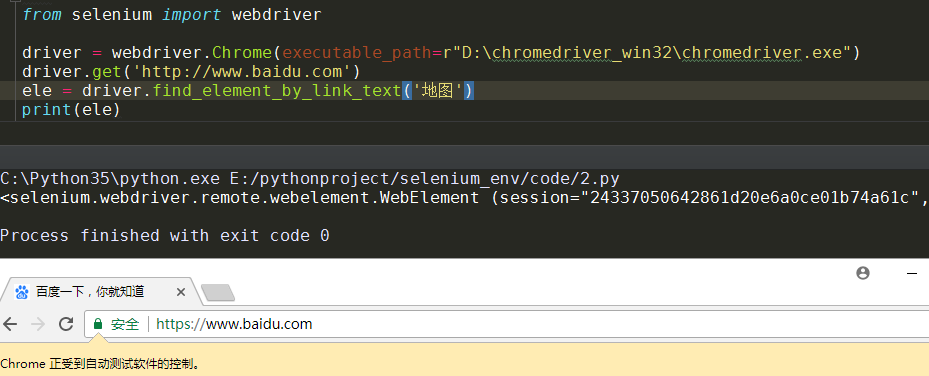
# coding:utf-8
‘‘‘
@author:州的先生
@site:zmister.com
@微信公众号:州的先生
‘‘‘
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
driver.get(‘http://www.baidu.com‘)
ele = driver.find_element_by_link_text(‘州的先生‘)
print(ele)
3.9总结
下一篇:Web前端
文章标题:使用Selenium对网页元素进行定位的诸种方法
文章链接:http://soscw.com/index.php/essay/81073.html