requests库结合selenium库共同完成web自动化和爬虫工作
2021-05-06 20:29
标签:爬虫 异步加载 html 参数 列表 利用 加载 utils 异步 我们日常工作中,单纯的HTTP请求,程序员都倾向于使用万能的python Requests库。但大多数场景下,我们的需求页面不是纯静态网页,网页加载过程中伴随有大量的JS文件参与页面的整个渲染过程,且页面的每一步操作可能都能找到异步加载XHR的影子。所以Requests库不是万能的,Requests-Html库就能解决一部分问题,前提是您知道这个过程加载了哪些js文件。小爬的实际工作中,更倾向于Requests+selenium的模式来完成整个网页信息的爬取。 能用Requests库直接请求获得数据的,就直接用requests的Session类来请求,碰到页面中JS载入较多的,就切换到selenium来执行。 那么问题来了,如何从requests优雅地切换到selenium来完成整个网页的自动化过程呢?很多时候,我们的页面信息爬取,服务器都是要求用户先登陆的,然后每次请求的时候保证会话session和基本cookies不变,就可以一直保证后台的登陆状态。那么requests库的cookies如何传给selenium用呢?这样切换到selenium时,我们不用再次登陆,而是直接用requests给的cookies绑定到 selenium下,请求目标网页,打开的网页就可以天然是登陆状态了。 我们先使用requests库来登陆,代码通常是这样(需要抓包看后台的post请求的data参数,我们请求前构造这个参数就可以了,每个网页的登陆的data参数不尽相同): 完成这部操作后,我们可以通过Post请求的status_code是否等于200来判断页面是否成功登陆。一旦登陆成功,则我们的session请求该网站后续的网页时,这个session就可以一直保持下去了。 接下来,我么要拿到requests登陆网站后的cookies,它是requests的Cookiejar类的一个实例。Cookiejar简单来说就是获取响应的cookie,cookie是存储在浏览器的一些信息,包括用户的登陆信息和一些操作,我们从服务器中获取的响应信息中,有时候也会包含一些cookie信息。 问题是这个cookiejar对象不是我们常见的字典型cookies对象,我们需要利用requests库的utils.dict_from_cookiejar方法来把cookiejar对象转换为python的字典对象。 得到的cookies大概如下形式: 但是这依然不是selenium支持的cookies格式。实际上,selenium使用driver.get_cookies()方法得到的cookies如下:列表中包含多个cookie字典,每个字典中包含多个键值对,而所有的键中,有的不是必须的,但是“name","value"这两个键是必填的。 需要注意的是,必须先要driver.get(your url),然后才能使用driver.add_cookie方法,否则selenium会报错。 至此,我们的selenium就成功添加了requests中捕获的响应的cookies,我们的selenium就不用再被服务器要求先登陆了。requests就和selenium完成了无缝衔接,完美! requests库结合selenium库共同完成web自动化和爬虫工作 标签:爬虫 异步加载 html 参数 列表 利用 加载 utils 异步 原文地址:https://www.cnblogs.com/new-june/p/12095905.htmlloginData={‘redirect‘:‘‘,‘username‘:username,‘password‘:psw}
session = requests.Session()
r=session.post(‘%sportal/u/a/login.do‘%base_url,loginData)

cookies=session.cookies
cookies=requests.utils.dict_from_cookiejar(cookies)
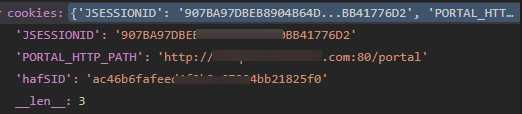
"""传递request cookie给 selenium用"""
for k,v in cookies.items():
driver.add_cookie({"name":k,"value":v})
文章标题:requests库结合selenium库共同完成web自动化和爬虫工作
文章链接:http://soscw.com/index.php/essay/83376.html