用python操作PDF文件
2021-05-07 01:28
标签:https 字符串 col fread erro 添加 vbo vsr error 从PDF读取文本内容和从已经有的文档生成新的PDF。 需要用到的模块是PyPDF2. 同时,还要关注较新的PyPDF4包,因为它很快就会取代PyPDF2。也可以看看pdfrw包,它也可以执行许多与PyPDF2相同的操作。 https://zhuanlan.zhihu.com/p/98626155 首先安装PyPDF2,在命令行中运行,由于PyPDF2没有任何依赖,因此安装非常快。 pip install PyPDF2. PyPDF2无法从pdf文档中提取图像,图表和其他媒体,但是它可以提取文本,并且将文本返回为python字符串。 读取pdf文件的页数是: 获取第一页的内容: 内容是 某些文档有加密功能,为了防止别人阅读,只有在打开文档的时候提供口令才能阅读。我打开的文件的加密口令是rosebud. 其实在读取一个pdf文件是首先应该确定它是否加密了。如果加密,isEncrypted属性就会返回True.此时就需要口令了。 返回的结果是: 如果这时候不输入口令就获取内容的话。 会提示出现错误。 此时调用decrypt方法,输入口令,再读取就可以啦。 返回的结果是: PyPDF2可以创建一个新的PDF文件,但是不能将任何文本写入到PDF。其写入PDF的能力,仅限于从其他PDF中拷贝页面、旋转页面、重叠页面和加密文件。后面一一介绍。 在对应目录下生成pdf文件 利用rotateClockwise()和rotateCounterClockwise()方法PDF页面可以旋转90的整倍数。 点击开PDF文档,结果是: 有的时候需要在PDF中添加公司的标志、时间戳或水印。我们用这个库依然可以实现。 结果是: 我们可以对拷贝的页面进行加密。 点击生成的PDF文件。 输入密码才可以打开。 用python操作PDF文件 标签:https 字符串 col fread erro 添加 vbo vsr error 原文地址:https://www.cnblogs.com/springsnow/p/13186814.html一、操作方法
1、从PDF读取文本
import PyPDF2
# ===============从pdf中提取文本===========
pdffile = open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\meetingminutes.pdf‘, ‘rb‘) # 读取pdf文件
pdfreader = PyPDF2.PdfFileReader(pdffile) # 读入到
print(pdfreader.numPages) # 读取pdf页数======19

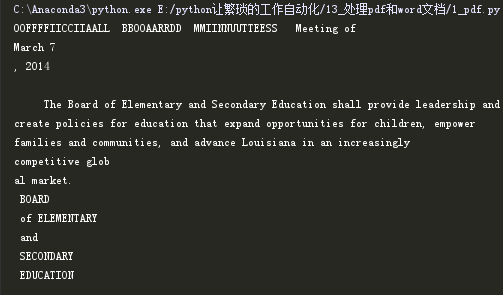
page0 = pdfreader.getPage(0) #获取第1页,第一页是0
print(page0.extractText()) # 获取第2页的内容,返回的是字符串
2、解密PDF
# 某些pdf文件是加密的,防止别人阅读的,只有打开文档的时候提供口令才能阅读
pdf_reader = PyPDF2.PdfFileReader(open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\encrypted.pdf‘,‘rb‘))
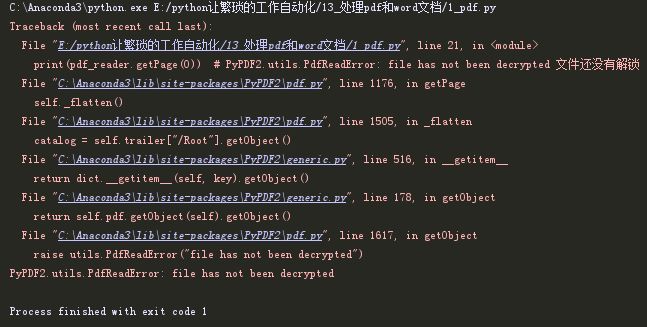
print(pdf_reader.isEncrypted) # 文件是否加密

print(pdf_reader.getPage(0)) # PyPDF2.utils.PdfReadError: file has not been decrypted 文件还没有解锁
print(pdf_reader.decrypt(‘rosebud‘)) # rosebud==正确口令显示1,其他显示0
page_obj = pdf_reader.getPage(0) # 这样才能正确读取
print(page_obj.extractText())
3、创建PDF
4、拷贝页面
# ==========拷贝页面==============
pdffile1 = open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\meetingminutes.pdf‘, ‘rb‘)
pdffile2 = open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\meetingminutes2.pdf‘, ‘rb‘)
pdf1_reader = PyPDF2.PdfFileReader(pdffile1)
pdf2_reader = PyPDF2.PdfFileReader(pdffile2)
# 创建一个pdf文档,这个只是代表pdf文档的值,并没有创建实际的文档。
pdf_writer = PyPDF2.PdfFileWriter()
# 将文档一页一页的读入到新的文档
for pagenum in range(pdf1_reader.numPages):
pageobj = pdf1_reader.getPage(pagenum)
pdf_writer.addPage(pageobj)
for pagenum in range(pdf2_reader.numPages):
pageobj = pdf2_reader.getPage(pagenum)
pdf_writer.addPage(pageobj)
# write方法才能真正生成一个文件
pdfoutputfile = open(‘combin.pdf‘,‘wb‘)
pdf_writer.write(pdfoutputfile)
pdfoutputfile.close()
pdffile1.close()
pdffile2.close()

5、旋转页面
pdffile1 = open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\meetingminutes.pdf‘, ‘rb‘)
pdfreaders = PyPDF2.PdfFileReader(pdffile1)
page = pdfreaders.getPage(0) # 获取第一页
page.rotateClockwise(90) # 第一页旋转90度
# 创建一个新的PDF文档
pdfwriter = PyPDF2.PdfFileWriter()
# 添加内容
pdfwriter.addPage(page)
# 真实创建PDF文件并写入内容
result = open(‘ratated.pdf‘,‘wb‘)
pdfwriter.write(result)
# 关闭文件
result.close()
pdffile1.close()

6、叠加页面
# 给指定的页面添加水印、公司标志或者时间戳。
pdffile1 = open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\meetingminutes.pdf‘, ‘rb‘)
pdf_reader1 = PyPDF2.PdfFileReader(pdffile1)
# 获取该文档的第一页
first_page = pdf_reader1.getPage(0)
# 打开印有水印的PDF文件
water_pdf = PyPDF2.PdfFileReader(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\watermark.pdf‘, ‘rb‘)
# 在上一个文档的第一页中加入这个有水印的文件
first_page.mergePage(water_pdf.getPage(0))
# 将读取的内容写入到对象中
pdfwriter = PyPDF2.PdfFileWriter()
pdfwriter.addPage(first_page)

7、加密PDF
pdffile1 = open(r‘E:\python让繁琐的工作自动化\13_处理pdf和word文档\data\meetingminutes.pdf‘, ‘rb‘)
pdf_reader1 = PyPDF2.PdfFileReader(pdffile1)
# 将读取的内容写入对象中
pdfwriter = PyPDF2.PdfFileWriter()
for pagenum in range(pdf_reader1.numPages):
pdfwriter.addPage(pdf_reader1.getPage(pagenum))
# 输入口令
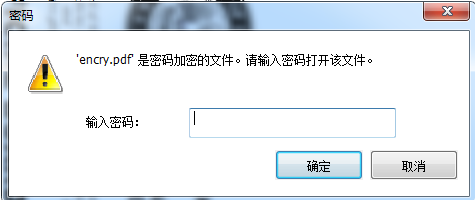
pdfwriter.encrypt(‘meimei‘)
# 真正创建PDF文件
result_pdf = open(‘encry.pdf‘,‘wb‘)
pdfwriter.write(result_pdf)
# 关闭文件
result_pdf.close()
上一篇:jfinal运行时报错分析java.lang.ClassNotFoundException: com.sun.faces.config.ConfigureListener
下一篇:Python爬虫-爬取音乐资源