python动态柱状图图表可视化:历年软科中国大学排行
2021-05-08 04:28
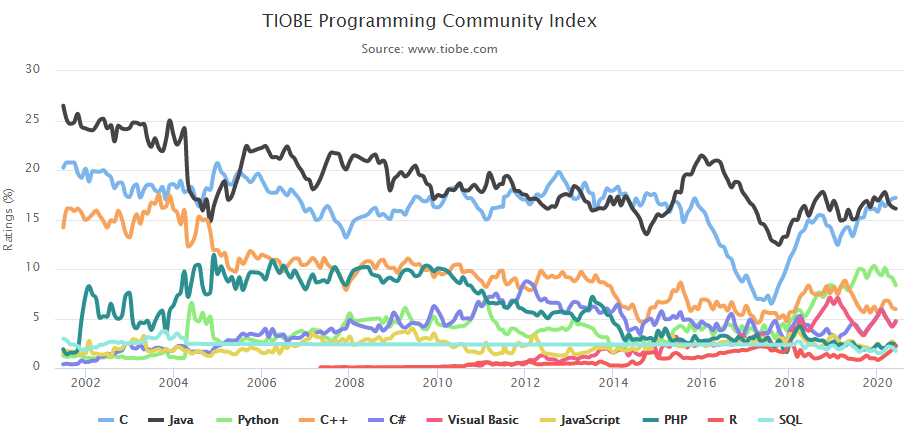
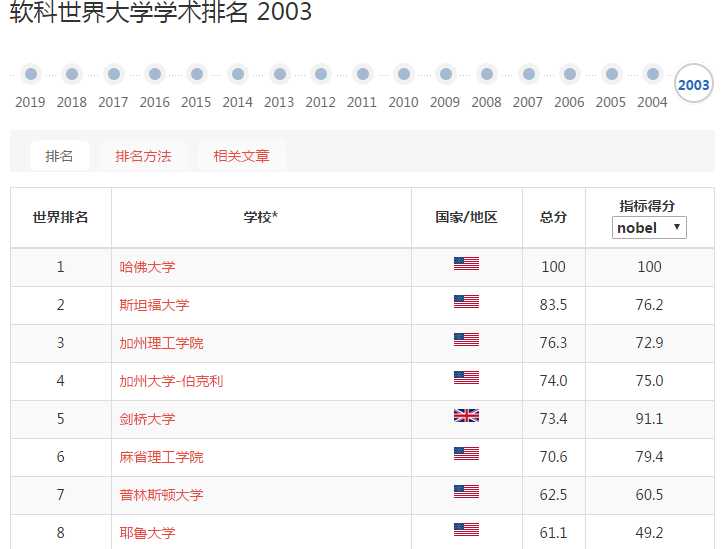
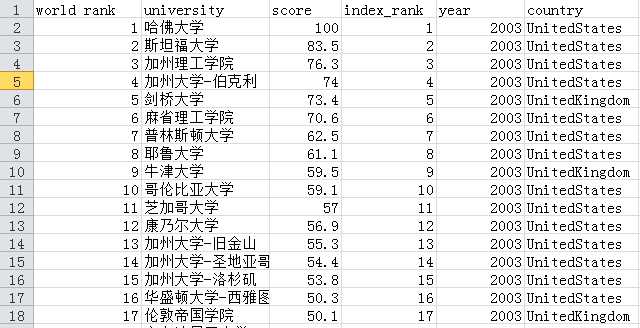
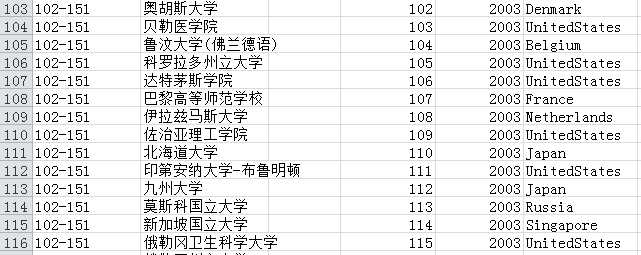
标签:相关 ranking web lxml star beautiful 世界排名 利用 实现 本来想参照:https://mp.weixin.qq.com/s/e7Wd7aEatcLFGgJUDkg-EQ搞一个往年编程语言动态图的,奈何找不到数据,有数据来源的欢迎在评论区留言。 这里找到了一个,是2020年6月的编程语言排行,供大家看一下:https://www.tiobe.com/tiobe-index/ 我们要实现的效果是: 大学排名来源:http://www.zuihaodaxue.com/ARWU2003.html 部分截图: 在http://www.zuihaodaxue.com/ARWU2003.html中的年份可以选择,我们解析的页面就有了: 初步获取页面的html信息的代码: 我们在页面上进行检查: 数据是存储在表格中的,这样我们就可以利用pandas获取html中的数据,基本语法: 其中的num是标识网页中的第几个表格,这里只有一个表格,所以标识为0。初步的解析代码就有了: 我们还要将爬取下来的数据存储到csv文件中,基本代码如下: 最后是一个主函数,别忘了还有需要导入的包: 运行之后,我们在同级目录下就可以看到university.csv,部分内容如下: 存在两个问题: (1)缺少年份 (2)最后一列没有用 (3)国家由于是图片表示,没有爬取下来 (4)排名100以后的是一个区间 我们接下来一一解决: (1)删掉没用的列 新的结果: (2) 对100以后的进行唯一化,增加一列index作为排名标识 (3)新增加年份 (4)新增加国家 首先我们进行检查: 发现国家在td->a>img下的图像路径中有名字:UnitedStates。 我们可以取出src属性,并用正则匹配名字即可。 然后这么使用: 最终解析的整体函数如下: 运行之后: 最后我们要提取属于中国部分的相关信息: 首先将年份改一下,获取到2019年为止的信息: 然后我们提取到中国高校的信息,直接看代码理解: 本来是想爬取从2003年到2019年的,运行时发现从2005年开始,页面不一样了,多了一列: 方便起见,我们就只从2005年开始了,还需要修改一下代码: 最后是整体代码: 运行之后会有一个university_ranking.csv,部分内容如下: 接下来就是可视化过程了。 1、 首先,到作者的github主页: 2、克隆仓库文件,使用git 这里如果git clone超时可参考: https://www.cnblogs.com/xiximayou/p/12305209.html 需要注意的是,这里的npm是我之前装node.js装了的,没有的自己需要装以下。 在执行npm install时会报错: 先执行: npm init 之后一直回车即可: 再执行npm install 任意浏览器打开 只能制作动图上传了。 可以看到,有了大致的可视化效果,但还存在很多瑕疵,比如:表顺序颠倒了、字体不合适、配色太花哨等。可不可以修改呢? 当然是可以的,只需要分别修改文件夹中这几个文件的参数就可以了: config.js 全局设置各项功能的开关,比如配色、字体、文字名称、反转图表等等功能; color.css 修改柱形图的配色; stylesheet.css 具体修改配色、字体、文字名称等的css样式; visual.js 更进一步的修改,比如图表的透明度等。 知道在哪里修改了以后,那么,如何修改呢?很简单,只需要简单的几步就可以实现: 打开网页, 把参数复制到四个文件中对应的文件里并保存。 Git Bash运行 这里我主要修改的是config.js的以下项: 最终效果: 至此,就全部完成了。 看起来简单,还是得要自己动手才行。 python动态柱状图图表可视化:历年软科中国大学排行 标签:相关 ranking web lxml star beautiful 世界排名 利用 实现 原文地址:https://www.cnblogs.com/xiximayou/p/13179488.html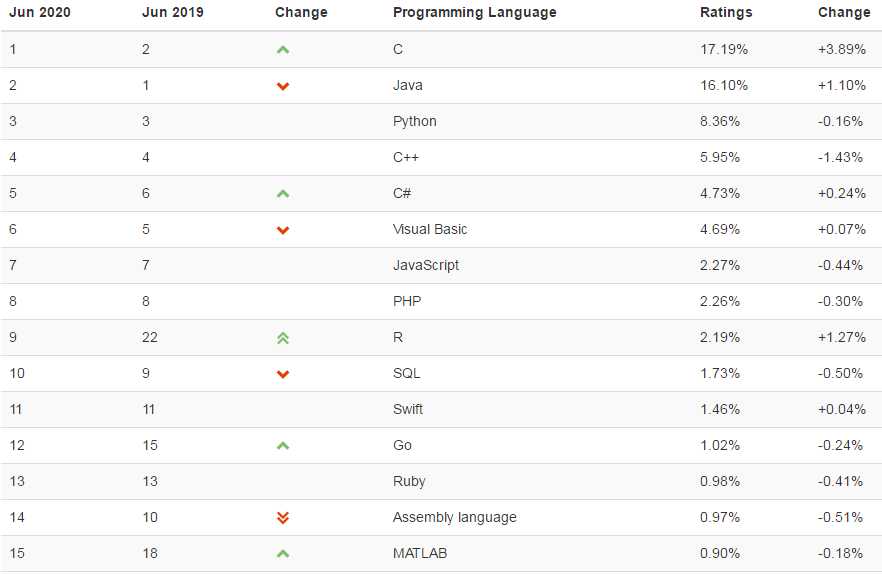
"http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
def get_one_page(year):
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36‘
}
url = "http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
response=requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
except RequestException:
print(‘爬取失败‘)
tb = pd.read_html(url)[num]
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
return tb
def save_csv(tb):
start_time=time.time()
tb.to_csv(r‘university.csv‘, mode=‘a‘, encoding=‘utf_8_sig‘, header=True, index=0)
endtime = time.time()-start_time
print(‘程序运行了%.2f秒‘ %endtime)
import requests
from requests.exceptions import RequestException
import pandas as pd
import time
def main(year):
for i in range(2003,year):
html=get_one_page(i)
tb=parse_on_page(html,i)
#print(tb)
save_csv(tb)
if __name__ == "__main__":
main(2004)
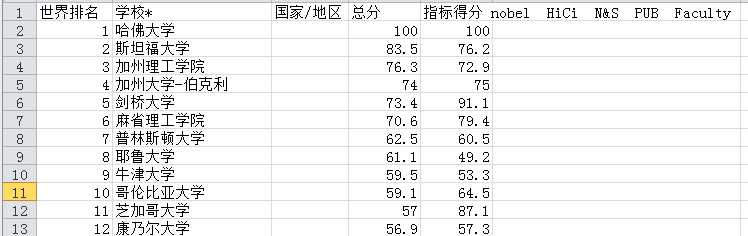
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
# 重命名表格列,不需要的列用数字表示
tb.columns = [‘world rank‘,‘university‘, 2, ‘score‘,4]
tb.drop([2,4],axis=1,inplace=True)
return tb
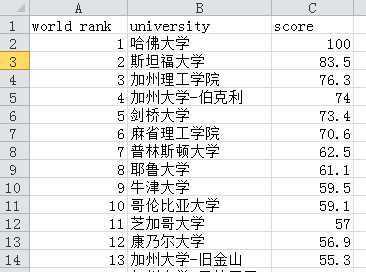
tb[‘index_rank‘] = tb.index
tb[‘index_rank‘] = tb[‘index_rank‘].astype(int) + 1
tb[‘year‘] = i


def get_country(html):
soup = BeautifulSoup(html,‘lxml‘)
countries = soup.select(‘td > a > img‘)
lst = []
for i in countries:
src = i[‘src‘]
pattern = re.compile(‘flag.*\/(.*?).png‘)
country = re.findall(pattern,src)[0]
lst.append(country)
return lst
# read_html没有爬取country,需定义函数单独爬取
tb[‘country‘] = get_country(html)
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
# 重命名表格列,不需要的列用数字表示
tb.columns = [‘world rank‘,‘university‘, 2, ‘score‘,4]
tb.drop([2,4],axis=1,inplace=True)
tb[‘index_rank‘] = tb.index
tb[‘index_rank‘] = tb[‘index_rank‘].astype(int) + 1
tb[‘year‘] = i
# read_html没有爬取country,需定义函数单独爬取
tb[‘country‘] = get_country(html)
return tb
if __name__ == "__main__":
main(2019)
def analysis():
df = pd.read_csv(‘university.csv‘)
# 包含港澳台
# df = df.query("(country == ‘China‘)|(country == ‘China-hk‘)|(country == ‘China-tw‘)|(country == ‘China-HongKong‘)|(country == ‘China-Taiwan‘)|(country == ‘Taiwan,China‘)|(country == ‘HongKong,China‘)")[[‘university‘,‘year‘,‘index_rank‘]]
# 只包括内地
df = df.query("(country == ‘China‘)")
df[‘index_rank_score‘] = df[‘index_rank‘]
# 将index_rank列转为整形
df[‘index_rank‘] = df[‘index_rank‘].astype(int)
# 美国
# df = df.query("(country == ‘UnitedStates‘)|(country == ‘USA‘)")
#求topn名
def topn(df):
top = df.sort_values([‘year‘,‘index_rank‘],ascending = True)
return top[:20].reset_index()
df = df.groupby(by =[‘year‘]).apply(topn)
# 更改列顺序
df = df[[‘university‘,‘index_rank_score‘,‘index_rank‘,‘year‘]]
# 重命名列
df.rename (columns = {‘university‘:‘name‘,‘index_rank_score‘:‘type‘,‘index_rank‘:‘value‘,‘year‘:‘date‘},inplace = True)
# 输出结果
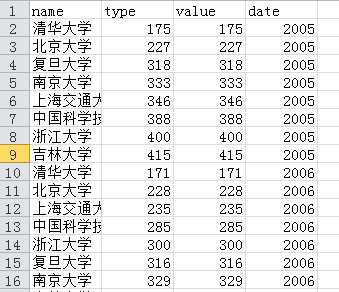
df.to_csv(‘university_ranking.csv‘,mode =‘w‘,encoding=‘utf_8_sig‘, header=True, index=False)
# index可以设置
# 重命名表格列,不需要的列用数字表示
tb.columns = [‘world rank‘,‘university‘, 2,3, ‘score‘,5]
tb.drop([2,3,5],axis=1,inplace=True)
import requests
from requests.exceptions import RequestException
import pandas as pd
import time
from bs4 import BeautifulSoup
import re
def get_one_page(year):
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36‘
}
url = "http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
response=requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
except RequestException:
print(‘爬取失败‘)
def parse_on_page(html,i):
tb=pd.read_html(html)[0]
# 重命名表格列,不需要的列用数字表示
tb.columns = [‘world rank‘,‘university‘, 2,3, ‘score‘,5]
tb.drop([2,3,5],axis=1,inplace=True)
tb[‘index_rank‘] = tb.index
tb[‘index_rank‘] = tb[‘index_rank‘].astype(int) + 1
tb[‘year‘] = i
# read_html没有爬取country,需定义函数单独爬取
tb[‘country‘] = get_country(html)
return tb
def save_csv(tb):
start_time=time.time()
tb.to_csv(r‘university.csv‘, mode=‘a‘, encoding=‘utf_8_sig‘, header=True, index=0)
endtime = time.time()-start_time
print(‘程序运行了%.2f秒‘ %endtime)
# 提取国家名称
def get_country(html):
soup = BeautifulSoup(html,‘lxml‘)
countries = soup.select(‘td > a > img‘)
lst = []
for i in countries:
src = i[‘src‘]
pattern = re.compile(‘flag.*\/(.*?).png‘)
country = re.findall(pattern,src)[0]
lst.append(country)
return lst
def analysis():
df = pd.read_csv(‘university.csv‘)
# 包含港澳台
# df = df.query("(country == ‘China‘)|(country == ‘China-hk‘)|(country == ‘China-tw‘)|(country == ‘China-HongKong‘)|(country == ‘China-Taiwan‘)|(country == ‘Taiwan,China‘)|(country == ‘HongKong,China‘)")[[‘university‘,‘year‘,‘index_rank‘]]
# 只包括内地
df = df.query("(country == ‘China‘)")
df[‘index_rank_score‘] = df[‘index_rank‘]
# 将index_rank列转为整形
df[‘index_rank‘] = df[‘index_rank‘].astype(int)
# 美国
# df = df.query("(country == ‘UnitedStates‘)|(country == ‘USA‘)")
#求topn名
def topn(df):
top = df.sort_values([‘year‘,‘index_rank‘],ascending = True)
return top[:20].reset_index()
df = df.groupby(by =[‘year‘]).apply(topn)
# 更改列顺序
df = df[[‘university‘,‘index_rank_score‘,‘index_rank‘,‘year‘]]
# 重命名列
df.rename (columns = {‘university‘:‘name‘,‘index_rank_score‘:‘type‘,‘index_rank‘:‘value‘,‘year‘:‘date‘},inplace = True)
# 输出结果
df.to_csv(‘university_ranking.csv‘,mode =‘w‘,encoding=‘utf_8_sig‘, header=True, index=False)
# index可以设置
def main(year):
for i in range(2005,year):
html=get_one_page(i)
tb=parse_on_page(html,i)
save_csv(tb)
print(i,‘年排名提取完成完成‘)
analysis()
if __name__ == "__main__":
main(2019)
https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
# 克隆项目仓库
git clone https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
# 切换到项目根目录
cd Historical-ranking-data-visualization-based-on-d3.js
# 安装依赖
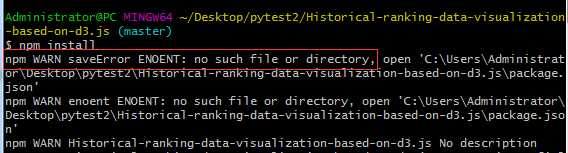
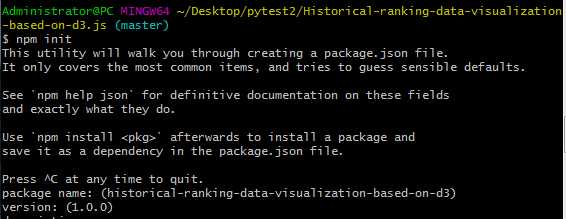
npm install

bargraph.html网页,点击选择文件,然后选择前面输出的university_ranking.csv文件,看下效果:
右键-检查,箭头指向想要修改的元素,然后在右侧的css样式表里,双击各项参数修改参数,修改完元素就会发生变化,可以不断微调,直至满意为止。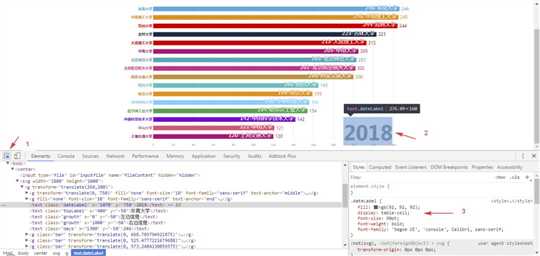
npm run build,之后刷新网页就可以看到优化后的效果。(我发现这一步其实不需要,而且会报错,我直接修改config.js之后运行也成功了) // 倒序,使得最短的条位于最上方
reverse: true,
// 附加信息内容。
// left label
itemLabel: "本年度第一大学",
// right label
typeLabel: "世界排名",
//为了避免名称重叠
item_x: 500,
// 时间标签坐标。建议x:1000 y:-50开始尝试,默认位置为x:null,y:null
dateLabel_x: 1000,
dateLabel_y: -50,
文章标题:python动态柱状图图表可视化:历年软科中国大学排行
文章链接:http://soscw.com/index.php/essay/83947.html