爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息
2021-05-08 17:32
标签:findall 图片 源代码 wrapper src rom -name top ram 爬取源代码如下: Origin:\s(.*?) Meaning:\s(.*?) Why it’s big:\s(.*?) 爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息 标签:findall 图片 源代码 wrapper src rom -name top ram 原文地址:https://www.cnblogs.com/c1q2s3/p/12078047.html
import bs4
from bs4 import BeautifulSoup
import re
import pandas as pd
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
lilist=[]
r=requests.get(‘https://www.parenting.com/baby-names/boys/earl‘)
soup=BeautifulSoup(r.text,"lxml")
soup= soup.find_all(‘a‘,href=True)
for i in soup:
if ‘https://www.parenting.com/pregnancy/baby-names/baby-boy-names/‘ in str(i)or‘https://www.parenting.com/pregnancy/baby-names/girl-baby-names/‘ in str(i):
lilist.append(i.get("href"))
results1=[]
results=[]
results2=[]
for i in list(set(lilist)):
r=requests.get(i)
soup=BeautifulSoup(r.text,"lxml")
Source=soup.find_all(attrs={‘class‘: ‘description‘})
results0 = re.findall(‘(.*?)
‘, r.text)
for c in results0:
if c!=‘‘:
lilist1.append(c)
#print(lilist1)
#lilist1=[]
results += re.findall(pattern, str(Source))
pattern1 = re.compile(‘
results1 += re.findall(pattern1, str(Source))
results2 += re.findall(pattern2, str(Source))
print(lilist1)
print(results1)
print(results)
print(results2)
data = {
‘EnName‘:lilist1,
‘Meaning‘:results1,
‘Origin‘:results,
‘Description‘:results2
}
frame = pd.DataFrame(data)
frame.to_csv(‘wt10.csv‘,encoding="gb18030")
#print(results2)
csv文件截图: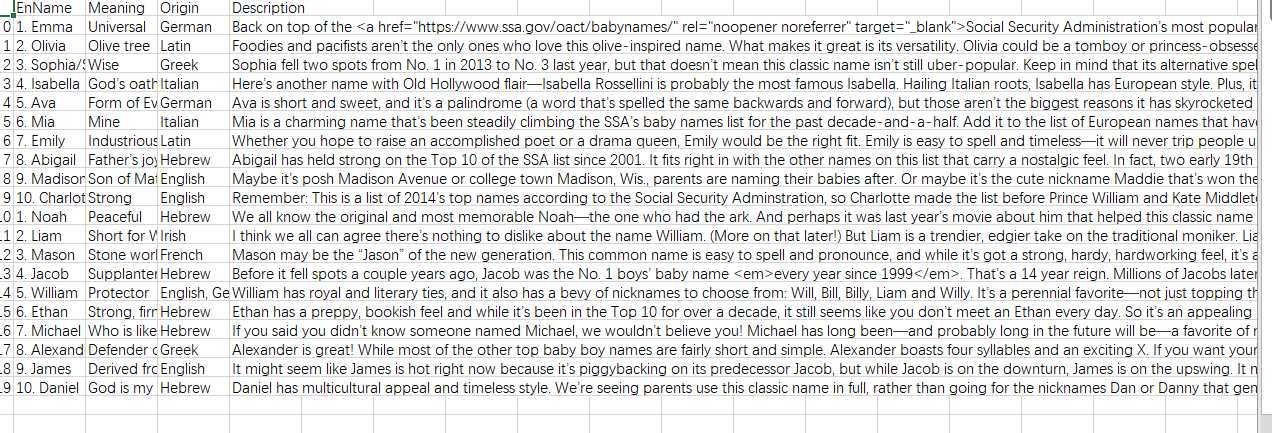
下一篇:C#基础--杂项
文章标题:爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息
文章链接:http://soscw.com/index.php/essay/84085.html