Python机器学习(十九)决策树之系列二—C4.5原理与代码实现
2021-05-11 05:29
阅读:560
ID3算法缺点
它一般会优先选择有较多属性值的Feature,因为属性值多的特征会有相对较大的信息增益,信息增益反映的是,在给定一个条件以后,不确定性减少的程度,
这必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大。为了解决这个问题,C4.5就应运而生,它采用信息增益率来作为选择分支的准则。
C4.5算法原理
信息增益率定义为:
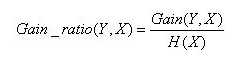
其中,分子为信息增益(信息增益计算可参考上一节ID3的算法原理),分母为属性X的熵。
需要注意的是,增益率准则对可取值数目较少的属性有所偏好。
所以一般这样选取划分属性:选择增益率最高的特征列作为划分属性的依据。
代码实现
与ID3代码实现不同的是:只改变计算香农熵的函数calcShannonEnt,以及选择最优特征索引函数chooseBestFeatureToSplit,具体代码如下:



1 # -*- coding: utf-8 -*- 2 """ 3 Created on Thu Aug 2 17:09:34 2018 4 决策树ID3,C4.5的实现 5 @author: weixw 6 """ 7 from math import log 8 import operator 9 #原始数据 10 def createDataSet(): 11 dataSet = [[1, 1, ‘yes‘], 12 [1, 1, ‘yes‘], 13 [1, 0, ‘no‘], 14 [0, 1, ‘no‘], 15 [0, 1, ‘no‘]] 16 labels = [‘no surfacing‘,‘flippers‘] 17 return dataSet, labels 18 19 #多数表决器 20 #列中相同值数量最多为结果 21 def majorityCnt(classList): 22 classCounts = {} 23 for value in classList: 24 if(value not in classCounts.keys()): 25 classCounts[value] = 0 26 classCounts[value] +=1 27 sortedClassCount = sorted(classCounts.iteritems(),key = operator.itemgetter(1),reverse =True) 28 return sortedClassCount[0][0] 29 30 31 #划分数据集 32 #dataSet:原始数据集 33 #axis:进行分割的指定列索引 34 #value:指定列中的值 35 def splitDataSet(dataSet,axis,value): 36 retDataSet= [] 37 for featDataVal in dataSet: 38 if featDataVal[axis] == value: 39 #下面两行去除某一项指定列的值,很巧妙有没有 40 reducedFeatVal = featDataVal[:axis] 41 reducedFeatVal.extend(featDataVal[axis+1:]) 42 retDataSet.append(reducedFeatVal) 43 return retDataSet 44 45 #计算香农熵 46 #columnIndex = -1表示获取数据集每一项的最后一列的标签值 47 #其他表示获取特征列 48 def calcShannonEnt(columnIndex, dataSet): 49 #数据集总项数 50 numEntries = len(dataSet) 51 #标签计数对象初始化 52 labelCounts = {} 53 for featDataVal in dataSet: 54 #获取数据集每一项的最后一列的标签值 55 currentLabel = featDataVal[columnIndex] 56 #如果当前标签不在标签存储对象里,则初始化,然后计数 57 if currentLabel not in labelCounts.keys(): 58 labelCounts[currentLabel] = 0 59 labelCounts[currentLabel] += 1 60 #熵初始化 61 shannonEnt = 0.0 62 #遍历标签对象,求概率,计算熵 63 for key in labelCounts.keys(): 64 prop = labelCounts[key]/float(numEntries) 65 shannonEnt -= prop*log(prop,2) 66 return shannonEnt 67 68 69 #通过信息增益,选出最优特征列索引(ID3) 70 def chooseBestFeatureToSplit(dataSet): 71 #计算特征个数,dataSet最后一列是标签属性,不是特征量 72 numFeatures = len(dataSet[0])-1 73 #计算初始数据香农熵 74 baseEntropy = calcShannonEnt(-1, dataSet) 75 #初始化信息增益,最优划分特征列索引 76 bestInfoGain = 0.0 77 bestFeatureIndex = -1 78 for i in range(numFeatures): 79 #获取每一列数据 80 featList = [example[i] for example in dataSet] 81 #将每一列数据去重 82 uniqueVals = set(featList) 83 newEntropy = 0.0 84 for value in uniqueVals: 85 subDataSet = splitDataSet(dataSet,i,value) 86 #计算条件概率 87 prob = len(subDataSet)/float(len(dataSet)) 88 #计算条件熵 89 newEntropy +=prob*calcShannonEnt(-1, subDataSet) 90 #计算信息增益 91 infoGain = baseEntropy - newEntropy 92 if(infoGain > bestInfoGain): 93 bestInfoGain = infoGain 94 bestFeatureIndex = i 95 return bestFeatureIndex 96 97 #通过信息增益率,选出最优特征列索引(C4.5) 98 def chooseBestFeatureToSplitOfFurther(dataSet): 99 #计算特征个数,dataSet最后一列是标签属性,不是特征量 100 numFeatures = len(dataSet[0])-1 101 #计算初始数据香农熵H(Y) 102 baseEntropy = calcShannonEnt(-1, dataSet) 103 #初始化信息增益,最优划分特征列索引 104 bestInfoGainRatio = 0.0 105 bestFeatureIndex = -1 106 for i in range(numFeatures): 107 #获取每一特征列香农熵H(X) 108 featEntropy = calcShannonEnt(i, dataSet) 109 #获取每一列数据 110 featList = [example[i] for example in dataSet] 111 #将每一列数据去重 112 uniqueVals = set(featList) 113 newEntropy = 0.0 114 for value in uniqueVals: 115 subDataSet = splitDataSet(dataSet,i,value) 116 #计算条件概率 117 prob = len(subDataSet)/float(len(dataSet)) 118 #计算条件熵 119 newEntropy +=prob*calcShannonEnt(-1, subDataSet) 120 #计算信息增益 121 infoGain = baseEntropy - newEntropy 122 #计算信息增益率 123 infoGainRatio = infoGain/float(featEntropy) 124 if(infoGainRatio > bestInfoGainRatio): 125 bestInfoGainRatio = infoGainRatio 126 bestFeatureIndex = i 127 return bestFeatureIndex 128 129 #决策树创建 130 def createTree(dataSet,labels): 131 #获取标签属性,dataSet最后一列,区别于labels标签名称 132 classList = [example[-1] for example in dataSet] 133 #树极端终止条件判断 134 #标签属性值全部相同,返回标签属性第一项值 135 if classList.count(classList[0]) == len(classList): 136 return classList[0] 137 #没有特征,只有标签列(1列) 138 if len(dataSet[0]) == 1: 139 #返回实例数最大的类 140 return majorityCnt(classList) 141 # #获取最优特征列索引ID3 142 # bestFeatureIndex = chooseBestFeatureToSplit(dataSet) 143 #获取最优特征列索引C4.5 144 bestFeatureIndex = chooseBestFeatureToSplitOfFurther(dataSet) 145 #获取最优索引对应的标签名称 146 bestFeatureLabel = labels[bestFeatureIndex] 147 #创建根节点 148 myTree = {bestFeatureLabel:{}} 149 #去除最优索引对应的标签名,使labels标签能正确遍历 150 del(labels[bestFeatureIndex]) 151 #获取最优列 152 bestFeature = [example[bestFeatureIndex] for example in dataSet] 153 uniquesVals = set(bestFeature) 154 for value in uniquesVals: 155 #子标签名称集合 156 subLabels = labels[:] 157 #递归 158 myTree[bestFeatureLabel][value] = createTree(splitDataSet(dataSet,bestFeatureIndex,value),subLabels) 159 return myTree 160 161 #获取分类结果 162 #inputTree:决策树字典 163 #featLabels:标签列表 164 #testVec:测试向量 例如:简单实例下某一路径 [1,1] => yes(树干值组合,从根结点到叶子节点) 165 def classify(inputTree,featLabels,testVec): 166 #获取根结点名称,将dict转化为list 167 firstSide = list(inputTree.keys()) 168 #根结点名称String类型 169 firstStr = firstSide[0] 170 #获取根结点对应的子节点 171 secondDict = inputTree[firstStr] 172 #获取根结点名称在标签列表中对应的索引 173 featIndex = featLabels.index(firstStr) 174 #由索引获取向量表中的对应值 175 key = testVec[featIndex] 176 #获取树干向量后的对象 177 valueOfFeat = secondDict[key] 178 #判断是子结点还是叶子节点:子结点就回调分类函数,叶子结点就是分类结果 179 #if type(valueOfFeat).__name__==‘dict‘: 等价 if isinstance(valueOfFeat, dict): 180 if isinstance(valueOfFeat, dict): 181 classLabel = classify(valueOfFeat,featLabels,testVec) 182 else: 183 classLabel = valueOfFeat 184 return classLabel 185 186 187 #将决策树分类器存储在磁盘中,filename一般保存为txt格式 188 def storeTree(inputTree,filename): 189 import pickle 190 fw = open(filename,‘wb+‘) 191 pickle.dump(inputTree,fw) 192 fw.close() 193 #将瓷盘中的对象加载出来,这里的filename就是上面函数中的txt文件 194 def grabTree(filename): 195 import pickle 196 fr = open(filename,‘rb‘) 197 return pickle.load(fr) 198 199 200
1 ‘‘‘ 2 Created on Oct 14, 2010 3 4 @author: Peter Harrington 5 ‘‘‘ 6 import matplotlib.pyplot as plt 7 8 decisionNode = dict(boxstyle="sawtooth", fc="0.8") 9 leafNode = dict(boxstyle="round4", fc="0.8") 10 arrow_args = dict(arrowstyle="") 11 12 #获取树的叶子节点 13 def getNumLeafs(myTree): 14 numLeafs = 0 15 #dict转化为list 16 firstSides = list(myTree.keys()) 17 firstStr = firstSides[0] 18 secondDict = myTree[firstStr] 19 for key in secondDict.keys(): 20 #判断是否是叶子节点(通过类型判断,子类不存在,则类型为str;子类存在,则为dict) 21 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 22 numLeafs += getNumLeafs(secondDict[key]) 23 else: numLeafs +=1 24 return numLeafs 25 26 #获取树的层数 27 def getTreeDepth(myTree): 28 maxDepth = 0 29 #dict转化为list 30 firstSides = list(myTree.keys()) 31 firstStr = firstSides[0] 32 secondDict = myTree[firstStr] 33 for key in secondDict.keys(): 34 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 35 thisDepth = 1 + getTreeDepth(secondDict[key]) 36 else: thisDepth = 1 37 if thisDepth > maxDepth: maxDepth = thisDepth 38 return maxDepth 39 40 def plotNode(nodeTxt, centerPt, parentPt, nodeType): 41 createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords=‘axes fraction‘, 42 xytext=centerPt, textcoords=‘axes fraction‘, 43 va="center", ha="center", bbox=nodeType, arrowprops=arrow_args ) 44 45 def plotMidText(cntrPt, parentPt, txtString): 46 xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] 47 yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] 48 createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) 49 50 def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on 51 numLeafs = getNumLeafs(myTree) #this determines the x width of this tree 52 depth = getTreeDepth(myTree) 53 firstSides = list(myTree.keys()) 54 firstStr = firstSides[0] #the text label for this node should be this 55 cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) 56 plotMidText(cntrPt, parentPt, nodeTxt) 57 plotNode(firstStr, cntrPt, parentPt, decisionNode) 58 secondDict = myTree[firstStr] 59 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD 60 for key in secondDict.keys(): 61 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 62 plotTree(secondDict[key],cntrPt,str(key)) #recursion 63 else: #it‘s a leaf node print the leaf node 64 plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW 65 plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) 66 plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) 67 plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD 68 #if you do get a dictonary you know it‘s a tree, and the first element will be another dict 69 #绘制决策树 70 def createPlot(inTree): 71 fig = plt.figure(1, facecolor=‘white‘) 72 fig.clf() 73 axprops = dict(xticks=[], yticks=[]) 74 createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks 75 #createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 76 plotTree.totalW = float(getNumLeafs(inTree)) 77 plotTree.totalD = float(getTreeDepth(inTree)) 78 plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; 79 plotTree(inTree, (0.5,1.0), ‘‘) 80 plt.show() 81 82 #绘制树的根节点和叶子节点(根节点形状:长方形,叶子节点:椭圆形) 83 #def createPlot(): 84 # fig = plt.figure(1, facecolor=‘white‘) 85 # fig.clf() 86 # createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 87 # plotNode(‘a decision node‘, (0.5, 0.1), (0.1, 0.5), decisionNode) 88 # plotNode(‘a leaf node‘, (0.8, 0.1), (0.3, 0.8), leafNode) 89 # plt.show() 90 91 def retrieveTree(i): 92 listOfTrees =[{‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: ‘no‘, 1: ‘yes‘}}}}, 93 {‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: {‘head‘: {0: ‘no‘, 1: ‘yes‘}}, 1: ‘no‘}}}} 94 ] 95 return listOfTrees[i] 96 97 #thisTree = retrieveTree(0) 98 #createPlot(thisTree) 99 #createPlot() 100 #myTree = retrieveTree(0) 101 #numLeafs =getNumLeafs(myTree) 102 #treeDepth =getTreeDepth(myTree) 103 #print(u"叶子节点数目:%d"% numLeafs) 104 #print(u"树深度:%d"%treeDepth)
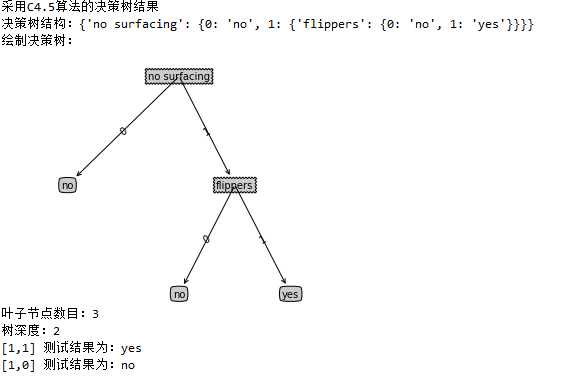
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Fri Aug 3 19:52:10 2018 4 5 @author: weixw 6 """ 7 import myTrees as mt 8 import treePlotter as tp 9 #测试 10 dataSet, labels = mt.createDataSet() 11 #copy函数:新开辟一块内存,然后将list的所有值复制到新开辟的内存中 12 labels1 = labels.copy() 13 #createTree函数中将labels1的值改变了,所以在分类测试时不能用labels1 14 myTree = mt.createTree(dataSet,labels1) 15 #保存树到本地 16 mt.storeTree(myTree,‘myTree.txt‘) 17 #在本地磁盘获取树 18 myTree = mt.grabTree(‘myTree.txt‘) 19 print(u"采用C4.5算法的决策树结果") 20 print (u"决策树结构:%s"%myTree) 21 #绘制决策树 22 print(u"绘制决策树:") 23 tp.createPlot(myTree) 24 numLeafs =tp.getNumLeafs(myTree) 25 treeDepth =tp.getTreeDepth(myTree) 26 print(u"叶子节点数目:%d"% numLeafs) 27 print(u"树深度:%d"%treeDepth) 28 #测试分类 简单样本数据3列 29 labelResult =mt.classify(myTree,labels,[1,1]) 30 print(u"[1,1] 测试结果为:%s"%labelResult) 31 labelResult =mt.classify(myTree,labels,[1,0]) 32 print(u"[1,0] 测试结果为:%s"%labelResult)
运行结果
不要让懒惰占据你的大脑,不要让妥协拖垮你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐掌握在你的脚下。
文章来自:搜素材网的编程语言模块,转载请注明文章出处。
文章标题:Python机器学习(十九)决策树之系列二—C4.5原理与代码实现
文章链接:http://soscw.com/index.php/essay/84213.html
文章标题:Python机器学习(十九)决策树之系列二—C4.5原理与代码实现
文章链接:http://soscw.com/index.php/essay/84213.html
评论
亲,登录后才可以留言!