一个完整的大作业--‘’数据观”官方网站数据爬取
2021-05-15 16:29
标签:atp res ati end .com open print 主题 panda 1.选一个自己感兴趣的主题。 ‘’数据观”官方网站数据爬取,网页网址为‘http://www.cbdio.com/node_2568.htm’ 2.网络上爬取相关的数据。 3.进行文本分析,生成词云。 4.对文本分析结果解释说明。 通过以上数据显示,该中国大数据官网主要的话题是数据以及交易 和政府、企业、专家等。 5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。 一个完整的大作业--‘’数据观”官方网站数据爬取 标签:atp res ati end .com open print 主题 panda 原文地址:http://www.cnblogs.com/huanglinxin/p/7732885.html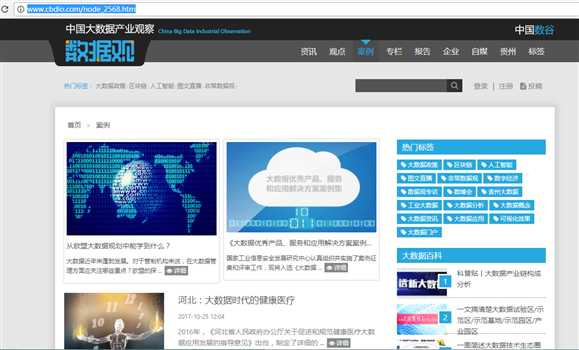
import requests
from bs4 import BeautifulSoup
url = ‘http://www.cbdio.com/node_2568.htm‘
res = requests.get(url)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
for items in soup.select(‘li‘):
if len(items.select(‘.cb-media-title‘))>0:
title=items.select(‘.cb-media-title‘)[0].text#标题
url1=items.select(‘a‘)[0][‘href‘]
url2=‘http://www.cbdio.com/{}‘.format(url1)#链接
resd=requests.get(url2)
resd.encoding=‘utf-8‘
soupd=BeautifulSoup(resd.text,‘html.parser‘)
source=soupd.select(‘.cb-article-info‘)[0].text.strip()#来源
content=soupd.select(‘.cb-article‘)[0].text#内容
print("################################################################################")
print(‘标题:‘,title,‘\t链接:‘,url2,source)
url=‘http://www.cbdio.com/node_2568.htm‘
res = requests.get(url)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
contentls=[]
for item in soup.select(‘li‘):
if len(item.select(‘.cb-media-title‘))>0:
url1=item.select(‘a‘)[0][‘href‘]
url2=‘http://www.cbdio.com/{}‘.format(url1)
resd=requests.get(url2)
resd.encoding=‘utf-8‘
soupd=BeautifulSoup(resd.text,‘html.parser‘)
cont=soupd.select(‘.cb-article‘)[0].text#内容
contentls.append(cont)
print(contentls)
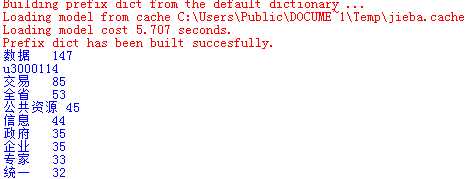
words=jieba.lcut(content)
ls=[]
counts={}
for word in words:
ls.append(word)
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(10):
word , count = items[i]
print ("{:2}".format(word,count))
#词云制作
from wordcloud import WordCloud
import matplotlib.pyplot as plt
cy = WordCloud(font_path=‘msyh.ttc‘).generate(content)
plt.imshow(cy, interpolation=‘bilinear‘)
plt.axis("off")
plt.show()

import requests
from bs4 import BeautifulSoup
def getTheContent(url1):
res = requests.get(url1)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
item={}
item[‘title‘]=soup.select(‘.cb-article-title‘)[0].text#标题
item[‘url‘]=url1#链接
resd=requests.get(item[‘url‘])
resd.encoding=‘utf-8‘
soupd=BeautifulSoup(resd.text,‘html.parser‘)
item[‘source‘]=soupd.select(‘.cb-article-info‘)[0].text.strip()#来源
item[‘content‘]=soupd.select(‘.cb-article‘)[0].text#内容
return(item)
def getOnePage(pageurl):
res = requests.get(pageurl)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
itemls=[]
for item in soup.select(‘li‘):
if len(item.select(‘.cb-media-title‘))>0:
url1=item.select(‘a‘)[0][‘href‘]
url2=‘http://www.cbdio.com/{}‘.format(url1)
itemls.append(getTheContent(url2))
return(itemls)
#结巴词频统计
import jieba
url=‘http://www.cbdio.com/node_2568.htm‘
res = requests.get(url)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
contentls=[]
for item in soup.select(‘li‘):
if len(item.select(‘.cb-media-title‘))>0:
url1=item.select(‘a‘)[0][‘href‘]
url2=‘http://www.cbdio.com/{}‘.format(url1)
resd=requests.get(url2)
resd.encoding=‘utf-8‘
soupd=BeautifulSoup(resd.text,‘html.parser‘)
cont=soupd.select(‘.cb-article‘)[0].text#内容
contentls.append(cont)
print(contentls)
##for each in contentls:
## f = open("1.txt", ‘r‘, ‘utf-8‘)
## f.write(each)
#### print(each)
## f.close()
## print(‘#‘)
##fo=open(‘1.txt‘,‘r‘)
##content=fo.read()
##
content=str(contentls)
words=jieba.lcut(content)
ls=[]
counts={}
for word in words:
ls.append(word)
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(10):
word , count = items[i]
print ("{:2}".format(word,count))
#词云制作
from wordcloud import WordCloud
import matplotlib.pyplot as plt
cy = WordCloud(font_path=‘msyh.ttc‘).generate(content)
plt.imshow(cy, interpolation=‘bilinear‘)
plt.axis("off")
plt.show()
#excel导出、数据库存储
import re
import pandas
import sqlite3
itemtotal=[]
for i in range(2,3):
listurl=‘http://www.cbdio.com/node_2568.htm‘
itemtotal.extend(getOnePage(listurl))
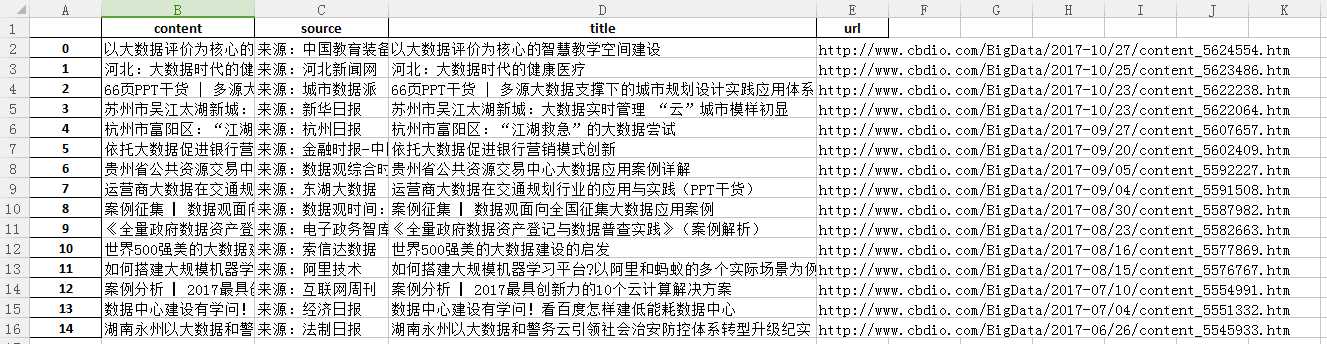
df =pandas.DataFrame(itemtotal)
df.to_excel(‘BigDataItems.xlsx‘)
with sqlite3.connect(‘BigDataItems.sqlite‘) as db:
df.to_sql(‘BigDataItems‘,con=db)
print(‘输出成功!!‘)
上一篇:爬取房天下整个网站房产数据。。。
下一篇:在线编辑前端代码的网站
文章标题:一个完整的大作业--‘’数据观”官方网站数据爬取
文章链接:http://soscw.com/index.php/essay/85869.html